前言
纯实操,无理论,本文是给公司搭建测试环境时记录的,已经按照这一套搭了四五遍大数据集群了,目前使用还未发现问题。
有问题麻烦指出,万分感谢!
PS:Centos7.9、Rocky9.1可用
集群配置
| ip | hostname | 系统 | CPU | 内存 | 系统盘 | 数据盘 | 备注 |
|---|---|---|---|---|---|---|---|
| 192.168.22.221 | hadoop1 | Centos7.9 | 4 | 16 | 250G | ||
| 192.168.22.222 | hadoop2 | Centos7.9 | 4 | 16 | 250G | ||
| 192.168.22.223 | hadoop3 | Centos7.9 | 4 | 16 | 250G |
规划集群
| hadoop1 | hadoop2 | hadoop3 | 备注 |
|---|---|---|---|
| NameNode | |||
| NameNode | hadoop | ||
| JournalNode | JournalNode | JournalNode | |
| DataNode | DataNode | DataNode | |
| ResourceManager | ResourceManager | ||
| NodeManager | NodeManager | NodeManager | |
| JobHistoryServer | |||
| DFSZKFailoverController | DFSZKFailoverController | DFSZKFailoverController | |
| QuorumPeerMain | QuorumPeerMain | QuorumPeerMain | zookeeper |
| Kafka | Kafka | Kafka | kafka |
| HMatser | HMatser | HBase | |
| HRegionServer | HRegionServer | HRegionServer | |
| Flink |
工具配置
yum install -y epel-release
yum install -y net-tools
yum install -y vim
yum install -y rsync
#关闭防火墙 和 自启动
systemctl stop firewalld
systemctl disable firewalld.service
修改Centos主机名称
vim /etc/hostname
#输入主机名称
vim /etc/hosts
192.168.22.221 hadoop1
192.168.22.222 hadoop2
192.168.22.223 hadoop3
PS:可先配置脚本方便分发,见底部脚本大全
创建用户
#创建程序用户 区分root
useradd hadoop
passwd hadoop
#修改/etc/sudoers文件,在%wheel这行下面添加一行,如下所示:
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
## Allows people in group wheel to run all commands
%wheel ALL=(ALL) ALL
hadoop ALL=(ALL) NOPASSWD:ALL
#创建文件夹以安装程序
mkdir /opt/module
mkdir /opt/software
#分配用户组
chown hadoop:hadoop /opt/module
chown hadoop:hadoop /opt/software
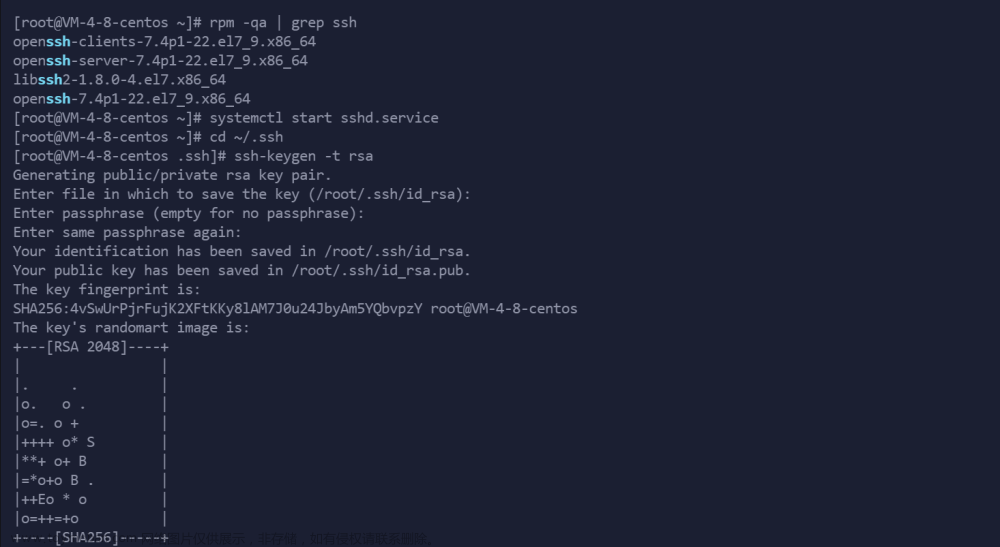
SHH免密登录
#/home/hadoop/.ssh
ssh-keygen -t rsa
#将公钥拷贝到免密登录的目标机器上
ssh-copy-id hadoop1
ssh-copy-id hadoop2
ssh-copy-id hadoop3
JDK安装
PS:环境变量可翻到对应目录,一次配齐。
###解压缩
tar -zxvf /opt/software/jdk-8u212-linux-x64.tar.gz -C /opt/module/
#配置变量
sudo vim /etc/profile.d/my_env.sh
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
#配置生效
source /etc/profile
#检验安装
java -version
zookeeper配置
#解压到指定目录
tar -zxvf /opt/software/apache-zookeeper-3.5.7-bin.tar.gz -C /opt/module/
#修改名称
mv /opt/module/apache-zookeeper-3.5.7-bin /opt/module/zookeeper-3.5.7
#将/opt/module/zookeeper-3.5.7/conf 这个路径下的 zoo_sample.cfg 修改为 zoo.cfg;
mv zoo_sample.cfg zoo.cfg
#打开 zoo.cfg 文件,修改 dataDir 路径:
vim zoo.cfg
dataDir=/opt/module/zookeeper-3.5.7/zkData
#增加如下配置
#######################cluster##########################
server.1=hadoop1:2888:3888
server.2=hadoop2:2888:3888
server.3=hadoop3:2888:3888
#创建zkData
mkdir zkData
#在/opt/module/zookeeper-3.5.7/zkData 目录下创建一个 myid 的文件
#在文件中添加与 server 对应的编号(注意:上下不要有空行,左右不要有空格)
vi /opt/module/zookeeper-3.5.7/zkData/myid
1
#分发配置好的zookeeper
xsync zookeeper-3.5.7
#修改对应的myid
#比如hadoop2 为2、hadoop3 为3
#脚本启动 Zookeeper
bin/zkServer.sh start
#查看状态
bin/zkServer.sh status
#启动客户端
bin/zkCli.sh
#未关闭防火墙需要
#开放端口2888/3888(add为添加,remove为移除)
xcall sudo firewall-cmd --zone=public --permanent --add-port=2181/tcp
xcall sudo firewall-cmd --zone=public --permanent --add-port=2888/tcp
xcall sudo firewall-cmd --zone=public --permanent --add-port=3888/tcp
# 并重载入添加的端口:
xcall sudo firewall-cmd --reload
# 再次查询端口开放情况,确定2888和3888开放
xcall sudo firewall-cmd --zone=public --list-ports
hadoop配置
安装与配置环境
###解压缩
tar -zxvf /opt/software/hadoop-3.1.3.tar.gz -C /opt/module/
#重命名
mv hadoop-3.1.3 hadoop
#配置变量
sudo vim /etc/profile.d/my_env.sh
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
#配置生效
source /etc/profile
#查看版本
hadoop version
#未关闭防火墙需要开放端口
xcall sudo firewall-cmd --zone=public --permanent --add-port=8020/tcp
xcall sudo firewall-cmd --zone=public --permanent --add-port=9870/tcp
xcall sudo firewall-cmd --zone=public --permanent --add-port=8485/tcp
xcall sudo firewall-cmd --zone=public --permanent --add-port=8088/tcp
xcall sudo firewall-cmd --zone=public --permanent --add-port=8032/tcp
xcall sudo firewall-cmd --zone=public --permanent --add-port=8030/tcp
xcall sudo firewall-cmd --zone=public --permanent --add-port=8031/tcp
xcall sudo firewall-cmd --zone=public --permanent --add-port=19888/tcp
xcall sudo firewall-cmd --zone=public --permanent --add-port=10020/tcp
# 并重载入添加的端口:
xcall sudo firewall-cmd --reload
# 再次查询端口开放情况,确定2888和3888开放
xcall sudo firewall-cmd --zone=public --list-ports
/etc/hadoop 配置文件
1、core-site.xml
<configuration>
<!-- 把多个 NameNode 的地址组装成一个集群 mycluster -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 指定 hadoop 运行时产生文件的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为hadoop -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>
<!-- 指定 zkfc 要连接的 zkServer 地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hadoop1:2181,hadoop2:2181,hadoop3:2181</value>
</property>
</configuration>
2、hdfs-site.xml
<configuration>
<!-- NameNode 数据存储目录 -->
<property>
<name>dfs.namenode.name.dir</name>
<value>file://${hadoop.tmp.dir}/name</value>
</property>
<!-- DataNode 数据存储目录 -->
<property>
<name>dfs.datanode.data.dir</name>
<value>file://${hadoop.tmp.dir}/data</value>
</property>
<!-- JournalNode 数据存储目录 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>${hadoop.tmp.dir}/jn</value>
</property>
<!-- 完全分布式集群名称 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- 集群中 NameNode 节点都有哪些 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- NameNode 的 RPC 通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hadoop1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hadoop3:8020</value>
</property>
<!-- NameNode 的 http 通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hadoop1:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hadoop3:9870</value>
</property>
<!-- 指定 NameNode 元数据在 JournalNode 上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hadoop1:8485;hadoop2:8485;hadoop3:8485/mycluster</value>
</property>
<!-- 访问代理类:client 用于确定哪个 NameNode 为 Active -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制,即同一时刻只能有一台服务器对外响应 -->
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
<value>shell(true)</value>
</property>
<!-- 使用隔离机制时需要 ssh 秘钥登录-->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
<!-- 启用 nn 故障自动转移 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
</configuration>
3、yarn-site.xml
<?xml version="1.0"?>
<configuration>
<!-- Site specific YARN configuration properties -->
<!-- 指定MR走shuffle -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 启用 resourcemanager ha -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 声明两台 resourcemanager 的地址 -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster-yarn1</value>
</property>
<!--指定 resourcemanager 的逻辑列表-->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm2,rm3</value>
</property>
<!-- ========== rm1 的配置 ========== -->
<!-- ========== rm2 的配置 ========== -->
<!-- 指定 rm2 的主机名 -->
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hadoop2</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>hadoop2:8088</value>
</property>
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>hadoop2:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>hadoop2:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>hadoop2:8031</value>
</property>
<!-- ========== rm3 的配置 ========== -->
<!-- 指定 rm1 的主机名 -->
<property>
<name>yarn.resourcemanager.hostname.rm3</name>
<value>hadoop3</value>
</property>
<!-- 指定 rm1 的 web 端地址 -->
<property>
<name>yarn.resourcemanager.webapp.address.rm3</name>
<value>hadoop3:8088</value>
</property>
<!-- 指定 rm1 的内部通信地址 -->
<property>
<name>yarn.resourcemanager.address.rm3</name>
<value>hadoop3:8032</value>
</property>
<!-- 指定 AM 向 rm1 申请资源的地址 -->
<property>
<name>yarn.resourcemanager.scheduler.address.rm3</name>
<value>hadoop3:8030</value>
</property>
<!-- 指定供 NM 连接的地址 -->
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm3</name>
<value>hadoop3:8031</value>
</property>
<!-- 指定 zookeeper 集群的地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hadoop1:2181,hadoop2:2181,hadoop3:2181</value>
</property>
<!-- 启用自动恢复 -->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!-- 指定 resourcemanager 的状态信息存储在 zookeeper 集群 -->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
<!-- 环境变量的继承 -->
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
</value>
</property>
<!-- 开启日志聚集功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置日志聚集服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://hadoop1:19888/jobhistory/logs</value>
</property>
<!-- 设置日志保留时间为7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!-- 选择调度器,默认容量 -->
<property>
<description>The class to use as the resource scheduler.</description>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
<!-- ResourceManager处理调度器请求的线程数量,默认50;如果提交的任务数大于50,可以增加该值,但是不能超过3台 * 4线程 = 12线程(去除其他应用程序实际不能超过8) -->
<property>
<description>Number of threads to handle scheduler interface.</description>
<name>yarn.resourcemanager.scheduler.client.thread-count</name>
<value>8</value>
</property>
<!-- 是否让yarn自动检测硬件进行配置,默认是false,如果该节点有很多其他应用程序,建议手动配置。如果该节点没有其他应用程序,可以采用自动 -->
<property>
<description>Enable auto-detection of node capabilities such as
memory and CPU.
</description>
<name>yarn.nodemanager.resource.detect-hardware-capabilities</name>
<value>false</value>
</property>
<!-- 是否将虚拟核数当作CPU核数,默认是false,采用物理CPU核数 -->
<property>
<description>Flag to determine if logical processors(such as
hyperthreads) should be counted as cores. Only applicable on Linux
when yarn.nodemanager.resource.cpu-vcores is set to -1 and
yarn.nodemanager.resource.detect-hardware-capabilities is true.
</description>
<name>yarn.nodemanager.resource.count-logical-processors-as-cores</name>
<value>false</value>
</property>
<!-- 虚拟核数和物理核数乘数,默认是1.0 -->
<property>
<description>Multiplier to determine how to convert phyiscal cores to
vcores. This value is used if yarn.nodemanager.resource.cpu-vcores
is set to -1(which implies auto-calculate vcores) and
yarn.nodemanager.resource.detect-hardware-capabilities is set to true. The number of vcores will be
calculated as number of CPUs * multiplier.
</description>
<name>yarn.nodemanager.resource.pcores-vcores-multiplier</name>
<value>1.0</value>
</property>
<!-- NodeManager使用内存数,默认8G,修改为4G内存 -->
<property>
<description>Amount of physical memory, in MB, that can be allocated
for containers. If set to -1 and
yarn.nodemanager.resource.detect-hardware-capabilities is true, it is
automatically calculated(in case of Windows and Linux).
In other cases, the default is 8192MB.
</description>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>4096</value>
</property>
<!-- nodemanager的CPU核数,不按照硬件环境自动设定时默认是8个,修改为4个 -->
<property>
<description>Number of vcores that can be allocated
for containers. This is used by the RM scheduler when allocating
resources for containers. This is not used to limit the number of
CPUs used by YARN containers. If it is set to -1 and
yarn.nodemanager.resource.detect-hardware-capabilities is true, it is
automatically determined from the hardware in case of Windows and Linux.
In other cases, number of vcores is 8 by default.
</description>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>4</value>
</property>
<!-- 容器最小内存,默认1G -->
<property>
<description>The minimum allocation for every container request at the RM in MBs. Memory requests lower than
this will be set to the value of this property. Additionally, a node manager that is configured to have less
memory than this value will be shut down by the resource manager.
</description>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>1024</value>
</property>
<!-- 容器最大内存,默认8G,修改为2G -->
<property>
<description>The maximum allocation for every container request at the RM in MBs. Memory requests higher than
this will throw an InvalidResourceRequestException.
</description>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
<!-- 容器最小CPU核数,默认1个 -->
<property>
<description>The minimum allocation for every container request at the RM in terms of virtual CPU cores.
Requests lower than this will be set to the value of this property. Additionally, a node manager that is
configured to have fewer virtual cores than this value will be shut down by the resource manager.
</description>
<name>yarn.scheduler.minimum-allocation-vcores</name>
<value>1</value>
</property>
<!-- 容器最大CPU核数,默认4个,修改为2个 -->
<property>
<description>The maximum allocation for every container request at the RM in terms of virtual CPU cores.
Requests higher than this will throw an
InvalidResourceRequestException.
</description>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>2</value>
</property>
<!-- 虚拟内存检查,默认打开,修改为关闭 -->
<property>
<description>Whether virtual memory limits will be enforced for
containers.
</description>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
<!-- 虚拟内存和物理内存设置比例,默认2.1 -->
<property>
<description>Ratio between virtual memory to physical memory when setting memory limits for containers.
Container allocations are expressed in terms of physical memory, and virtual memory usage is allowed to
exceed this allocation by this ratio.
</description>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
</configuration>
4、mapred-site.xml
<configuration>
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- 历史服务器端地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop1:10020</value>
</property>
<!-- 历史服务器web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop1:19888</value>
</property>
</configuration>
5、workers
hadoop1
hadoop2
hadoop3
初始化运行
#分发配置!!!
xsync /opt/module/hadoop/etc/hadoop
#启动journalnode,用来初始化namenode
xcall hdfs --daemon start journalnode
#初始化hdfs
hdfs namenode -format
#单节点先启动namenode
hdfs --daemon start namenode
#其余Namenode中执行,同步Namenode
hdfs namenode -bootstrapStandby
#初始化zkfc
hdfs zkfc -formatZK
#脚本群起
hadoop.sh start
访问ui界面端口为9870确认Namenode已启动。
kafka配置
安装
#解压安装包
tar -zxvf /opt/software/kafka_2.12-3.0.0.tgz -C /opt/module
#重命名
mv kafka_2.12-3.0.0/ kafka
#进入到/opt/module/kafka目录,修改配置文件
cd config/
vim server.properties
#broker 的全局唯一编号,不能重复,只能是数字。
broker.id=0
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘 IO 的线程数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接收套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka 运行日志(数据)存放的路径,路径不需要提前创建,kafka 自动帮你创建,可以 配置多个磁盘路径,路径与路径之间可以用","分隔
log.dirs=/opt/module/kafka/datas
#topic 在当前broker 上的分区个数
num.partitions=1
#用来恢复和清理data 下数据的线程数量
num.recovery.threads.per.data.dir=1
# 每个topic 创建时的副本数,默认时 1 个副本
offsets.topic.replication.factor=1
#segment 文件保留的最长时间,超时将被删除
log.retention.hours=168
#每个 segment 文件的大小,默认最大1G
log.segment.bytes=1073741824
# 检查过期数据的时间,默认 5 分钟检查一次是否数据过期
log.retention.check.interval.ms=300000
#配置连接 Zookeeper 集群地址(在 zk 根目录下创建/kafka,方便管理)
zookeeper.connect=hadoop1:2181,hadoop2:2181,hadoop3:2181/kafka
#分发安装包
xsync kafka/
#分别在 hadoop2 hadoop3 上修改配置文件/opt/module/kafka/config/server.properties 中的 broker.id=1、broker.id=2注:broker.id不得重复,整个集群中唯一。
#配置环境变量
sudo vim /etc/profile.d/my_env.sh
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka
export PATH=$PATH:$KAFKA_HOME/bin
#刷新一下环境变量。
source /etc/profile
#分发环境变量文件到其他节点,并 source。
sudo /home/hadoop/bin/xsync /etc/profile.d/my_env.sh
#未关闭防火墙需要开放端口
xcall sudo firewall-cmd --zone=public --permanent --add-port=9092/tcp
# 并重载入添加的端口:
xcall sudo firewall-cmd --reload
# 再次查询端口开放情况,确定2888和3888开放
xcall sudo firewall-cmd --zone=public --list-ports
启动
#先启动 Zookeeper集群,然后启动Kafka。
zk.sh start
#群起集群
kf.sh start
HBase配置
安装
#解压tar包
tar -zxvf /opt/software/hbase-2.4.11-bin.tar.gz -C /opt/module
#重命名
mv hbase-2.4.11 hbase
#未关闭防火墙需要开放端口
xcall sudo firewall-cmd --zone=public --permanent --add-port=16000/tcp
xcall sudo firewall-cmd --zone=public --permanent --add-port=16010/tcp
xcall sudo firewall-cmd --zone=public --permanent --add-port=16020/tcp
xcall sudo firewall-cmd --zone=public --permanent --add-port=16030/tcp
# 并重载入添加的端口:
xcall sudo firewall-cmd --reload
# 再次查询端口开放情况,确定2888和3888开放
xcall sudo firewall-cmd --zone=public --list-ports
配置环境
hbase-env.sh
export HBASE_MANAGES_ZK=false
hbase-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop1,hadoop2,hadoop3:2181</value>
<description>The directory shared by RegionServers.
</description>
</property>
<!-- <property>-->
<!-- <name>hbase.zookeeper.property.dataDir</name>-->
<!-- <value>/export/zookeeper</value>-->
<!-- <description> 记得修改 ZK 的配置文件 -->
<!-- ZK 的信息不能保存到临时文件夹-->
<!-- </description>-->
<!-- </property>-->
<property>
<name>hbase.rootdir</name>
<value>hdfs://hadoop1:8020/hbase</value>
<description>The directory shared by RegionServers.
</description>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
</configuration>
regionservers
hadoop1
hadoop2
hadoop3
backup-masters(新建高可用HMaster备用节点文件)
插入高可用节点,不要有多余符号,直接写host
hadoop3
解决 HBase 和 Hadoop 的 log4j 兼容性问题,修改 HBase 的 jar 包,使用 Hadoop 的 jar 包
mv /opt/module/hbase/lib/client-facing-thirdparty/slf4j-reload4j-1.7.33.jar /opt/module/hbase/lib/client-facing-thirdparty/slf4j-reload4j-1.7.33.jar.bak
启动
#配置环境变量
sudo vim /etc/profile.d/my_env.sh
#HBASE_HOME
export HBASE_HOME=/opt/module/hbase
export PATH=$PATH:$HBASE_HOME/bin
#生效配置
source /etc/profile.d/my_env.sh
#分发my_env.sh
xsync /etc/profile.d/my_env.sh
#群起命令
start-hbase.sh
访问:http://hadoop1:16010查看ui界面
flink
略文章来源:https://www.toymoban.com/news/detail-772965.html
脚本大全
1、xsync
#!/bin/bash
#1. 判断参数个数
if [ $# -lt 1 ]
then
echo Not Enough Arguement!
exit;
fi
#2. 遍历集群所有机器
for host in hadoop1 hadoop2 hadoop3
do
echo ==================== $host ====================
#3. 遍历所有目录,挨个发送
for file in $@
do
#4. 判断文件是否存在
if [ -e $file ]
then
#5. 获取父目录
pdir=$(cd -P $(dirname $file); pwd)
#6. 获取当前文件的名称
fname=$(basename $file)
ssh $host "mkdir -p $pdir"
rsync -av $pdir/$fname $host:$pdir
else
echo $file does not exists!
fi
done
done
2、xcall
#!/bin/bash
# 获取控制台指令
cmd=$*
# 判断指令是否为空
if [ ! -n "$cmd" ]
then
echo "command can not be null !"
exit
fi
# 获取当前登录用户
user=`whoami`
# 在从机执行指令,这里需要根据你具体的集群情况配置,host与具体主机名一致,同上
for host in hadoop1 hadoop2 hadoop3
do
echo "================current host is $host================="
echo "--> excute command \"$cmd\""
ssh $user@$host $cmd
done
3、hadoop.sh
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hadoop1 "/opt/module/hadoop/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hadoop2 "/opt/module/hadoop/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hadoop1 "/opt/module/hadoop/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hadoop1 "/opt/module/hadoop/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hadoop2 "/opt/module/hadoop/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hadoop1 "/opt/module/hadoop/sbin/stop-dfs.sh"
;;
*)
echo "Input Args Error..."
;;
esac
4、zk.sh
#!/bin/bash
case $1 in
"start"){
for i in hadoop1 hadoop2 hadoop3
do
echo ---------- zookeeper $i 启动 ------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh start"
done
};;
"stop"){
for i in hadoop1 hadoop2 hadoop3
do
echo ---------- zookeeper $i 停止 ------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh stop"
done
};;
"status"){
for i in hadoop1 hadoop2 hadoop3
do
echo ---------- zookeeper $i 状态 ------------
ssh $i "/opt/module/zookeeper-3.5.7/bin/zkServer.sh status"
done
};;
esac
5、kf.sh
#! /bin/bash
case $1 in
"start"){
for i in hadoop1 hadoop2 hadoop3
do
echo " --------启动 $i Kafka-------"
ssh $i "/opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties"
done
};;
"stop"){
for i in hadoop1 hadoop2 hadoop3
do
echo " --------停止 $i Kafka-------"
ssh $i "/opt/module/kafka/bin/kafka-server-stop.sh "
done
};;
esac
环境变量
my_env.sh文章来源地址https://www.toymoban.com/news/detail-772965.html
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
#HADOOP_HOME
export HADOOP_HOME=/opt/ha/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
export PAHT=$PATH:/home/hadoop/bin
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka
export PATH=$PATH:$KAFKA_HOME/bin
#HBASE_HOME
export HBASE_HOME=/opt/module/hbase
export PATH=$PATH:$HBASE_HOME/bin
到了这里,关于实操Hadoop大数据高可用集群搭建(hadoop3.1.3+zookeeper3.5.7+hbase3.1.3+kafka2.12)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!