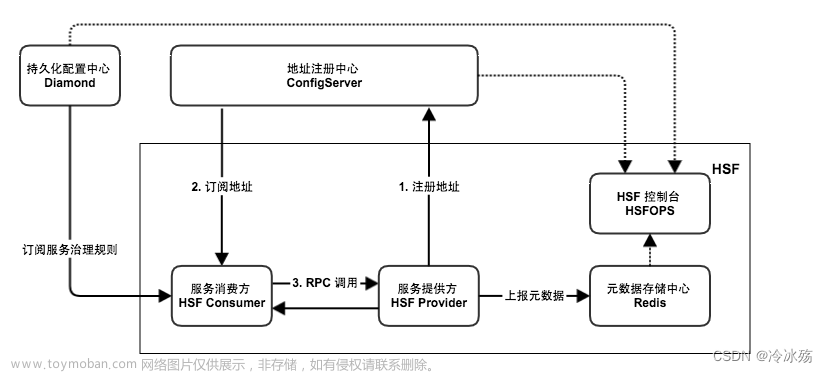
一、注册中心
策略:服务注册原理、注册中心结构、zookeeper的原理、几个注册中心的区别、分布式算法、分布式事务。
项目细节:服务注册、服务发现、服务注销、监听机制
-
介绍一下服务注册中心怎么做的?
(1)服务发现:
- 服务注册/反注册:保存服务提供者和服务调用者的信息
- 服务订阅/取消订阅:服务调用者订阅服务提供者的信息,最好有实时推送的功能
- 服务路由(可选):具有筛选整合服务提供者的能力。
(2)服务配置(不包括其它无关配置):
- 配置订阅:服务提供者和服务调用者订阅微服务相关的配置
- 配置下发(可选):主动将配置推送给服务提供者和服务调用者
(3)服务健康检测
- 检测服务提供者的健康情况
-
一个注册中心,至少需要具备哪些条件?
(项目中RPC服务注册中心需要注意什么?)
(如果让你设计一个服务注册中心,怎么设计?)
服务注册接口:服务提供者通过调用服务注册接口来完成服务注册。
服务反注册接口:服务提供者通过调用服务反注册接口来完成服务注销。
心跳汇报接口:服务提供者通过调用心跳汇报接口完成节点存活状态上报。
服务订阅接口:服务消费者通过调用服务订阅接口完成服务订阅,获取可用的服务提供者节点列表。
服务变更查询接口:服务消费者通过调用服务变更查询接口,获取最新的可用服务节点列表。
服务查询接口:查询注册中心当前注册了哪些服务信息。
服务修改接口:修改注册中心中某一服务的信息。
-
注册中心单机还是分布式的,其中一个挂了怎么办?一致性,可靠性怎么保证的?超时控制,加锁和管道支持并发,单机(考虑了多机情况
-
常用的服务注册中心, 注册中心的差异
-
为什么用Zookeeper做注册中心?(优点,与其他选型对比下)
(使用zookeeper有什么好处?)
(说一下zookeeper,为什么使用zookeeper,不选其他注册中心?)
(了解Nacos和Zookeeper的区别吗?)
(为什么不选择Redis作为注册中心?(zookeeper临时节点自动宕机自动清除))
(为什么要用Zookeeper(服务注册、发现))
(Zookeeper和Eureka分别是满足CAP中的哪些)
-
集群一般有几个节点,为什么?
5个,宕机后选举要大于一半成为leader。
-
socket过程中发生的系统调用
-
zookeeper服务发现
-
zookeeper服务容灾?zookeeper服务节点挂掉之后,怎么删除它?
容灾:在集群若干台故障后,整个集群仍然可以对外提供可用的服务。
一般配置奇数台去构成集群,以避免资源的浪费。
三机房部署是最常见的、容灾性最好的部署方案。
删除:使用临时节点,会话失效,节点自动清除。
-
Zookeeper有几种角色?
群首(leader),追随者(follower),观察者(observer)
-
CAP理论解释下?P是什么?
-
一致性(Consistency)多个副本之间的数据一致性
-
可用性(Availability)在合理规定的时间内,是否能返回一个明确的结果。
-
分区容错性(Partition tolerance)在分区故障下,仍然可以对外提供正常的服务。
一个分布式系统在以上三个特性中:最多满足其中的两个特性。
-
-
Zookeeper集群节点宕机了怎么发现剔除的?
发现:watcher机制
剔除:临时节点?
-
服务熔断和服务降级有什么区别?
**服务熔断:**如果某个目标服务调用慢或者有大量超时,此时,熔断该服务的调用,对于后续调用请求,不在继续调用目标服务,直接返回,快速释放资源。如果目标服务情况好转则恢复调用。
**服务降级:**当服务器压力剧增的情况下,根据当前业务情况及流量对一些服务和页面有策略的降级,以此释放服务器资源以保证核心任务的正常运行。
-
zookeeper原理?羊群效应,怎么解决,解决之后又有什么问题,又怎么解决,纯粹搞成了循环依赖了。zab协议,具体说来。
羊群效应:
-
ZAB算法讲一下(讲了ZAB是paxos的改版,Mysql是paxos、redis sentinel是raft、zookeeper是ZAB、ZAB的具体实现)
-
zk的分布式算法zab,如果选举的时候zxid都相同呢?(比较SID)
-
dubbo 怎么注册到zookeeper以及 dubbo 协议,zookeeper协议,
-
zookeeper的节点类型?(持久,临时,顺序)
-
分布式数据一致性协议都知道哪些(2PC 3PC Paxos)
-
Raft了不了解
-
分布式事务的几种解决方案(2PC,3PC,TCC,基于消息,然后顺带讲了一下优缺点) 分布式事务的几种方式吧(2pc、3pc、tcc、基于消息)以及区别
-
Zookeeper 是如何保证一致性的?
zookeeper 的一致性,为了防止单机挂掉,zookeeper维护了一个集群,实现自身的高可用。
重点回答zookeeper的ZAB协议
事务的顺序一致性:全局唯一事务ID,ZXID
-
你知道Zookeeper的分布式锁实现方式吗?(临时节点,如果服务器挂了,锁会自己消失)
-
ZooKeeper的作用?
项目答:注册中心。
扩展答:
1.数据发布/订阅
2.自动化的DNS服务
3.数据库复制处理
4.基于zookeeper分布式系统机器间的通信方式
5.命名服务
6.集群管理(监控、控制)
7.Master选举
8.分布式锁
9.分布式队列
-
zookeeper有什么特性,讲一下(临时节点、持久节点、ZAB)
-
服务下线还有没有别的实现方法(这就算引导了,结合前面的问题,使用临时节点)
-
zookeeper宕机与dubbo直连的情况?
zookeeper注册中心宕机–>dubbo直连,可以调服务
zookeeper宕机了,消费者可以通过本地缓存通信调提供者的服务
现象:zookeeper注册中心宕机,还可以消费dubbo暴露的服务。
原因:健壮性监控中心宕掉不影响使用,只是丢失部分采样数据 数据库宕掉后,注册中心仍能通过缓存提供服务列表查询,但不能注册新服务 注册中心对等集群,任意一台宕掉后,将自动切换到另一台 注册中心全部宕掉后,服务提供者和服务消费者仍能通过本地缓存通讯 服务提供者无状态,任意一台宕掉后,不影响使用 服务提供者全部宕掉后,服务消费者应用将无法使用,并无限次重连等待服务提供者恢复 -
任何一个请求(流量)过来都会打到注册中心么?(不会,第一次会,有本地缓存)
-
有一大批流量总是被打到一个实例上面,这个实例的兄弟实例分到的流量很少,怎么办?
(通过合理负载均衡)
-
有一个实例挂了怎么办?
(zookeeper心跳检测更新列表并利用watcher机制发给服务消费者)
-
注册中心怎么进行心跳检测
-
注册中心对于服务端掉线时怎么处理
(移出ip链表,发送给服务消费者,等待服务器上线,重新连接)
-
服务端用的哪个类监听的(ServerSocket)
-
自己实现的定时器是啥?
-
RPC心跳怎么实现的?
是服务端给服务注册中心心跳还是服务端给客户端心跳?
服务调用方怎么知道服务不可用了?
(zookeeper的心跳检测+更新ip列表+watcher发送给服务调用方):注册中心发送
(利用netty的IdleStateHandler实现心跳服务):客户端给服务端发送PING消息
-
怎么实现的类似本地调用?
本地知道类名+服务名,直接调用
-
如果是你如何设计一个nacos ,rpc如何调用。
-
如果注册中心服务器宕机怎么保证高可用?
高可用:通过设置减少系统不能提供服务的时间。
在zookeeper主要考虑***容灾和扩容***两方面提高高可用。
-
服务的地址怎么知道?(注册中心)
-
服务注册信息的拆分要怎么做?
-
服务注册中心的功能除了放在额外的服务器上实现还能放在哪里?怎么实现?
-
RPC服务注册、服务发现、服务注销怎么做的?
服务注册怎么进行服务注销监听?
RPC项目zookeeper怎么实现注册、发现的?(临时节点存储ip+端口+负载均衡策略)
-
了解过zookeeper的问题吗?
(崩溃恢复无法提供服务、写的性能瓶颈是一个问题、选举过程速度缓慢、无法进行有效的权限控制)
二、序列化与反序列化以及协议
JSON:
- JSON 进行序列化的额外空间开销比较大,对于大数据量服务这意味着需要巨大的内存和磁盘开销;
- JSON 没有类型,但像 Java 这种强类型语言,需要通过反射统一解决,所以性能不会太好(比如反序列化时先反序列化为String类,要自己通过反射还原)。
Kryo:
- 使用变长的int和long保证这种基本数据类型序列化后尽量小
- 需要传入完整类名或者利用 register() 提前将类注册到Kryo上,其类与一个int型的ID相关联,序列中只存放这个ID,因此序列体积就更小
- 不是线程安全的,要通过ThreadLocal或者创建Kryo线程池来保证线程安全
- 不需要实现Serializable接口
- 字段增、减,序列化和反序列化时无法兼容
- 必须拥有无参构造函数
Hessian:
- 使用固定长度存储int和long
- 将所有类字段信息都放入序列化字节数组中,直接利用字节数组进行反序列化,不需要其他参与,因为存的东西多处理速度就会慢点。
- 把复杂对象的所有属性存储在一个Map中进行序列化。所以在父类、子类存在同名成员变量的情况下,Hessian序列化时,先序列化子类,然后序列化父类,因此反序列化结果会导致子类同名成员变量被父类的值覆盖
- 需要实现Serializable接口
- 兼容字段增、减,序列化和反序列化
- 必须拥有无参构造函数
- Java 里面一些常见对象的类型不支持,比如:
- Linked 系列,LinkedHashMap、LinkedHashSet 等;
- Locale 类,可以通过扩展 ContextSerializerFactory 类修复;
- Byte/Short 反序列化的时候变成 Integer。
Protobuf:
- 序列化后体积相比 JSON、Hessian 小很多
- IDL 能清晰地描述语义,所以足以帮助并保证应用程序之间的类型不会丢失,无需类似XML 解析器;
- 序列化反序列化速度很快,不需要通过反射获取类型;
- 打包生成二进制流
- 预编译过程不是必须的
策略:几个序列化协议的区别以及优缺点、Kryo的原理和安全性、两个接口区别。
项目细节:在项目怎么定义序列化协议,怎么定义序列化相关的类以及项目序列化的细节,
-
序列化和反序列化有什么作用
(1)实现了数据的持久化:永久性保存对象,保存对象的字节序列到本地文件或者数据库中;
(2)序列化实现远程通:通过序列化以字节流的形式使对象在网络中进行传递和接收;
(3)通过序列化在进程间传递对象; -
Serializable和Externalizable懂吗?(不知道Externalizable)
1、Serializable序列化时不会调用默认的构造器,而Externalizable序列化时会调用默认构造器的!
2、Serializable:一个对象想要被序列化,它的类就要实现 此接口,这个对象的所有属性都可以被序列化和反序列化来保存、传递。
Externalizable:自定义序列化可以控制序列化的过程和决定哪些属性不被序列化。
3、使用Externalizable时,必须按照写入时的确切顺序读取所有字段状态。否则会产生异常。
-
serializable关键字的作用(实现原理)?几种序列化协议?ProtoBuff的优点?
-
序列化传输?
-
有没有阅读过序列化(Java Serialization、Fastjson)之后的数据
-
RPC 不同序列化协议了解吗?优缺点是?各种序列号协议的特点?序列化方式有哪几个,区别是什么,自己写过吗?
优点 缺点 Kryo 速度快,序列化后体积小 跨语言支持较复杂 Hessian 默认支持跨语言 较慢 Protostuff 速度快,基于protobuf 需静态编译 Protostuff-Runtime 无需静态编译,但序列化前需预先传入schema 不支持无默认构造函数的类,反序列化时需用户自己初始化序列化后的对象,其只负责将该对象进行赋值 Java 使用方便,可序列化所有类 速度慢,占空间 -
为什么选用ProtoBuff?
-
为什么选KRYO序列化?(面试官提示了压缩),java 的压缩算法
-
序列化怎么做的(序列化怎么实现)?Kryo原理了解吗?
-
你说到你自定义了一个简单协议,自定义的协议头里包括哪些内容,多少字节,各自的作用是什么(魔数,消息长度,请求id,消息类型)
-
由RPC项目问到了序列化反序列化,问到了对象有一个属性是对象引用,怎么序列化。
-
如何实现编解码及序列化?
-
那你这个序列化还是针对Java语言的,如何实现跨语言的序列化或者RPC框架?
Java
RPC框架要想跨语言,本质是在解决序列化/反序列化的跨语言问题
三、Netty
策略:BIO、NIO、AIO三者区别
1.TCP 的粘包的概念是对的吗(面试官:TCP 是面向字节流的,所以这个概念本身是一个伪概念,本身就是可以粘的。但是这种现象还是要解决的)
-
简述AIO、BIO、NIO的具体使用、区别及原理
-
BIO,NIO,AIO的痛点,怎么优化?
-
IO/NIO/AIO区别?介绍Reactor,介绍Proactor?
为什么BIO比NIO性能差?简单讲讲区别?
假设有100个连接,采用NIO的方式要服务端要分配几个线程,采用BIO的方式呢?
为啥要用异步IO不用多线程,不是一样可以加速吗?
-
说说你对Netty的认识?
-
NIO中Channel的作用
-
NIO的设计架构?JDK中NIO有哪些重要组件?
-
为什么选用Netty来做通信框架?还知道其他网络通信框架?
-
Netty怎么实现高性能的?Netty高性能主要依赖了哪些特性?Netty为什么快(基于NIO+零拷贝)Netty为啥效率高(零拷贝,线程模型)
-
netty bytebuf工作原理,和NIO里buffer区别?
-
除了Netty还知道哪些网络传输框架吗?
-
为什么大多数rpc框架都用netty(聊了下Netty的特点)?你为什么会用到Netty?
-
同步、异步调用方式的具体实现
-
Netty使用场景
-
Netty的线程模型
-
RPC过程网络上发生了什么
-
RPC多个请求是在一个连接完成的吗
-
Netty服务调用如何变成同步的?(不知道)(回答netty中的Reactor模型)
Netty异步编程怎么做的?
-
基于Netty实现通信,使用了哪些TCP优化参数?
你说网络通信使用的Netty,你都通过那些设置对Netty进行过调优(我表示Netty的bootstrap的option设置基本都是模仿Netty官方案例搞的,然后他问了我backlog是什么意思)
-
tcp粘包
粘包半包怎么解决的(LineBased和LengthBased,我是用的是LineBased)
为什么要使用LineBased,怎么分割的(/r/n,当时没有考虑太多,觉得这个比较简单)
-
Netty解决粘包的几种方式
Netty 拆包粘包的实质,Netty线程池中的线程建立连接之后,这条连接是不是始终于这个请求,对于Netty来说是不是只占用服务端的一个套接字,了解zero copy嘛
项目中如何解决粘包、拆包的问题(基于字符或者基于长度)
你这个报文传输的时候会不会遇到报文粘连的情况?如何解决?
-
Netty底层原理
-
Netty中的select过程
-
零拷贝讲讲(mmap优化,sendfile)
-
Netty的两个线程池,为什么两个,有什么区别,具体说来。
Netty初始化的时候需要初始化两个线程池,你能简单说一说吗?
-
怎么实现保持长连接的(Netty保证的,应该是使用了TCP的长连接特性)
-
如何实现心跳保持(IDLE编解码器监听事件)
-
多少个线程,为什么这么设置?(netty自带的,默认CPU*2)
四、负载均衡
策略:负载均衡算法(四种)、负载均衡器设置、负载均衡作用
项目实现:
-
项目中负载均衡怎么实现的(看项目代码)
怎么实现负载均衡策略的(我只做了最简单的轮询、加权、随机,通过在zookeeper中配置,然后将引用按照权重将Channel的引用加入到一个List当中)
先设置一个负载均衡接口LoadBalancer,然后用继承接口得到轮询、随机两个类,然后在NacosServiceDiscovery设置一个loadBalancer属性及它的函数,
在SocketTestClient的创建client时传入loadBalancer参数到SocketClient类中,serviceDiscovery
测试类中
SocketClient client = new SocketClient(CommonSerializer.KRYO_SERIALIZER, new RoundRobinLoadBalancer());
构造函数
serviceDiscovery = new NacosServiceDiscovery(loadBalancer);
NacosServiceDiscovery中
public NacosServiceDiscovery(LoadBalancer loadBalancer){
if (loadBalancer == null){
this.loadBalancer = new RandomLoadBalancer();
}else {this.loadBalancer = loadBalancer;}}
lookupService方法调用
Instance instance = loadBalancer.select(instances);
-
项目中负载均衡算法用到那些
轮询、随机
-
解释一下什么是负载均衡?
指将负载(工作任务)进行平衡、分摊到多个操作单元上进行运行
之后结合算法回答
-
负载均衡了解哪些(dubbo的四种策略说了下(轮询、随机、一致性哈希、最小活跃数)
(1) RandomLoadBalance:随机负载均衡。随机的选择一个。是Dubbo的默认负载均衡策略(Dubbo 中的随机负载是按照权重设置随机概率)。
(2) RoundRobinLoadBalance:轮询负载均衡。轮询选择一个(Dubbo中有权重的概念,按公约后的权重设置轮询比率)。
问题:存在慢的提供者请求的问题,比如:第二胎机器很慢,但没挂,当请求调到第二台时就卡在那,久而久之,所有请求都卡在调到第二台上
(3) LeastActiveLoadBalance:最少活跃调用数,相同活跃数的随机。活跃数指调用前后计数差。
好处:使慢的 Provider 收到更少请求,因为越慢的 Provider 的调用前后计数差会越大。
(4) ConsistentHashLoadBalance:一致性哈希负载均衡。一致性hash:添加删除机器前后映射关系一致,当然,不是严格一致。实现的关键是环形Hash空间。将数据和机器都hash到环上,数据映射到顺时针离自己最近的机器中。
好处:当某一台提供者挂时,原本该发往该提供者的请求,基于虚拟节点,平摊到其他提供者,不会引起剧烈变动
-
RPC调用中使用随机算法和轮转算法做负载均衡的优缺点
优点:实现简单,水平扩展方便
缺点:因为相同的请求会被落到不同的机器上,浪费内存啊,内存有限,Cache会被淘汰,频繁淘汰,当然使得命中率低下啊。
-
dubbo负载均衡算法,一致性哈希的实现?
1.问简单的话,用4.(4)
2.难的话源码
-
Dubbo为什么推荐基于随机的负载均衡?
1.实现简单,水平扩展方便
2.在一个截面上碰撞的概率高,但调用越大分布越均匀,而且按概率使用权重后也比较均匀,有利于动态调整提供者权重
-
负载均衡作用
(1)根据集群中每个节点的负载情况将用户请求转发到合适的节点上, 以避免单点压力过大的问题
(2)负载均衡可实现集群高可用及伸缩性
高可用:某个节点故障时,负载均衡器会将用户请求转发到其他节点,从而保证所有服务持续可用.
伸缩性:根据系统整体负载情况,可以很容易地添加或移除节点。
-
如何设计负载均衡器
负载均衡器工作原理有两大方法:
- 接收客户端请求,将请求转发给集群中的各台服务器处理,服务器将处理结果返回给负载均衡器,负载均衡器将处理结果转发给相应的客户端。
- 接收客户端请求,将请求转发给集群中的各台服务器处理,服务器将处理结果直接返回给相应的客户端。
-
负载均衡如何保证健壮性?
(采用心跳机制检测宕机节点。)
-
一个服务可能有多台机器可以调用?(利用负载均衡算法)
五、RPC 和 HTTP
-
RPC 有没有可能会用 HTTP 协议?(有,如 grpc 就是 HTTP2.0)
-
RPC 和 HTTP的对比?为什么要用 RPC?
1、传输协议:
RPC:基于HTTP协议,TCP协议
HTTP:基于HTTP协议
2、传输效率:
RPC:(1)使用自定义的TCP协议,请求报文体积更小,
(2)使用HTTP2协议,也可以很好的减小报文体积,提高传输效率
HTTP:(1)基于http1.1的协议,请求中会包含很多无用的内容,
(2)基于HTTP2.0,那么简单的封装下可以作为一个RPC来使用,这时标准的RPC框架更多的是服务治理。
3、性能消耗:
RPC:可以基于thrift实现高效的二进制传输
HTTP:大部分是基于JSON实现的,字节大小和序列化耗时都比thrift要更消耗性能
4、负载均衡:
RPC:基本自带了负载均衡策略
HTTP:需要配置Nginx、HAProxy配置
5、服务治理:(下游服务新增,重启,下线时如何不影响上游调用者)
RPC:能做到自动通知,不影响上游
HTTP:需要事先通知,如修改NGINX配置。
-
RPC 传输速度比 HTTP 更快吗?
不一定,但一般会快。取决于序列化协议和传输协议,
比如二进制编码肯定比 JSON 节省体积,自定义 tcp 协议/HTTP2.0 比 tcp/HTTP1.1 要快
-
用的TCP还是HTTP2传输的?
自己项目、DUBBO:TCP
grpc:http2.0
-
HTTP 和 RPC 的关系? RPC 和 HTTP 的区别?
-
为什么spring cloud用的是http
HTTP Restful本身轻量,易用,适用性强,可以很容易的跨语言,跨平台,或者与已有系统交互,
目前很多大型项目多语言共存,http是最通用的协议,可以很好地解决跨语言跨平台兼容性
-
为什么我们要使用RPC而不是使用HTTP?
-
你这个RPC框架是基于HTTP请求的吗?
不是,基于TCP
-
RPC 是用的时候连一次,还是连一次后就长连接?
自己的RPC是长连接(Netty 中提供了
IdleStateHandler类专门用于处理心跳,所以是长连接没有这个,默认一般是短连接)文章来源:https://www.toymoban.com/news/detail-772006.html
(这个被问过好几次,我猜是长连接,有大佬知道吗)文章来源地址https://www.toymoban.com/news/detail-772006.html
到了这里,关于分布式【RPC 常见面试题】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!