前置配置
vm设置


虚拟机创建(hadoop1,hadoop2,hadoop3)

在安装过程中推荐设置root用户密码为1234方面后续操作


linux前置配置(三个机器都要设置)
1.设置主机名
以hadoop3为例
hostnamectl set-hostname hadoop3
2.设置固定ip
vim /etc/sysconfig/network-scripts/ifcfg-ens33


hadoop1 192.168.88.201
hadoop2 192.168.88.202
hadoop3 192.168.88.203
最后执行
service network restart
刷新网卡
3.工具连接(三个机器都要设置)



4.主机映射
windows:
C:\Windows\System32\drivers\etc
修改这个路径下的hosts文件


推荐使用vscode打开可以修改成功
linux:(三个机器都要设置)
vim /etc/hosts

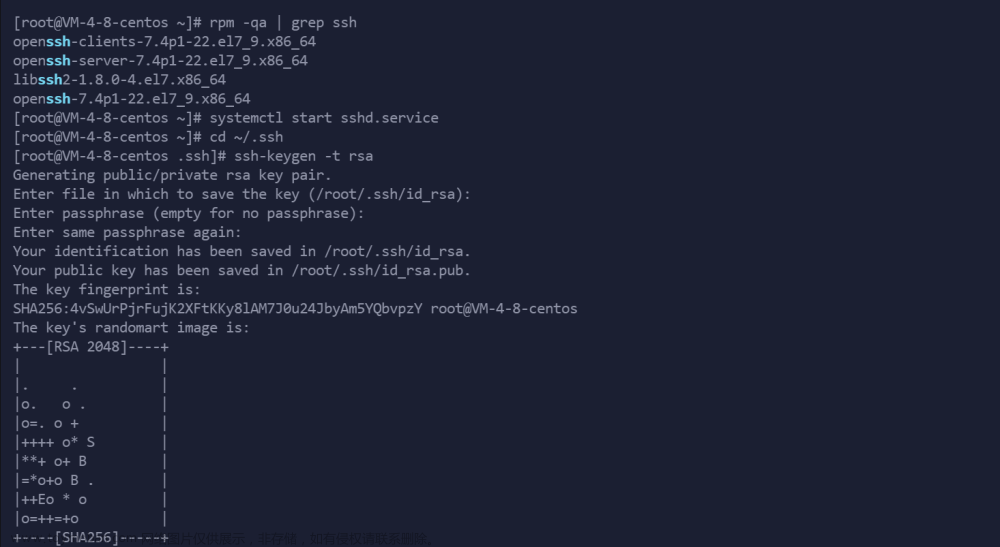
5.配置SSH免密登录(三个机器都要设置)
root免密
1.在每一台机器都执行:ssh-keygen -trsa -b 4096 ,一路回车到底即可

2.在每一台机器都执行:
ssh-copy-id hadoop1
ssh-copy-id hadoop2
ssh-copy-id hadoop3

hadoop免密
创建hadoop用户并配置免密登录
1.在每一台机器执行:useradd hadoop,创建hadoop用户
2.在每一台机器执行:passwd hadoop,设置hadoop用户密码为1234

3.在每一台机器均切换到hadoop用户:su - hadoop,并执行ssh-keygen -trsa -b 4096,创建ssh密钥

4.在每一台机器均执行
ssh-copy-id hadoop1
ssh-copy-id hadoop2
ssh-copy-id hadoop3
6.关闭防火墙和SELinux(三个机器都要设置)
1:
systemctl stop firewalld
systemctl disable firewalld

2.
vim /etc/sysconfig/selinux

设置好输入 init 6 重启

3.
以下操作在三台Linux均执行
- 安装ntp软件
yum install -y ntp
- 更新时区
rm -f /etc/localtime;sudo ln -s /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
- 同步时间
ntpdate -u ntp.aliyun.com
- 开启ntp服务并设置开机自启
systemctl start ntpd
systemctl enable ntpd

三台创建快照1

环境配置
1、jdk1.8 Java Downloads | Oracle
2、hadoop-3.3.6 Apache Hadoop
3、hbase-2.5.5.hadoop3x Index of /dist/hbase/2.5.5 (apache.org)
4、zookeeper-3.8.3 Apache ZooKeeper
重点:以下配置都是在root用户下进行配置后续会给对应的hadoop用户权限
推荐一口气配置完在进行给予权限和进行配置文件的刷新,以及最后的分发


jdk
创建文件夹,用来部署JDK,将JDK和Tomcat都安装部署到:/export/server 内
cd /
mkdir export
cd export
mkdir server


解压缩JDK安装文件
tar -zxvf jdk-8u321-linux-x64.tar.gz -C /export/server
配置JDK的软链接

配置JAVA_HOME环境变量,以及将$JAVA_HOME/bin文件夹加入PATH环境变量中
vim /etc/profile
export JAVA_HOME=/export/server/jdk
export PATH=$PATH: $JAVA_HOME/bin

生效环境变量
source /etc/profile
删除系统自带的java程序
rm -f /usr/bin/java
软链接我们自己的java
ln -s /export/server/jdk/bin/java /usr/bin/java
执行验证

分发
hadoop2,3先创建文件夹

hadoop分发
cd /export/server/
scp -r jdk1.8.0_321/ hadoop2:`pwd`
scp -r jdk1.8.0_321/ hadoop3:`pwd`
cd /etc
scp -r profile hadoop2:`pwd`
scp -r profile hadoop3:`pwd`
hadoop2,3
source /etc/profile
rm -f /usr/bin/java
ln -s /export/server/jdk/bin/java /usr/bin/java

hadoop
上传和解压

cd /export/server
tar -zxvf hadoop-3.3.6.tar.gz
ln -s hadoop-3.3.6 hadoop

hadoop配置
worksers
hadoop1
hadoop2
hadoop3

hdfs-site.xml
<property>
<name>dfs.namenode.http-address</name>
<value>0.0.0.0:9870</value>
<description> The address and the base port where the dfs namenode web ui will listen on.
</description>
</property>
<property>
<name>dfs.datanode.data.dir.perm</name>
<value>700</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/data/nn</value>
</property>
<property>
<name>dfs.namenode.hosts</name>
<value>hadoop1,hadoop2,hadoop3</value>
</property>
<property>
<name>dfs.blocksize</name>
<value>268435456</value>
</property>
<property>
<name>dfs.namenode.handler.count</name>
<value>100</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/data/dn</value>
</property>
core-site.xml
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop1:8020</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
hadoop-env.sh
export JAVA_HOME=/export/server/jdk
export HADOOP_HOME=/export/server/hadoop
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_LOG_DIR=$HADOOP_HOME/logs
yarn-site.xml
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop1:19888/jobhistory/logs</value>
<description></description>
</property>
<property>
<name>yarn.web-proxy.address</name>
<value>hadoop1:8089</value>
<description>proxy server hostname and port</description>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description>Configuration to enable or disable log aggregation</description>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/tmp/logs</value>
<description>Configuration to enable or disable log aggregation</description>
</property>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop1</value>
<description></description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
<description></description>
</property>
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/nm-local</value>
<description>Comma-separated list of paths on the local filesystem where intermediate data is written.</description>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/data/nm-log</value>
<description>Comma-separated list of paths on the local filesystem where logs are written.</description>
</property>
<property>
<name>yarn.nodemanager.log.retain-seconds</name>
<value>10800</value>
<description>Default time (in seconds) to retain log files on the NodeManager Only applicable if log-aggregation is disabled.</description>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>Shuffle service that needs to be set for Map Reduce applications.</description>
</property>
<!-- 是否需要开启Timeline服务 -->
<property>
<name>yarn.timeline-service.enabled</name>
<value>true</value>
</property>
<!-- Timeline Web服务的主机,通过8188端⼝访问 -->
<property>
<name>yarn.timeline-service.hostname</name>
<value>hadoop1</value>
</property>
<!-- 设置ResourceManager是否发送指标信息到Timeline服务 -->
<property>
<name>yarn.system-metrics-publisher.enabled</name>
<value>false</value>
</property>
mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description></description>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop1:10020</value>
<description></description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop1:19888</value>
<description></description>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/data/mr-history/tmp</value>
<description></description>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/data/mr-history/done</value>
<description></description>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=$HADOOP_HOME</value>
</property>
环境变量配置
vim /etc/profile
export HADOOP_HOME=/export/server/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin

分发hadoop到 主机2,3
发送hadoop
cd /export/server/
scp -r hadoop-3.3.6/ hadoop2:`pwd`
scp -r hadoop-3.3.6/ hadoop3:`pwd`
发送环境变量
cd /etc
scp -r profile hadoop2:`pwd`
scp -r profile hadoop2:`pwd`
其他设置
hadoop2,3分别创建软连接
cd /export/server/
ln -s hadoop-3.3.6/ hadoop

刷新环境变量
source /etc/peorfile
hadoop version

hadoop权限配置
主机 123 都执行: 以 root 权限 给 hadoop 用户配置相关权限
mkdir -p /data/nn
mkdir -p /data/dn
chown -R hadoop:hadoop /data
chown -R hadoop:hadoop /export

创建快照2
格式化与启动
1.切换用户hadoop
su - hadoop
2.进行格式化
hdfs namenode -format
3.启动!!!
一键启动:
start-all.sh
分开启动:
start-dfs.sh
start-yarn.sh

查看网页


zookeeper
上传与解压

cd /export/server/
tar -zxvf apache-zookeeper-3.9.1-bin.tar.gz
ln -s apache-zookeeper-3.9.1-bin zookeeper
rm -rf apache-zookeeper-3.9.1-bin.tar.gz

配置
cd /export/server/zookeeper/conf/
cp zoo_sample.cfg zoo.cfg
//修改 zoo.cfg 配置文件,将 dataDir=/data/zookeeper/data 修改为指定的data目录
vim zoo.cfg
dataDir=/export/server/zookeeper/zkData
server.2=hadoop1:2888:3888
server.1=hadoop2:2888:3888
server.3=hadoop3:2888:3888

cd ..
mkdir zkData
vim myid


分发和环境变量
环境变量
vim /etc/profile
export ZOOKEEPER_HOME=/export/server/zookeeper
export PATH=$PATH:$ZOOKEEPER_HOME/bin

分发
cd /etc
scp -r profile hadoop2:`pwd`
scp -r profile hadoop3:`pwd`
cd /export/server/
scp -r apache-zookeeper-3.9.1-bin/ hadoop2:`pwd`
scp -r apache-zookeeper-3.9.1-bin/ hadoop3:`pwd`
hadoop2,3创建软连接
ln -s apache-zookeeper-3.9.1-bin/ zookeeper
hadoop2,3修改内容
cd /export/server/zookeeper/zkData/

hadoop1 修改为2
hadoop2 修改为1
hadoop3 修改为3

刷新配置文件
source /etc/profile
重新给权限
chown -R hadoop:hadoop /export
启动(三个机器都执行)
su - hadoop
bin/zkServer.sh start
查看状态
bin/zkServer.sh status

hbase
上传和解压

tar -zxvf hbase-2.5.5-hadoop3-bin.tar.gz
ln -s hbase-2.5.5-hadoop3 hbase
rm -rf hbase-2.5.5-hadoop3-bin.tar.gz

配置
cd /export/server/hbase/conf/
mkdir -p /data/hbase/logs
hbase-env.sh
export JAVA_HOME=/export/server/jdk
export HBASE_MANAGES_ZK=false
regionservers

backup-master
vim backup-master

hbase-site.xml
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop1,hadoop2,hadoop3</value>
</property>
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop1:8020/hbase</value>
</property>
<property>
<name>hbase.wal.provider</name>
<value>filesystem</value>
</property>
分发和权限以及环境变量
环境变量
vim /etc/profile
export HBASE_HOME=/export/server/hbase
export PATH=$PATH:$HBASE_HOME/bin

分发
cd /export
scp -r hbase-2.5.5-hadoop3/ hadoop2:`pwd`
scp -r hbase-2.5.5-hadoop3/ hadoop3:`pwd`
hadoop2,3分别创建软连接
ln -s hbase-2.5.5-hadoop2/ hbase
ln -s hbase-2.5.5-hadoop3/ hbase
cd /etc
scp -r profile hadoop2:`pwd`
scp -r profile hadoop3:`pwd`
source /etc/proflie
权限(都执行)
chown -R hadoop:hadoop /export
chown -R hadoop:hadoop /data
启动
su - hadoop
start-hbase
 文章来源:https://www.toymoban.com/news/detail-770698.html
文章来源:https://www.toymoban.com/news/detail-770698.html
 文章来源地址https://www.toymoban.com/news/detail-770698.html
文章来源地址https://www.toymoban.com/news/detail-770698.html
到了这里,关于Hadoop3.3.6安装和配置hbase-2.5.5-hadoop3x,zookeeper-3.8.3的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!