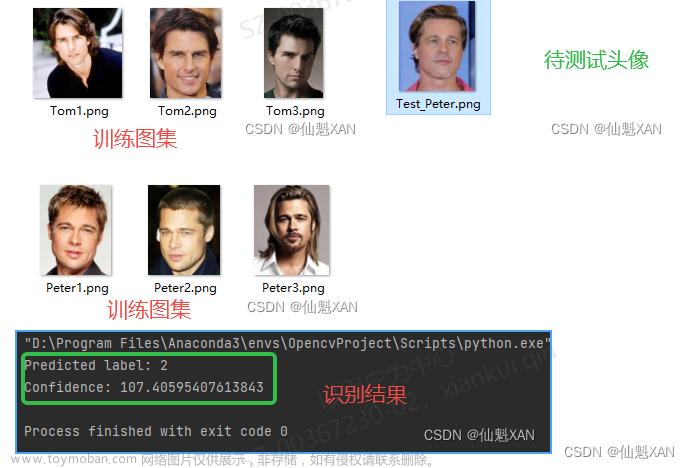
接着练手图像处理例子
文章来源:https://www.toymoban.com/news/detail-772593.html
抛开网上截图进行OCR识别,更多的图源来自于我们的手机,相机等等设备,而得到的图片都并非是板正的,大多随手一拍的图源都是带有角度的,所以我们需要先将图像进行摆正。
首先先对图像进行预处理,上代码:
1 def edge_detect(image): 2 gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY) 3 edges = cv2.Canny(gray, 100, 200) 4 contours, hierarchy = cv2.findContours(edges.copy(), cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE) 5 conts = sorted(contours, key=cv2.contourArea, reverse=True)[:5] 6 for c in conts: 7 peri = cv2.arcLength(c, True) 8 approx = cv2.approxPolyDP(c, 0.02*peri, True) 9 if len(approx) == 4: 10 ss = approx 11 cv2.drawContours(image, [ss], -1, (0, 255, 0), 2) 12 cv2.imshow('', image)
1、使用Canny来进行边缘提取。
2、使用cv2.approxPolyDP来进行轮廓逼近。
3、将我们想要的轮廓绘制出来。
上述代码中,cv2.approxPolyDP方法的epsilon参数很有讲究,先贴上parameter和reval。
参数说明:
curve:输入的轮廓数据。epsilon:指定逼近精度,即源轮廓到逼近结果的最大距离。较小的值会得到更精确的逼近,但轮廓的点数也会更多。closed:一个布尔值,指示轮廓是否闭合。approxCurve:可选参数,表示输出的逼近多边形曲线。
该函数返回逼近多边形的结果:
使用cv2.approxPolyDP函数可以将复杂的轮廓近似为简单的多边形,从而方便后续的形状分析和处理操作。(注:针对approxPolyDP返回的坐标顺序,和输入轮廓的顺序有关,下述图片输入的顺序是逆时针)
关于epsilon参数,这是一个和周长相关的参数,使用在进行轮廓逼近时的误差:
1、当epsilon(ε)越大时,也就是说,我们给定的误差范围越大,这就代表着我们得到的逼近轮廓的形状越是粗糙或者说敷衍(顶点较少),但是过大时会导致得到的逼近形状并不能很好的表达原始轮廓的形状。
2、当epsilon(ε)越小时,那么得到的逼近形状就越精确或者说细致(顶点较多),但是过小时会导致得到的逼近形状过于接近原始轮廓,出现过拟合的现状。
不理解的可以动手调整传入epsilon(ε)的值看看效果。
运行结果:

参考博文:OpenCV实战(4)——文档扫描OCR识别&答题卡识别判卷(文档扫描,图像矫正,透视变换,OCR识别) - 战争热诚 - 博客园 (cnblogs.com)文章来源地址https://www.toymoban.com/news/detail-772593.html
到了这里,关于【Python】【OpenCV】OCR识别(一)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!