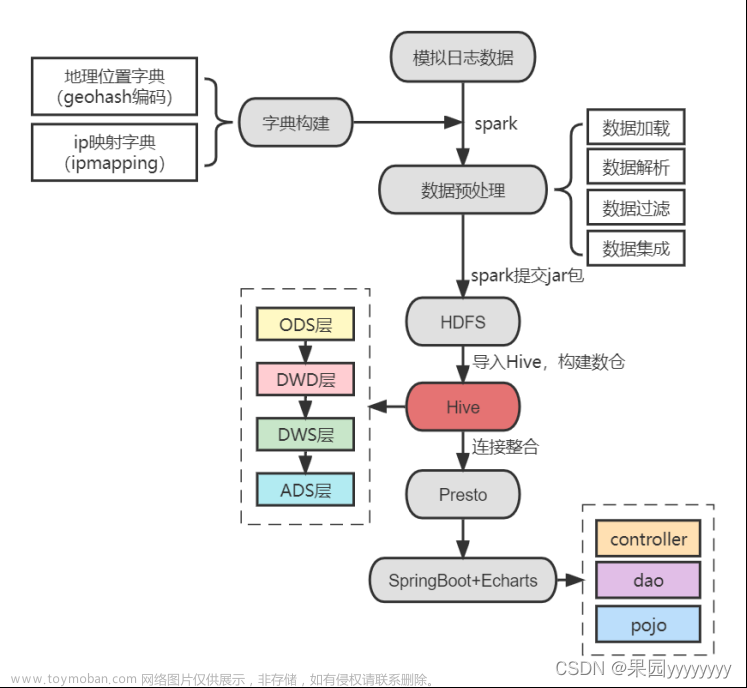
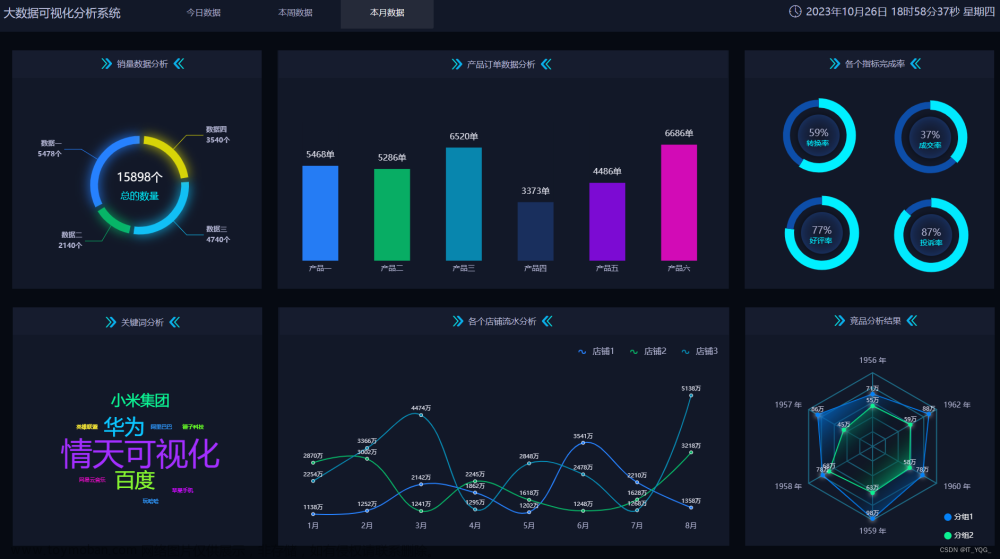
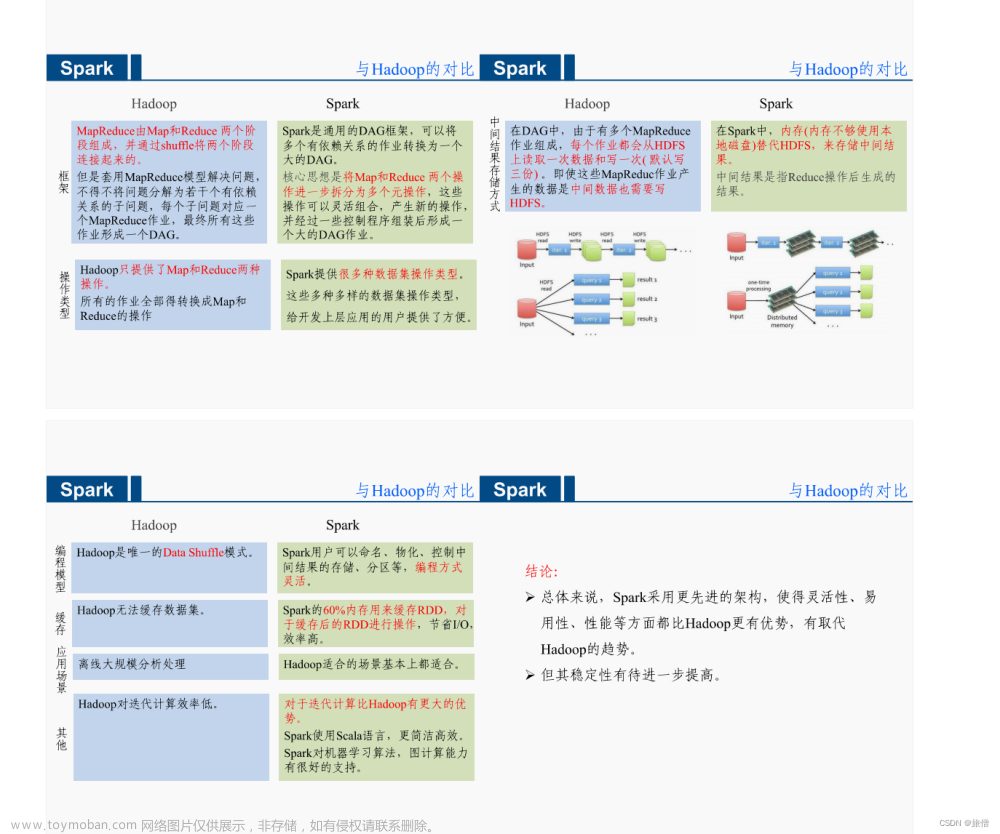
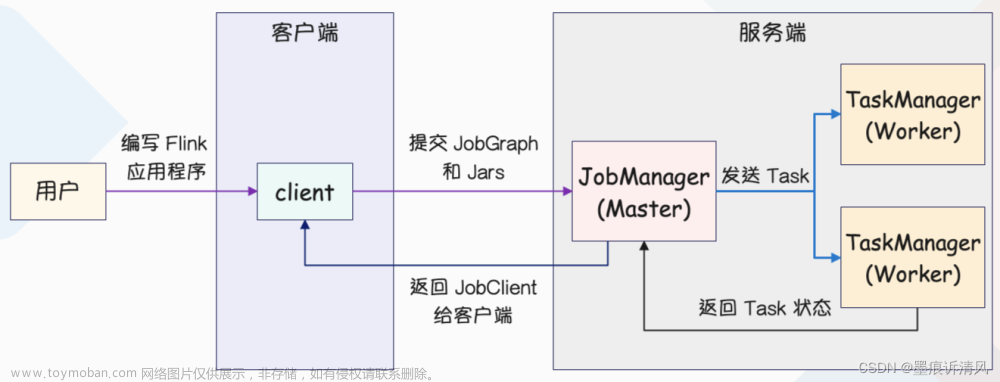
Hadoop
- 表达能力有限。
- 磁盘IO开销大,延迟度高。
- 任务和任务之间的衔接涉及IO开销。
- 前一个任务完成之前其他任务无法完成,难以胜任复杂、多阶段的计算任务。
Spark
-
Spark模型是对Mapreduce模型的改进,可以说没有HDFS、Mapreduce就没有Spark。
-
Spark可以使用Yarn作为他的资源管理器,并且可以处理HDFS数据。这对于已经部署了Hadoop集群的用户特别重要,因为他们不需要任何的数据迁移就可以使用到spark的强大功能了。 文章来源:https://www.toymoban.com/news/detail-773014.html
 文章来源地址https://www.toymoban.com/news/detail-773014.html
文章来源地址https://www.toymoban.com/news/detail-773014.html
到了这里,关于Hadoop和Spark的区别的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!