1.引言
在过去几十年中,房地产市场一直是全球经济的重要组成部分。房地产不仅是个人家庭的主要投资渠道,还对国家经济有着深远的影响。特别是,房地产市场的价格波动对金融市场稳定和宏观经济政策制定产生了重要影响。因此,理解和预测房地产市场的价格走势一直是研究人员和政策制定者关注的焦点。 然而,房地产市场的价格走势是一个复杂而多变的问题,受到多种因素的影响,包括经济周期、政策变化、地理位置和市场供需等。因此,需要开展深入的研究来解析这些因素如何影响房价,以提供有关房地产市场未来走势的重要见解。
爬取的房价信息网站为房天下(【郑州租房网_郑州租房信息|房屋出租】- 房天下 (fang.com))。
2.数据爬取
2.1导入必要的库:
-
requests:用于发送HTTP请求以获取网页内容。 -
BeautifulSoup:用于解析HTML页面。 -
numpy:用于处理数值数据。 -
re:用于正则表达式匹配。 -
time:用于生成随机延迟,以避免频繁访问网站。 -
random:用于生成随机延迟时间。 -
pandas:用于数据处理和存储。
import requests
from bs4 import BeautifulSoup
import numpy as np
import re
import time
import random2.2 定义请求头部信息headers,模拟浏览器请求,包括User-Agent和Cookie信息,以便访问网站。
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.67',
'Referer':'https://zz.zu.fang.com/',
'Cookie':'改成自己的'
}2.3 创建一个空的Pandas DataFrame对象data,用于存储爬取到的数据,包括标题、租房方式、布局、面积、朝向、价格和城市。
data = pd.DataFrame(columns=['标题','租房方式','布局','面积','朝向','价格','城市'])2.4 创建一个包含城市代码的列表bar,并定义一个城市名和城市代码的字典city_dict,用于城市名的映射。
bar = ['sh','gz','sz','tj','cd','cq','wuhan','suzhou','hz','nanjing','jn']
# 中英文城市名对应关系字典
city_dict = {
'sh': '上海',
'gz': '广州',
'sz': '深圳',
'tj': '天津',
'cd': '成都',
'cq': '重庆',
'wuhan': '武汉',
'suzhou': '苏州',
'hz': '杭州',
'nanjing': '南京',
'jn': '济南'
}2.5 使用循环遍历城市列表bar,并在每个城市上执行以下操作:
- 构建URL以获取特定城市的租房信息页面。
- 发送HTTP请求以获取页面内容。
- 使用Beautiful Soup解析页面HTML。
- 使用正则表达式提取标题、租房方式、布局、面积、朝向和价格等信息。
- 将提取的数据添加到Pandas DataFrame中。
- 在每次数据爬取后,生成随机的延迟时间,以避免对网站造成过多请求,然后使用
time.sleep()函数来暂停程序执行
for j in bar:
print(f'正在爬取 {city_dict.get(j)}')
for i in range(50):
url_new = f'https://{j}.zu.fang.com/house/i3{i+2}/'
response1 = requests.get(url_new,headers=headers)
text1 = response1.text
title = re.findall('target="_blank" title="(.*?)">', text1)
zhutype = re.findall('<p class="font15 mt12 bold">\r\n (.*?)<span class="splitline">', text1)
inSale = re.findall('<span class="splitline">|</span>(.*?)<span class="splitline">|</span>.*?�O<span', text1)
buju = []
mianji = []
for i in inSale:
if '室' in i or '户' in i:
buju.append(i)
if '�' in i:
mianji.append(i[:-2])
zaox = re.findall('s="splitline">|</span>(.*?)\r\n </p>', text1)
zaox_list = []
for i in zaox:
if len(i)>2:
zaox_list.append(i.split('</span>')[-1])
jiage = re.findall('<span class="price">(.*?)</span>', text1)
for i in range(len(title)):
try:
data.loc[len(data)] = [title[i],zhutype[i],buju[i],mianji[i],zaox_list[i],jiage[i],city_dict.get(j)]
except:
# 捕获所有类型的异常
pass
# 生成随机的延迟时间
delay = random.uniform(0.1, 0.5)
# 暂停程序
time.sleep(delay)2.6 最后,将所有爬取到的数据存储到CSV文件房天下数据.csv中,使用data.to_csv()方法。
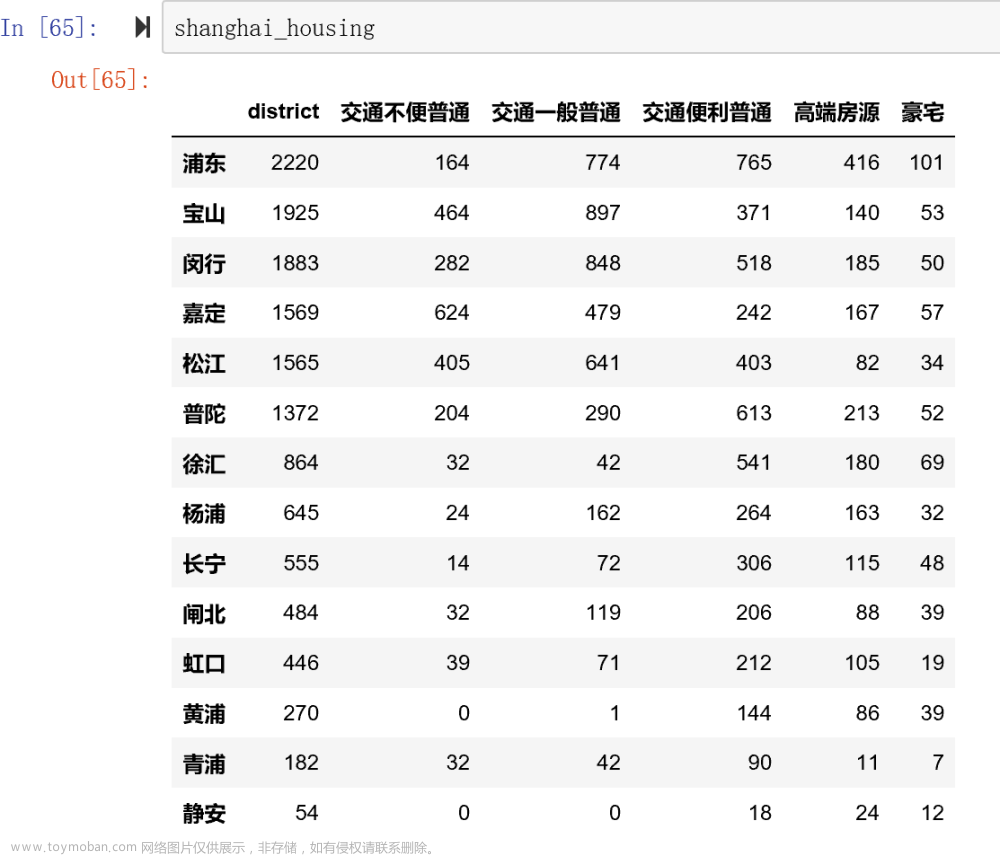
data.to_csv('./房天下数据.csv') 最终爬取了 31474 条数据,数据示例如下:

3.数据可视化分析
3.1 数据导入预处理
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
plt.rcParams['font.sans-serif']=['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] =False
data = pd.read_csv('./房天下数据.csv')
data['面积'] = data['面积'].astype('int')
data['价格'] = data['价格'].astype('int')
3.2 饼图 - 租房方式数量比较
df =data
# 计算每种租房方式的数量
rental_counts = df['租房方式'].value_counts()
# 设置饼图
fig, ax = plt.subplots(figsize=(8, 6))
colors = ['#ff9999', '#66b3ff', '#99ff99', '#ffcc99']
explode = (0.1, 0, 0, 0) # 突出显示第一个扇区
# 创建饼图
ax.pie(rental_counts, labels=rental_counts.index, autopct='%1.1f%%',
startangle=30, colors=colors, explode=explode)
# 添加标题和图例
ax.set_title('租房方式数量比较', fontsize=16)
ax.legend(loc='upper right')
# 显示图表
plt.show()
3.3 核密度估计图 - 房屋面积分布
plt.figure(figsize=(10, 6))
sns.kdeplot(data=df, x='面积', fill=True, palette='Blues')
plt.title('房屋面积分布', fontsize=16)
plt.xlabel('面积', fontsize=12)
plt.ylabel('密度', fontsize=12)
plt.show()
3.4 柱状图 - 不同朝向的房屋数量比较
# 计算每个朝向的房屋数量
orientation_counts = df['朝向'].value_counts()[:6]
# 设置柱状图
plt.figure(figsize=(10, 6))
colors = ['#ff9999', '#66b3ff', '#99ff99', '#ffcc99']
orientation_counts.plot(kind='bar', color=colors)
# 添加标题和轴标签
plt.title('不同朝向的房屋数量比较', fontsize=16)
plt.xlabel('朝向', fontsize=12)
plt.ylabel('数量', fontsize=12)
plt.xticks(rotation=45, fontsize=10)
# 显示图表
plt.show()
3.5 盒图 - 房屋价格分布
plt.figure(figsize=(10, 6))
sns.boxenplot(data=df, y='价格', color='purple')
plt.title('房屋价格分布', fontsize=16)
plt.ylabel('价格', fontsize=12)
plt.show()
3.6 条形图 - 不同城市的房屋价格对比
plt.figure(figsize=(12, 6))
sns.barplot(data=df, x='城市', y='价格', palette='coolwarm')
plt.title('不同城市的房屋价格对比', fontsize=16)
plt.xlabel('城市', fontsize=12)
plt.ylabel('价格', fontsize=12)
plt.xticks(rotation=45, fontsize=10)
plt.show()
3.7 不同布局类型的房屋数量比较
# 计算每种布局类型的数量
layout_counts = df['布局'].value_counts().sort_values(ascending=True)[-10:]
# 设置水平条形图
plt.figure(figsize=(10, 8))
colors = ['#66b3ff'] * len(layout_counts) # 使用单一颜色
plt.barh(layout_counts.index, layout_counts, color=colors)
# 添加标题和轴标签
plt.title('不同布局类型的房屋数量比较', fontsize=16)
plt.xlabel('数量', fontsize=12)
plt.ylabel('布局类型', fontsize=12)
# 调整刻度标签的字体大小
plt.xticks(fontsize=10)
plt.yticks(fontsize=10)
# 显示图表
plt.show()
3.8 面积与价格的关系图文章来源:https://www.toymoban.com/news/detail-771404.html
# 提取面积和价格的数据
area = df['面积']
price = df['价格']
# 设置散点图
plt.figure(figsize=(10, 6))
plt.scatter(area, price, alpha=0.6, color='b', edgecolors='k')
# 添加标题和轴标签
plt.title('面积与价格的关系图', fontsize=16)
plt.xlabel('面积', fontsize=12)
plt.ylabel('价格', fontsize=12)
# 显示图表
plt.show() 文章来源地址https://www.toymoban.com/news/detail-771404.html
文章来源地址https://www.toymoban.com/news/detail-771404.html
到了这里,关于python 房天下网站房价数据爬取与可视化分析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!