一、背景
周所周知,Kafka是一个非常成熟的消息产品,开源社区也已经经历了多年的不断迭代,特性列表更是能装下好几马车,比如:幂等消息、事务支持、多副本高可用、ACL、Auto Rebalance、HW、Leader Epoch、Time Index、Producer Snapshot、Stream、Connector、多级存储、MirrorMaker、消息压缩、Fetch Session、Metrics、Quota等等,Kafka的特性列表真要往出列的话,可能会占满半个屏幕
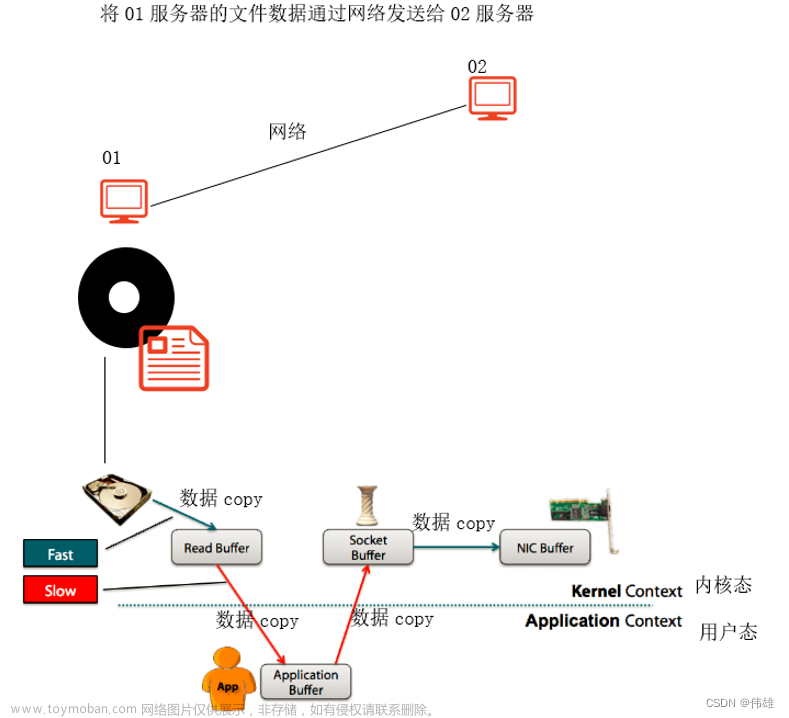
然后我们今天不去探讨这些“炫酷”的feature,只将目光聚焦在消息的生产、存储、消费上,同时这3个功能也是大部分用户接触最多、最基础的功能,值得花时间去探究
再声名一点,零拷贝只存在于消息消费环节中,消息生产因为需要将消息放入堆内存中进行各种校验,因此不存在零拷贝的场景
二、消息协议
我们知道Kafka在演变的过程中,经历了3个消息协议版本的迭代,其中V0与V1版大同小异:

同样这2个版本也是Kafka早期的版本,当然使用广泛度较低,较为普及的还是V2版本

当然我们这次的叙述均是以V2版本展开的,也就是大家耳熟能详的Record Batch 注:关于V2版本的细节不是本文的重点,这里不再展开,可自行Google,读者只需要知道V2版本引入了Record Batch机制,即一个Record Batch可能含有1-N条消息
三、消息生产
消息生产端Producer这里没有太多需要同步的,一言蔽之就是将消息封装后发送给Broker端,不过读者这里想强调一下 Record Batch 的概念
在默认情况下,单Batch的上限是16K,一个Batch可以存储1条或者多条消息,这个取决于Producer端的配置,如果Producer设置了黏性分区策略,linger.ms聚批时间设置足够长(例如1000ms),那么很容易将Batch填满;又或者linger.ms配置了默认值(linger.ms=0),那么聚批将不会被触发,那一个Batch上就只有一条消息。因此无论怎样,Record Batch是消息的载体,也是消息读取的最小单位(注意不是消息本身,这里在后文还会提及)

上图表明了,某个 Record Batch 中可能只有一条消息,也有可能存在多条,甚至将16K全部填充满;无论哪种case,Producer 都是以 Record Batch 粒度将消息发送至Broker的
四、消息存储
为了满足基本的生产、存储、消费需求的话,只需要2个文件足矣:
- xxxxxxxxx.log 例如:00000000000000000000.log
- xxxxxxxxx.index 例如:00000000000000000000.index
其中log文件是用来存储消息的,而index文件则是用来存储稀疏索引的
- log文件:通过append的方式向文件内进行追加,每个Segment对应一个log文件
- index文件:索引文件,每隔4K存储一次offset+position,帮助快速定位指定位点的文件position用的
注:这里为什么要隔4K做一次稀疏索引,而不是3K或者5K呢?其实这里主要是与硬件兼容,现在多数厂商的硬件,单次扫数据的大小一般都是4K对齐的,很多硬件都提升到了8K甚至16K,稀疏索引设置为4K,能保证即便是当前的 Record Batch 只有 1 个字节,后续的内容也能缓存在Page Cache中,下次扫描的时候,可以直接从缓存中读取,而不用扫描磁盘
另外,基于V2的存储版本,消息的查询都是以 Record Batch 作为最小粒度查询的,而 Producer 设置的 Record Batch 的默认值为16K,即如果消息攒批合理的话,稀疏索引可能是每隔16K构建起来的
既然index并不是针对每条消息的offset做存储的,那单凭这2个文件是如何做到可以查询任意一条消息呢?
五、消息消费
消费的时候,需要设置2个非常重要的参数
- fetch.min.bytes 单次拉取最小字节数,默认 1 byte
- fetch.max.bytes 单次拉取最大字节数,默认 50 * 1024 * 1024 byte,即50M
这2个字段有什么作用呢?
- fetch.min.bytes 表明单次拉取消息的最小字节数,只要某次拉取的消息数大于了这个配置项,即便是其还未达到fetch.max.bytes,那么也会直接返回
- fetch.max.bytes 表明单次拉取消息的最大字节数,注意,这里是严格意义上的字节数,包括消息体即消息协议
但是很容易想到一个问题,如果 fetch.max.bytes 配置的大小是1M,而下一条消息有2M,那岂不是永远都拉不到消息了? 这种场景,其实Kafka的策略是至少会返回一条消息,即便是这条消息的大小超过了 fetch.max.bytes,也会将其返回
看一个非常直接的问题:consumer要拉取消息,且从位点offset 4567 开始查询,fetch.min.bytes = 10K,fetch.max.bytes = 100K。RocketMQ的索引文件存储了每条消息的position,可以想象为KV对儿:offset:position,根据offset可以快速定位该条消息对应的CommitLog的文件position,而基于稀疏索引的Kafka,如何快速定位查询呢?
笔者认为,论设计来看,Kafka的稀疏索引可能更合理,更贴合操作文件的模式
既然是稀疏索引,那么势必没有将每条消息对应的position做存储,那么如何定位单条消息的具体位置呢?
这里先直接给出结论:
- 先读取稀疏索引定位大致位置
- 然后读取log文件准确定位
5.1、粗略定位
假定稀疏索引.index文件的内容如下
|
Offset |
Position |
|
100 |
4000 |
|
110 |
8200 |
|
120 |
13000 |
|
130 |
18000 |
当我们要寻找 offset 为115位点对应的文件position时,因为115介于「110-120」之间,因此稀疏索引能够提供的信息就是需要从 8200 的位置开始往后找,这样也就粗略定位了115的大致position

这里延深一些,110对应的8200如何寻找呢? 真实环境是这个数据存储在index文件中,而且会有很多KV对;其实这里使用的是二分查找,当知道某个队列的起始结束offset,快速定位其中的某个offset时,二分查找是个非常不错的方案,具体实现类在scala/kafka/log/AbstractIndex.scala

本文不再赘述
现在只是根据稀疏索引定位到了大致位置,具体应该从哪里返回数据呢?这就涉及第二步精细定位
5.2、精细定位
粗略定位是扫描.index文件,而精细定位则是扫描.log文件。在5.1粗略定位中,LogSegment.scala 有一段代码
@threadsafe
private[log] def translateOffset(offset: Long, startingFilePosition: Int = 0): LogOffsetPosition = {
val mapping = offsetIndex.lookup(offset)
log.searchForOffsetWithSize(offset, max(mapping.position, startingFilePosition))
}其中
-
val mapping = offsetIndex.lookup(offset)是用来粗略定位的,主要返回mapping.position,即精细查找的起始position -
log.searchForOffsetWithSize精细定位,通过迭代 Record Batch 实现
现在已经知道了开始扫描的文件起始position,那么接下来就要逐一扫描 Record Batch
/**
* Search forward for the file position of the last offset that is greater than or equal to the target offset
* and return its physical position and the size of the message (including log overhead) at the returned offset. If
* no such offsets are found, return null.
*
* @param targetOffset The offset to search for.
* @param startingPosition The starting position in the file to begin searching from.
*/
public LogOffsetPosition searchForOffsetWithSize(long targetOffset, int startingPosition) {
for (FileChannelRecordBatch batch : batchesFrom(startingPosition)) {
long offset = batch.lastOffset();
if (offset >= targetOffset)
return new LogOffsetPosition(offset, batch.position(), batch.sizeInBytes());
}
return null;
}因为V2版本已经指定了 Record Batch 的总长度、start offset、last offset等,因此很快可以定位
我们再举个例子,将5.1与5.2串起来

在稀疏索引中,offset与文件position(文件的物理position)的对应存储只有3个:
5:500
13: 1300
24: 2400
当某次consumer要从offset=20的位置拉取消息时
- 第一步,需要二分查找稀疏索引,这个时候发现,比20小的最大offset是13,因此找到13对应的文件position,即1300,继而继续从log文件中查找
- 第二步,从1300位置读取 Record Batch,不过只读取header部分即可,从而获取到此Batch的最小offset是13,最大offset是18,length是XX(参照V2消息协议,其中都有存储这些数据);发现目标offset 20并不在当前Batch中,那么继而扫描下一个 Record Batch,并最终定位 Record Batch 3 就是目标Batch,然后返回此Batch 的start position (注:不是20对应的position,而是Record Batch 3的position)
Kafka这样设计,我们还是有一些疑问的
-
精细定位的时候,需要逐一遍历
.log文件,而 Record Batch 可能也会有多个,这样是否存在频繁访问磁盘的bad case?
- 首先确认一点,这个问题是不存在的;
- 当我们通过稀疏索引定位到大致的位置后,目标offset离我们其实已经不远了,可能只有4K的数据,当我们扫描这4K数据的时候,借助于操作系统的预读,在第一次读取时,会将这4K的数据都加载到 Page Cache 中,后续再读取时,其实是直接从 Page Cache 中读的,性能很高
- 还有一种情况是,Record Batch 比较大,比如有16K,这种情况基本上是一个 Record Batch 就对应了稀疏索引中的一条数据,因此扫描1条 Record Batch 即定位数据
- 上例中,既然我们能够找到 offset=20 对应的文件物理position,为什么还要返回此 Record Batch 的position?
- 这里主要是跟V2版本的协议有关,不论是数据生产还是消费,其所有交互中,Record Batch 是最小单位,即便是单个 Record Batch 中只有1条数据。因此如果直接返回offset=20的position,会导致client端数据解析的失败
5.3、数据拉取
数据拉取就相对比较简单了,这里用到了零拷贝技术,也就是FileChannel.transferTo(long position, long count),将磁盘中的数据直接拷贝给网卡。拷贝的起始position就是上文中定位的,而拷贝的长度则是fetch.max.bytes。但fetch.max.bytes是用户指定的,如何确保拷贝的数据段结尾正好落在 Record Batch 的结尾?
其实这里是无法保证最后一个 Record Batch 是完整的,也就是存在拷贝了半个 Record Batch 的情况;而这种情况的兼容则放在了Consumer端来做,当Consumer发现拉取的数据不完整时,便直接截断了,截取org/apache/kafka/common/record/ByteBufferLogInputStream.java 部分代码:
public MutableRecordBatch nextBatch() {
int remaining = buffer.remaining();
Integer batchSize = nextBatchSize();
if (batchSize == null || remaining < batchSize)
return null;
byte magic = buffer.get(buffer.position() + MAGIC_OFFSET);
ByteBuffer batchSlice = buffer.slice();
batchSlice.limit(batchSize);
buffer.position(buffer.position() + batchSize);
if (magic > RecordBatch.MAGIC_VALUE_V1)
return new DefaultRecordBatch(batchSlice);
else
return new AbstractLegacyRecordBatch.ByteBufferLegacyRecordBatch(batchSlice);
}其中 (remaining < batchSize) {return null;} 就是判断半条消息的case
那这种情况,岂不是存在浪费资源的情况,最后一个 Record Batch 可能会被拷贝2次?
确实存在,不过我们要分情况来讨论:
- Consumer热读,即Consumer读取数据时,消息还在 Page Cache 中有停留,这也是大部分的Kafka的消费场景,因为默认单次拉取的最大数据为50M,因此一般可以拉去全量未读数据,因此也就不存在浪费资源的情况
- Consumer冷读,直接从磁盘中读取数据,是大概率存在读取了半条消息的case的,不过由于单次可能会拉取50M的数据,而浪费的数据可能只有几K,因此是可以接受的
六、场景演练
我们站在client端的角度,来看下几种场景下消息消费的情况
6.1、单Batch单消息
|
元数据: |
创建topic3,单分区、单副本 |
|
生产消息: |
向其发放5条消息,每条消息1K,然后linger.ms保持默认值0 |
通过这样配置,因为linger.ms=0,因此topic3中就存在了5个 Record Batch,然后每个Batch中的消息数量为 1
然后设置 fetch.max.bytes=3500 后进行查询,通过debug查看org/apache/kafka/common/record/ByteBufferLogInputStream.java 类中ByteBuffer在执行消息反序列化之前的状态
因为设置最大的拉取数据大小是3500字节,而我们单条消息设置了1K,且1个Batch中只有1条消息,因此预期会有拉取半条消息的case

果然打开debug后发现,Consumer直接从Broker中拉取了3500byte的数据,也就是拉取了3条完整的Batch+半条消息。处理完这3条消息后,第二次发起查询:

发现只返回了最后2条消息,且不存在半条消息的case。这种情况下,第4条消息的前半段实际上是重复发送了2次
6.2、单Batch多消息
|
元数据: |
创建topic4,单分区、单副本 |
|
生产消息: |
连续向其发放2条消息,第一条消息1K,第二条2K,linger.ms=1000 |
因为linger.ms=1000,因此topic4的两条消息将会发生聚批,也就是1个Batch中存储了2条消息
然后设置 fetch.max.bytes=10 后进行查询,因为单Batch的消息已经有3K,因此预期会返回3K的数据

与预期相符,这次我们通过assign的方式,并指定 offset=1 开始消费,并打印消费的消息的条数
private void consume() {
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(getCommonProperties());
kafkaConsumer.commitAsync();
kafkaConsumer.assign(Collections.singletonList(new TopicPartition(Common.TOPIC_NAME, 0)));
TopicPartition topicPartition = new TopicPartition(Common.TOPIC_NAME, 0);
kafkaConsumer.seek(topicPartition, 1);
while (true) {
ConsumerRecords<String, String> records = kafkaConsumer.poll(Duration.ofSeconds(1));
System.out.println("records.count is : " + records.count());
if (records.count() > 0) {
} else {
System.out.println("none msg");
}
}
}运行后发现,确实只收到了一条消息
records.count is : 1
records.count is : 0
none msg
records.count is : 0然后debug看consumer真实收到的数据长度

不出意外,Broker返回了offset=1所在的 Record Batch 的所有数据,而过滤、兼容则都由Consumer来完成文章来源:https://www.toymoban.com/news/detail-772397.html
再考虑到Consumer的各种Rebalance以及Producer聚批等,说Kafka的client是重客户端,我想大抵就是如此文章来源地址https://www.toymoban.com/news/detail-772397.html
到了这里,关于Kafka干货之「零拷贝」的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!