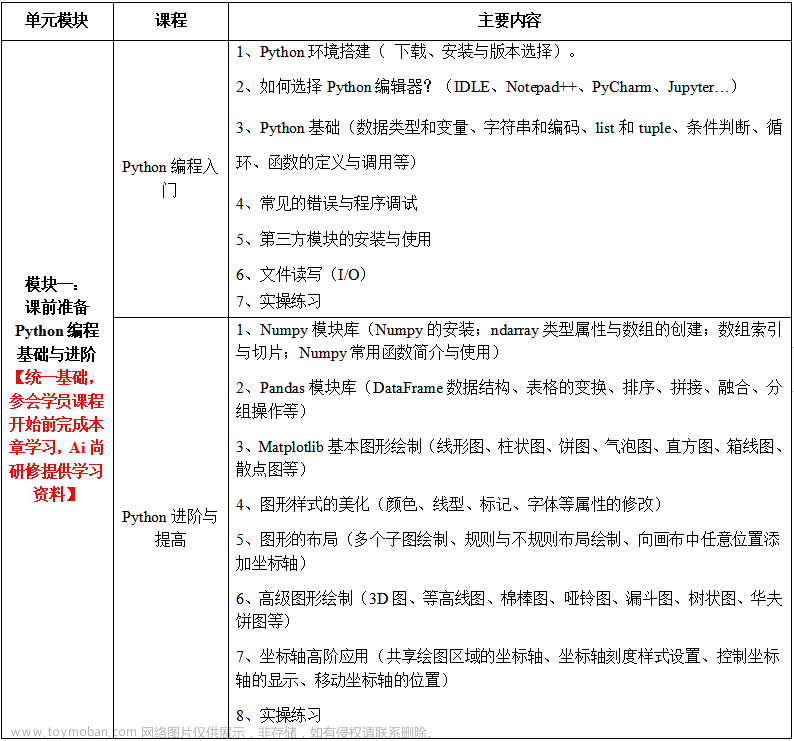
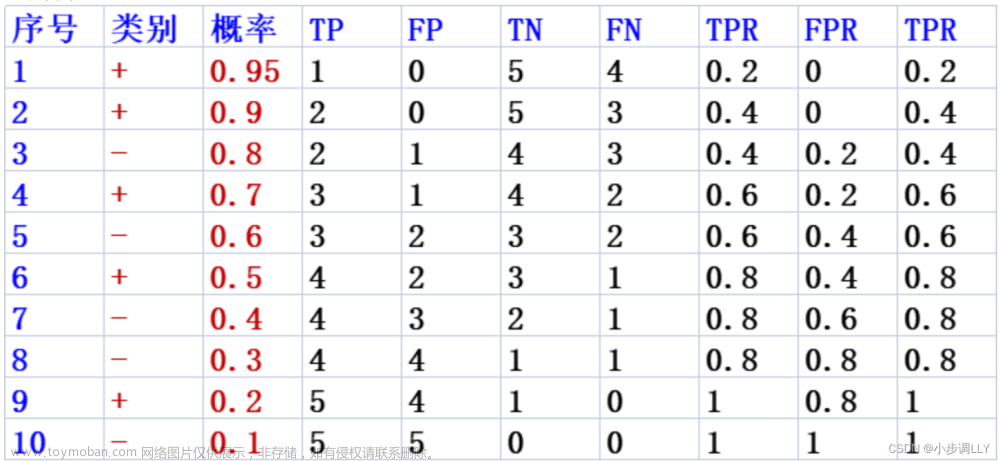
模型融合是指将多个不同的机器学习模型组合起来,通过综合多个模型的预测结果来得到更准确的预测结果。模型融合可以提高模型的鲁棒性,减小模型的方差,提高模型的泛化能力。
常见的模型融合方法包括平均法、投票法和堆叠法。
-
平均法(Averaging):将多个模型的预测结果进行平均,可以是简单的算术平均或加权平均。平均法适用于模型预测结果的方差较小的情况。
-
投票法(Voting):根据多个模型的预测结果,统计出现频率最高的预测结果作为最终的预测结果。投票法适用于模型预测结果的方差较大的情况。有简单投票法,加权投票法,硬投票法。
-
堆叠法(stacking/blending):将多个模型的预测结果作为输入,训练一个新的模型来得到最终的预测结果。堆叠法可以将不同模型的优点结合起来,提高预测准确度。stacking是构建多层模型,并利用预测结果再做拟合预测;blending是选取部分数据预测训练得到预测结果作为新特征,带入剩下的数据中预测。blending只有一层,而stacking有多层。
-
综合法:有排序融合,log融合
-
boosting/bagging:树分类的提升方法,在xgboost,Adaboost,GBDT中已经用到文章来源:https://www.toymoban.com/news/detail-773074.html
在进行模型融合时,需要注意选择不同模型之间具有较低的相关性,避免多个模型预测结果的冗余。同时,还需要根据具体问题选择适当的模型融合方法。文章来源地址https://www.toymoban.com/news/detail-773074.html
到了这里,关于【数据挖掘】模型融合的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!