用自动化工具selenium批量获取油管播放列表内视频的url
今天突发奇想想下载一些古早哆啦A梦的视频,看了一下B站上没有我满意的形式,所以上油管看了一下:
不错不错,配合我的油管视频解析网站可以直接下载到本地
唯一的问题就是:一个一个复制链接太麻烦了!!!
如果有一个工具可以批量复制列表内的视频链接就好了,正好现在在学Python,此时不用何时用?
简单百度了一下,我把目光放在了自动化操作浏览器的工具Selenium上,开源、支持python、模拟操作用户行为,是一款很不错的工具。
太长不看版:文末会附上完整代码,有两处需要自行修改得到地方
首先就是selenium库的安装
pip install selenium
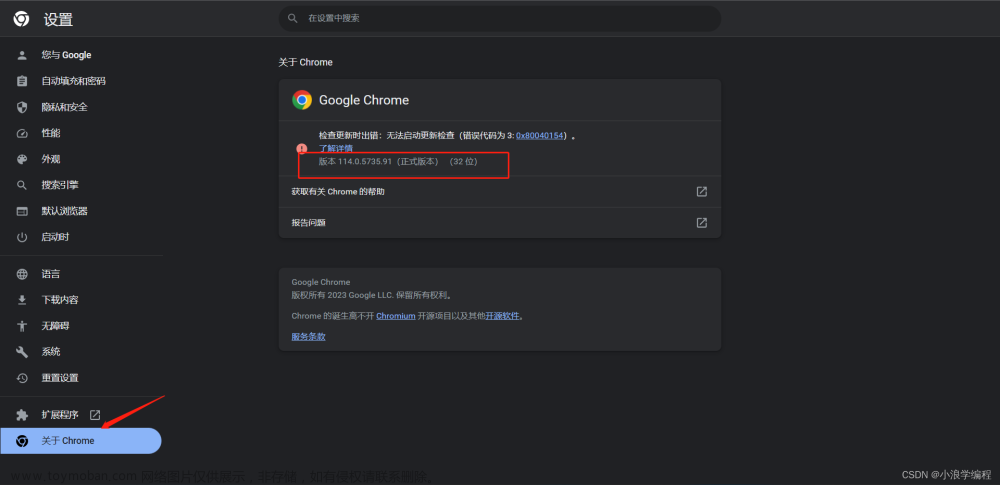
我这里用的是Chrome浏览器,所以在这里下载Chrome浏览器的驱动,其他浏览器可以自行在网上查找,注意下载对应本浏览器版本的驱动。
然后导入库:
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
我们的核心任务就是使用selenium获取视频url:
def get_playlist_video_urls(playlist_url):
...
return video_urls
输入视频列表的url,输出存放所以视频url的列表
编写函数内容:
- 设置浏览器的驱动路径
driver_path = r'在这里输入你的驱动存放路径' - 初始化:
service = webdriver.ChromeService() driver = webdriver.Chrome(service=service) service = webdriver.ChromeService(executable_path=driver_path) - 打开播放列表页面,等待加载,这里等待时间根据网络和电脑性能调整:
driver.get(playlist_url) time.sleep(5) - 模拟滚动,加载所有视频:
last_height = driver.execute_script("return document.documentElement.scrollHeight") while True: driver.execute_script("window.scrollTo(0, document.documentElement.scrollHeight);") time.sleep(2) new_height = driver.execute_script("return document.documentElement.scrollHeight") if new_height == last_height: break last_height = new_height - 获取所有链接:
这里介绍一下find_elements方法:video_links = driver.find_elements(by=By.XPATH,value='//*[@id="video-title"]') video_urls = [link.get_attribute('href') for link in video_links]
主要有两个参数,一个是def find_elements(self, by=By.ID, value: Optional[str] = None) -> List[WebElement]:by,一个是valueby参数有八种值:
通过目标的class By: """Set of supported locator strategies.""" ID = "id" XPATH = "xpath" LINK_TEXT = "link text" PARTIAL_LINK_TEXT = "partial link text" NAME = "name" TAG_NAME = "tag name" CLASS_NAME = "class name" CSS_SELECTOR = "css selector"id、XPATH等参数来搜索,具体介绍参考这篇博客,我们这里使用了XPATH搜索,'value'具体语法参考另一篇博客
这下这个函数的基本结构就完成了,只需要编写主函数即可:
# 替换成要获取的播放列表的URL
playlist_url = 'URL'
# 获取播放列表中所有视频的URL
video_urls = get_playlist_video_urls(playlist_url)
# 打印所有视频的URL
for url in video_urls:
print(url)
这下就可以完美输出啦
附:文章来源:https://www.toymoban.com/news/detail-772624.html
完整代码文章来源地址https://www.toymoban.com/news/detail-772624.html
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
def get_playlist_video_urls(playlist_url):
# 设置Chrome浏览器的驱动路径
driver_path = r''
# 初始化
service = webdriver.ChromeService()
driver = webdriver.Chrome(service=service)
service = webdriver.ChromeService(executable_path=driver_path)
# 打开播放列表页面,等待页面加载
driver.get(playlist_url)
time.sleep(5)
# 模拟滚动以加载所有视频
last_height = driver.execute_script("return document.documentElement.scrollHeight")
while True:
driver.execute_script("window.scrollTo(0, document.documentElement.scrollHeight);")
time.sleep(2)
new_height = driver.execute_script("return document.documentElement.scrollHeight")
if new_height == last_height:
break
last_height = new_height
# 获取所有视频链接
video_links = driver.find_elements(by=By.XPATH,value='//*[@id="video-title"]')
video_urls = [link.get_attribute('href') for link in video_links]
# 关闭浏览器
driver.quit()
return video_urls
if __name__ == "__main__":
# 替换成您要获取的播放列表的URL
playlist_url = 'URL'
# 获取播放列表中所有视频的URL
video_urls = get_playlist_video_urls(playlist_url)
# 打印所有视频的URL
for url in video_urls:
print(url)
到了这里,关于用自动化工具selenium批量获取油管播放列表内视频的url的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!