[ELasticSearch]-Logstash的使用
森格 | 2023年2月
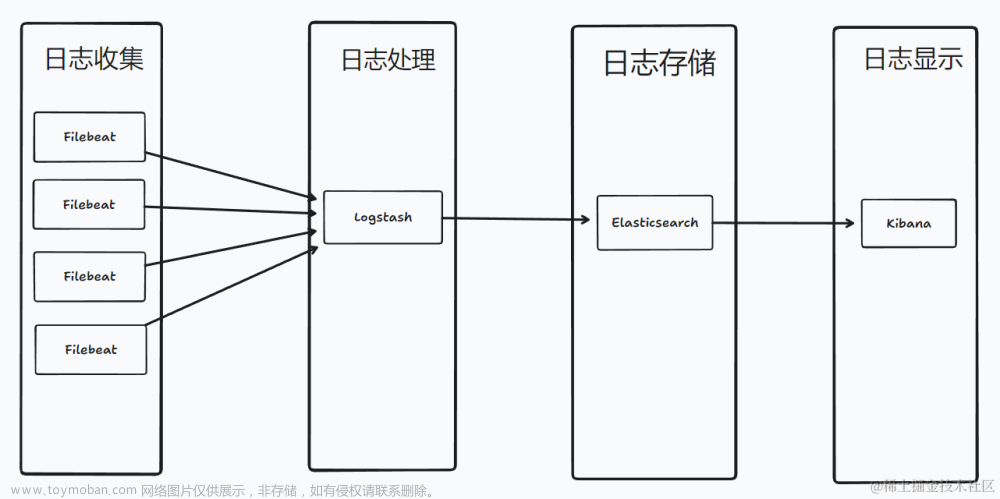
介绍:Logstash在Elastic Stack中担当着ELK的工作,在本文主要阐述Logstash的处理流程以及一些应用案例。
一、Logstash介绍
1.1 What is Logstash?
Logstash是一款强大的ETL(Extract、Transform、Load)工具。我们可以把它想象成具有数据传输能力的管道,数据信息从输入端(Input)传输到输出端(Output),用户可根据自己的需要在管道中间加上过滤网(Filter)。
1.2 版本兼容性
通常来说,对于Elastic的相关产品,版本最好一一对应。
在个人使用Logstash做es的索引迁移过程中,跳板机使用版本为7.4.1,es版本为6.8.x、7.4.x、7.7.x,迁移过程未见问题。
1.3 处理流程
可以把Logstash实例看成一个正在运行的Logstash进程,因为Logstash利用了jvm,建议在单独的机器上运行。而对于其中的管道可以看成插件的合集,一个Logstash可以运行多个管道,且多个管道之间彼此独立。

对于Logstash我们主要需要配置三个插件:
Input Plugins:提取或接收数据。
Filter Plugins:应用转换并丰富数据。
Output Plugins:将已处理的数据加载给目标。
除此之外还有Codec plugins(编码器插件),作用于input和output plugin中 ,更改事件的数据表示,最常见的为json格式。
想要了解更多插件支持参考官网:Input Plugins、Filter Plugins、Output Plugins、Codec plugins。
# 查看已安装的插件
cd /logstash
./bin/logstash-plugin list
二、Logstash应用
2.1 ElasticSearch索引迁移
2.1.1 logstash-input-elasticsearch
input {
elasticsearch {
hosts => [
"xxx.xxx.xxx.xxx:9200"
]
user => "xxx"
password => "xxx"
index => "xxx"
query => '{
"query": {
"match_all": {}
}
}'
size => 500
scroll => "5m"
docinfo => true
codec => json
}
}
- index:要匹配的索引,多个索引用
,隔开。 - size:每次滚动返回的最大匹配记录数。默认值1000。
- scroll:此参数用来控制滚动请求的保活时间(单位为秒),并启动滚动过程,默认值1m。
- docinfo:在事件中会包含es文档的信息,例如索引、类型、id等。默认值flase。
- codec:在数据输入之前对其进行解码。默认为json。
2.1.2 logstash-filter-mutate
filter {
mutate {
remove_field => [
"@timestamp",
"@version"
]
}
}
Logstash的输出数据会加上版本和时间戳信息。所以我们要过滤掉这些信息。
过滤前:

过滤后:

2.1.3 logstash-output-elasticsearch
output {
elasticsearch {
hosts => [
"xxx.xxx.xxx.xxx:9200"
]
user => "xxx"
password => "xxx"
action => "update" //有则更新,无则插入
doc_as_upsert => true
document_type => "_doc" //文档类型
document_id => "%{[@metadata][_id]}" //文档id,取元数据docinfo信息中的id
index => "%{[@metadata][_index]}" //文档索引名,取元数据docinfo信息中的索引名
}
}
2.2 同步MySQL数据
2.2.1 logstash-input-jdbc
- 下载jar包(mysql-connector)
# 下载
wget https://downloads.mysql.com/archives/get/p/3/file/mysql-connector-j-8.0.31.tar.gz
tar -zxf mysql-connector-j-8.0.31.tar.gz
# 复制jar包到/xx/logstash/logstash-core/lib/jars/目录
cp /mysql-connector-j-8.0.31/mysql-connector-j-8.0.31.jar /xx/logstash/logstash-core/lib/jars/
这里值得提的是,将连接的jar包放置于Logstash的logstash-core/lib/jars/目录下,就不用再配置中设置jdbc_driver_library参数。
- input 配置
input {
jdbc {
jdbc_connection_string => "jdbc:mysql://数据库地址:端口/数据库名?useUnicode=true&characterEncoding=utf8&serverTimezone=Asia/Shanghai&useSSL=false"
jdbc_user => "xxxxxx"
jdbc_password => "xxxxxx"
jdbc_driver_class => "com.mysql.cj.jdbc.Driver"
jdbc_validate_connection => true
jdbc_paging_enabled => true
jdbc_page_size => 50000
lowercase_column_names => false
statement => "SELECT * FROM xxx"
schedule => "*/1 * * * *"
}
}
- jdbc_connection_string:指定编码格式,禁用SSL协议,设定自动重连。
- jdbc_validate_connection:连接前做验证。
- statement:要执行的查询语句。
- lowercase_column_names:将列名转换为小写。
- schedule:定时执行,类似于crontab。
2.2.2 logstash-filter-mutate
同2.1.2,这里不做赘述。
2.2.3 logstash-output-elasticsearch
output {
elasticsearch {
hosts => [
"xxx.xxx.xxx.xxx:9200"
]
user => "xxx"
password => "xxx"
action => "update" //有则更新,无则插入
doc_as_upsert => true
document_type => "_doc" //文档类型
index => "mysql_data" //索引名,需要自己填写
document_id => "%{id}" //文档id,可以根据mysql表中主键id匹配
}
//标准输出,实际运行中可以取消
stdout{
codec => json_lines
}
}
2.3 实战
TODO:迁移mysql某张表的数据到es实例1,再将es实例1的mysql索引迁移至es实例2。
MySQL数据:

将要生成的es索引名为mysql_data_otter
es实例1迁移前索引列表:

es实例2迁移前索引列表:

logstash_mysql.conf、logstahs_es.conf 配置文件按照上文内容修改即可。
执行命令:
./bin/logstash -f ./conf/xxx.conf
运行成功信息如下:
[2023-02-21T09:32:18,661][INFO ][logstash.agent ] Successfully started Logstash API endpoint {:port=>9601}
[2023-02-21T09:32:20,326][INFO ][logstash.runner ] Logstash shut down.
es实例1迁移后索引列表:

es实例2迁移后索引列表:

三、性能调优
3.1 标准输出stdout
在output中我们除了自己做调试使用它,在实际运行过程中避免使用,会影响使用性能。
3.2 内存 JVM
在conf/jvm.options文件中,最好设置为物理内存的50%以上,如果堆大小太低,CPU利用率可能会不必要地增加,从而导致JVM不断进行垃圾回收。且Xms和Xmx堆分配大小设置为相同的值,以防止在运行时调整堆大小。
3.3 管道线程
pipeline.workers:并行执行筛选器和管道输出阶段的工作人员数量,官方建议为CPU核数。文章来源:https://www.toymoban.com/news/detail-772708.html
pipeline.batch.size:单个工作线程在尝试执行其筛选器和输出之前从输入中收集的最大事件数,在内存允许的情况下,可以合理增加批处理大小。文章来源地址https://www.toymoban.com/news/detail-772708.html
到了这里,关于[ELasticSearch]-Logstash的使用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!