一.邻接表的存在意义
回忆邻接矩阵的顺序存储结构,其内存空间预先分配,容易导致空间的溢出或者浪费。为了使增减结点方便,提高空间利用效率,引入链式存储法——邻接表。
二.邻接表的存储结构
邻接表的组成分为表头结点表与边表,如下图所示:

由图可见,每一个边表(单链表)的表头结点存放在表头结点中。
存储结构分析
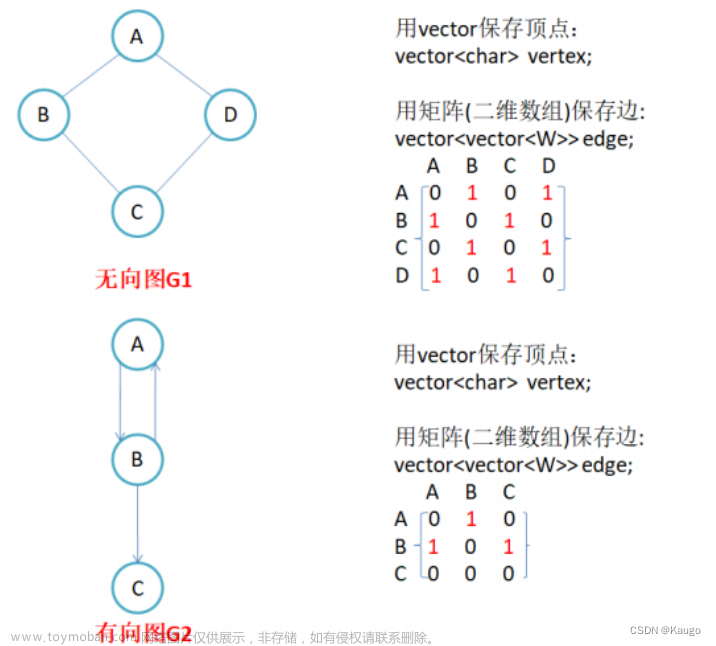
表头结点表采用顺序存储结构,数组的下标代表该顶点的编号。该表包含数据域data(如顶点信息)以及指针域firstarc,其指针域指向第一个与之邻接的顶点,若没有邻接点,则该指针置空,因此初始化时需将全部的顶点指针域置空。
边表顾名思义采取链式存储结构,实际上是一个单链表。边链表中的结点包含邻接点域(adjvex),数据域(info)以及链域nextarc。其中,邻接点域指示与顶点v相邻接的点在图中的位置(表头结点表数组的下标位置);数据域指示该边的信息,如权值;链域指示下一个与顶点v相邻接的点。
存储结构如图所示:

无向图的邻接表示意图:

特点:1.表头结点存储顶点数据以及单链表的表头结点;
2.单链表的结点链接方式不唯一,取决于算法的设计以及边的输入顺序;
3.单链表的最后一个nextarc指向NULL。
存储结构的优缺点
优点:
便于增加或者删除单链表中的结点
方便统计边数,只需要依次扫描各个单链表中的结点个数,计算其总和。
空间利用效率高。若存储顶点数为n,边数为e的无向图或者无向网,那么空间复杂度为O(n+2*e);若存储顶点数为n,边数为e的有向图或者有向网,那么空间复杂度为O(n+e)。
方便统计顶点的出度,只需要扫描该顶点所在单链表的结点个数
缺点:
难以判断两个顶点之间是否有边的存在;
对于有向图或网而言,难以统计顶点的入度,需要扫描其他顶点是否与该顶点相链接,时间复杂度很高O(n);若为了方便统计顶点的入度,可以采用逆邻接表的存储结构,与邻接表类似,只是单链表的邻接点域存储该弧尾顶点。
三.代码实现——邻接表的创建
以无向网为例,有向图或网的创建方式与之类似。
需要注意的是,以下顶点编号将从0开始。
数据类型定义
//文件名为:ALGraph.h
#pragma once
#include<iostream>
using namespace std;
//规定最大顶点数
#define Maxvex 100
//定义顶点的数据域类型
typedef char VexType;
//定义边的数据域
typedef int OtherInfo;
//定义边表的数据类型
typedef struct ArcNode {
int adjvex; //该边所指向点所在图中的位置
OtherInfo Info; //存储边的数据
struct ArcNode* nextarc; //指向顶点的下一个邻接点
}ArcNode;
//定义表头结点表的数据类型
typedef struct VexNode {
VexType data; //顶点的数据域
struct ArcNode* firstarc; //指向第一个邻接点
}VexNode,AList[Maxvex];
//定义图的数据类型
typedef struct ALGraph {
int vexnum, arcnum;//顶点与边的个数
AList vertices; //表头结点表类型
}ALGraph;
算法实现
//文件名为:ALGraph.cpp
#include"ALGraph.h"
//找顶点函数
int Findvex(const ALGraph& G, const VexType& v)
{
for (int i = 0;i < G.vexnum;i++)
{
if (v == G.vertices[i].data)
{
return i;
}
}
//表示没有找到
return -1;
}
//创建函数的定义
bool CreateUDN(ALGraph& G)
{
//输入顶点与边的个数
cin >> G.vexnum >> G.arcnum;
if (G.vexnum > Maxvex|| G.vexnum < 1)
{
cout << "输入有误,请重新创建" << endl;
return false;
}
//输入顶点的数据域,注意顶点编号从下标0开始
//并将指针域初始化
for (int i = 0;i < G.vexnum;i++)
{
cin >> G.vertices[i].data;
G.vertices[i].firstarc = NULL;
}
//输入边的数据
for (int i = 0;i < G.arcnum;i++)
{
//输入一条边依附的两个顶点,通过其数据域找到该顶点的下标编号
VexType v1, v2;
OtherInfo w; //边的信息
cin >> v1 >> v2 >> w;
int j = Findvex(G, v1);
int k = Findvex(G, v2);
//判断合法性
if (j == -1 || k == -1)
{
i--;
continue;
}
//链接顶点v1与v2
//v1指向v2
ArcNode* p1 = new ArcNode;
p1->adjvex = k;
p1->Info = w;
p1->nextarc = G.vertices[j].firstarc;
G.vertices[j].firstarc = p1;
//v2指向v1
ArcNode* p2 = new ArcNode;
p2->adjvex = j;
p2->Info = w;
p2->nextarc = G.vertices[k].firstarc;
G.vertices[k].firstarc = p2;
}
//创建成功
}测试
文件名:test.cpp
#include"ALGraph.h"
//创建无向网G3并且遍历
void test02()
{
ALGraph G;
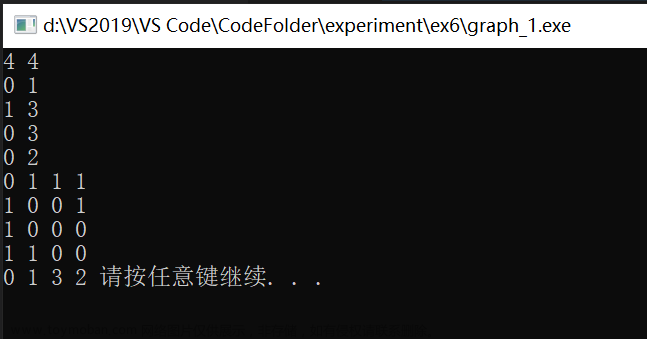
cout << "输入图的数据:>" << endl;
CreateUDN(G);
cout << "顶点链接情况;>" << endl;
for (int i = 0;i < G.vexnum;i++)
{
ArcNode* p = G.vertices[i].firstarc;
printf("%d", i);
while (p)
{
int k = p->adjvex;
printf("->%d", k);
p = p->nextarc;
}
printf("\n");
}
}
int main()
{
test02();
return 0;
}输入G3的数据,输出顶点连接情况:

对无向图、有向图与有向网的存储
其实,存储三者的方式与存储无向网类似。
对于无向图而言,由于无需关心边的信息,在上述代码实现中删除OtherInfo Info类型即可;
对于有向图而言,同理删除OtherInfo Info类型,另外在确认两个依附顶点v1与v2后,若想创建<v1,v2>只需要处理G.vertices[v1]的边结点信息。
对于有向网而言,在创建有向图的基础上,增加OtherInfo Info类型以及相关操作。文章来源:https://www.toymoban.com/news/detail-771162.html
我的感悟
邻接表是线性表的一种推广,是一种顺序存储结构嵌套链式存储结构的数据存储结构。在本案例中,其顺序存储结构成分在于表头结点表,其空间内存预先分配,大小保持不变;其链式存储结构成分在于边表。由于单链表的表头结点存放在一维数组——表头结点表中,故谓之顺序存储结构嵌套链式存储结构。这种存储方式兼容了两者的优点,比如通过数组下标可以随机访问顶点信息。再者,在顶点个数固定的情况下,方便增删顶点间边的个数,只需要在相应的表头结点前插入新结点。当然,也继承了两者的缺点,比如表头结点表在已满的情况下无法增加新的顶点,而单链表的边信息又无法随机访问。文章来源地址https://www.toymoban.com/news/detail-771162.html
到了这里,关于图的存储结构——邻接表的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!