简介
-
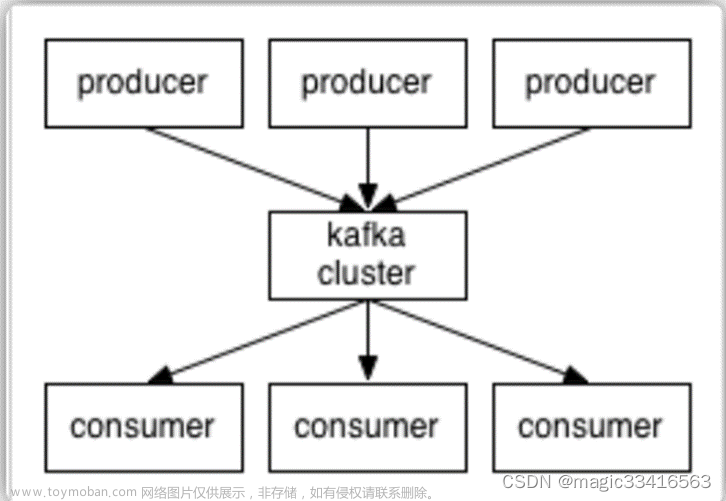
Kafka是一款分布式的、去中心化的、高吞吐低延迟、订阅模式的消息队列系统。 - 同
RabbitMQ一样,Kafka也是消息队列。不过RabbitMQ多用于后端系统,因其更加专注于消息的延迟和容错。 -
Kafka多用于大数据体系,因其更加专注于数据的吞吐能力。 -
Kafka多数都是运行在分布式(集群化)模式下,所以课程将以3台服务器,来完成Kafka集群的安装部署。
安装
前提条件:
- 确保已经跟随前面的安装教程,安装并部署了
JDK和Zookeeper服务
Kafka的运行依赖JDK环境和Zookeeper请确保已经有了JDK环境和Zookeeper
没安装的可以看完之前的博客:
Linux系统安装部署Tomcat(超详细操作演示)
Zookeeper集群安装部署(超详细操作演示)
1、【在node1操作】 下载并上传Kafka的安装包
# 下载安装包
wget http://archive.apache.org/dist/kafka/2.4.1/kafka_2.12-2.4.1.tgz
也可以下载好,再上传:
rz

查看是否上传成功:

2 、【在node1操作】 解压
# 此文件夹如果不存在需先创建
mkdir -p /export/server
# 解压
tar -zxvf kafka_2.12-2.4.1.tgz -C /export/server/

查看是否解压成功:
# 创建软链接
ln -s /export/server/kafka_2.12-2.4.1 /export/server/kafka

3、【在node1操作】 修改Kafka目录内的config目录内的server.properties文件
cd /export/server/kafka/config
vim server.properties

# 指定broker的id
broker.id=1

# 指定 kafka的绑定监听的地址
listeners=PLAINTEXT://node1:9092

按
Esc退出插入模式,输入/dirs搜索:
# 指定Kafka数据的位置
log.dirs=/export/server/kafka/data

按
Esc退出插入模式,输入/connect搜索:
# 指定Zookeeper的三个节点
zookeeper.connect=node1:2181,node2:2181,node3:2181

按
Esc退出插入模式,输入:wq保存退出。
4、【在node1操作】 将node1的kafka复制到node2和node3
cd /export/server
# 复制到node2同名文件夹
scp -r kafka_2.12-2.4.1 node2:`pwd`/

# 复制到node3同名文件夹
scp -r kafka_2.12-2.4.1 node3:$PWD

5、【在node2操作】
# 创建软链接
ln -s /export/server/kafka_2.12-2.4.1 /export/server/kafka

cd /export/server/kafka/config
vim server.properties
# 指定broker的id
broker.id=2
# 指定 kafka的绑定监听的地址
listeners=PLAINTEXT://node2:9092

按
Esc退出插入模式,输入:wq保存退出。
6、【在node3操作】
# 创建软链接
ln -s /export/server/kafka_2.12-2.4.1 /export/server/kafka

cd /export/server/kafka/config
vim server.properties
# 指定broker的id
broker.id=3
# 指定 kafka的绑定监听的地址
listeners=PLAINTEXT://node3:9092

按
Esc退出插入模式,输入:wq保存退出。
7、启动kafka
# 请先确保Zookeeper已经启动了
# 方式1:【前台启动】分别在node1、2、3上执行如下语句 (一般很少用!)
/export/server/kafka/bin/kafka-server-start.sh /export/server/kafka/config/server.properties
# 方式2:【后台启动】分别在node1、2、3上执行如下语句
nohup /export/server/kafka/bin/kafka-server-start.sh /export/server/kafka/config/server.properties 2>&1 >> /export/server/kafka/kafka-server.log &

8、验证Kafka启动
# 在每一台服务器执行
jps

测试Kafka能否正常使用
1、创建测试主题
# 在node1执行,创建一个主题
/export/server/kafka_2.12-2.4.1/bin/kafka-topics.sh --create --zookeeper node1:2181 --replication-factor 1 --partitions 3 --topic test
2、运行测试,请在FinalShell中打开2个node1的终端页面
# 打开一个终端页面,启动一个模拟的数据生产者
/export/server/kafka_2.12-2.4.1/bin/kafka-console-producer.sh --broker-list node1:9092 --topic test
# 再打开一个新的终端页面,在启动一个模拟的数据消费者
/export/server/kafka_2.12-2.4.1/bin/kafka-console-consumer.sh --bootstrap-server node1:9092 --topic test --from-beginning
 文章来源:https://www.toymoban.com/news/detail-771714.html
文章来源:https://www.toymoban.com/news/detail-771714.html
左边输入,右边能同步输出,就成功啦!文章来源地址https://www.toymoban.com/news/detail-771714.html
到了这里,关于Kafka集群安装部署(超详细操作演示)—— Linux的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!