为什么要看这篇
这篇是老师发的,主要是用来解决遥感显著性检测的边缘问题
基本信息
| 期刊 | IEEE TRANSACTIONS ON GEOSCIENCE AND REMOTE SENSING |
|---|---|
| 年份 | 2023 |
| 论文地址 | https://ieeexplore.ieee.org/abstract/document/10217013 |
| 代码地址 | https://github.com/hilitteq/CRNet.git |
标题
CRNet:一种基于网格增强重构的光学遥感图像显著目标检测网络
目前存在的问题
- 除了它们的尺寸差异之外,这些目标由于拍摄距离而具有不同的目标尺度大小
- 小物体在整个图像中占较少的像素,使得在网络训练期间更难以学习。而且,网络模型在学习ORSIs的过程中面向大对象,而小对象容易被忽略,导致检测效果不佳
- ORSIs覆盖的视场范围大,背景信息复杂多样,对显著目标的检测会产生很强的干扰
改进
- 对于浅层特征,我们创建了一个通道增强模块(CEM),该模块结合了通道注意(CA)机制和局部通道交互。这个模块有助于建立边界细节,同时减少复杂背景和阴影的干扰
- 对于语义更丰富的深层特征,我们提出了重定义特征模块(redefined feature module, RFM),通过重构全局上下文语义信息来实现显著性目标的完整检测
- 解码器模块的融合过程以逐步恢复分辨率的方式推断出显著目标,结合定位和细节填充完成检测任务
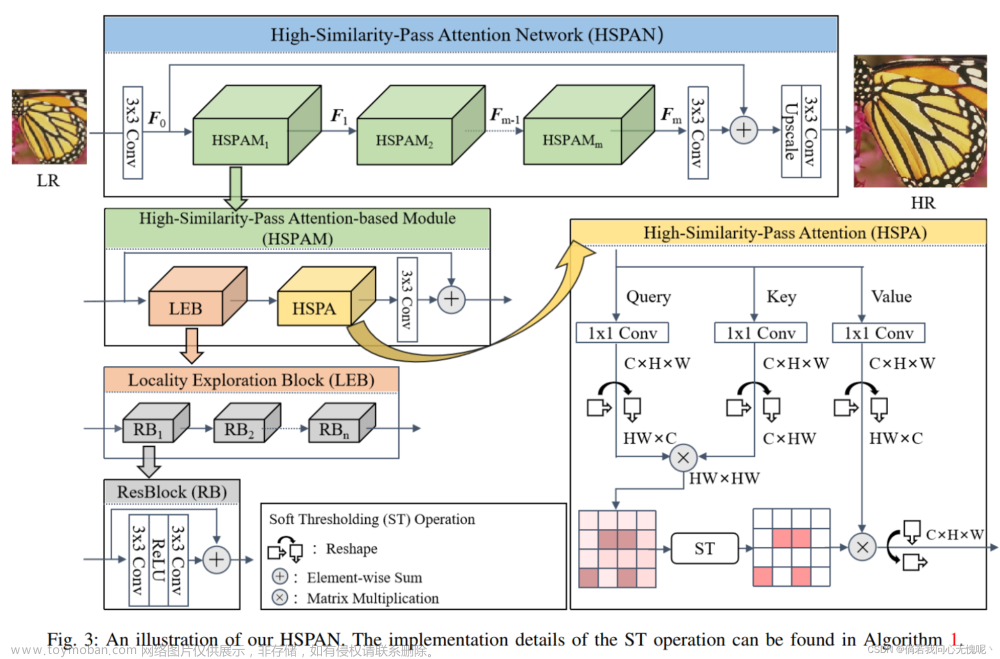
网络结构

Feature-Enhanced Encoder(功能增强的编码器)
首先,我们将浅层特征f1和f2输入CEM。然后,通过CA机制和群卷积实现了去除冗余背景信息和精细表达前景细节的功能。最后生成信道增强特征F1和F2。对于深度特征f3 - f5,采用RFM进行特征结构变换。利用目标像素和通道之间的语义相关性,生成重构增强特征F3-F5
CEM(Channel Enhance Module)
浅层特征具有较高的空间分辨率,包含更详细的信息,有利于不同尺度下显著性目标的恢复,尤其是小目标。
RFM(Refined Feature Module)
同一物品的多个目标具有相同的视觉和语义特征。在识别出一种目标后,相似的语义关联有助于检测出同一类型的目标。构建不同空间区域之间的相关性有助于检测结构完整的目标,基于图的模型可以有效地推断上下文语义相关性。因此,我们可以通过图变换来增强像素之间的语义相关性,定位目标位置,聚合目标结构。
Progressive Fusion Decoder(渐进式融合解码器)
损失函数
BCE+IOU
训练
ORSSD,EORSSD,ORSI-4199,初始学习率5e-5,最小学习率5e-6,epoch为50
测试
ORSSD,EORSSD文章来源:https://www.toymoban.com/news/detail-771618.html
我的总结
总的来说,浅层特征和深层特征走的路径不同文章来源地址https://www.toymoban.com/news/detail-771618.html
到了这里,关于论文阅读——CRNet: Channel-Enhanced Remodeling-Based Network for Salient Object Detection in Optical的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!