爬了两天大大小小的一堆坑,今天把一个简单的单机环境的流程走通了,记录一笔。
先来个完工环境照:

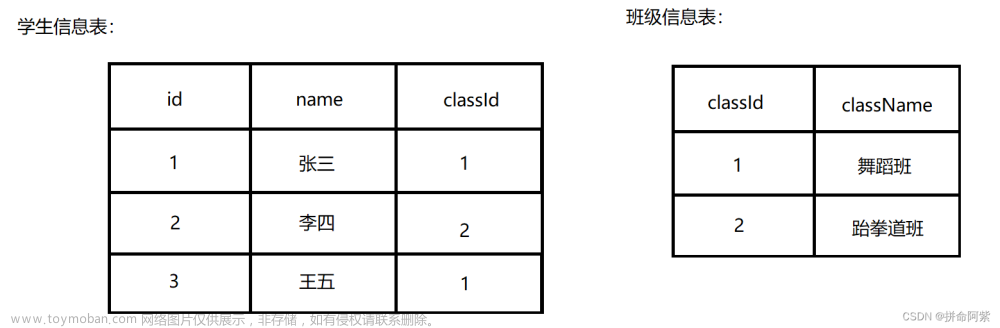
mysql+hadoop+hive+flink+iceberg+trino
得益于IBM OPENJ9的优化,完全启动后的内存占用:
1)执行联合查询后的
2)其中trino由于必须使用ORACLE或OPENJDK,只能再安装多一个JDK21的环境

HIVE里ICEBERG的表和数据:
-- iceberg.test.my_tbl definition
CREATE TABLE iceberg.test.my_tbl (
user_id integer,
user_name varchar,
country varchar,
birthday date
)
WITH (
format = 'PARQUET',
format_version = 2,
location = 'hdfs://localhost:9000/user/hive/warehouse/test.db/my_tbl',
partitioning = ARRAY['country']
);

MYSQL里的表和数据:
-- dict.dict.country definition
CREATE TABLE dict.dict.country (
country_name varchar(2) NOT NULL,
country_cn varchar(20) NOT NULL
);

联合查询的执行结果:文章来源:https://www.toymoban.com/news/detail-772137.html
 文章来源地址https://www.toymoban.com/news/detail-772137.html
文章来源地址https://www.toymoban.com/news/detail-772137.html
到了这里,关于【湖仓一体尝试】MYSQL和HIVE数据联合查询的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!