话不多说,先看视频
1. AnimateDiff的技术原理
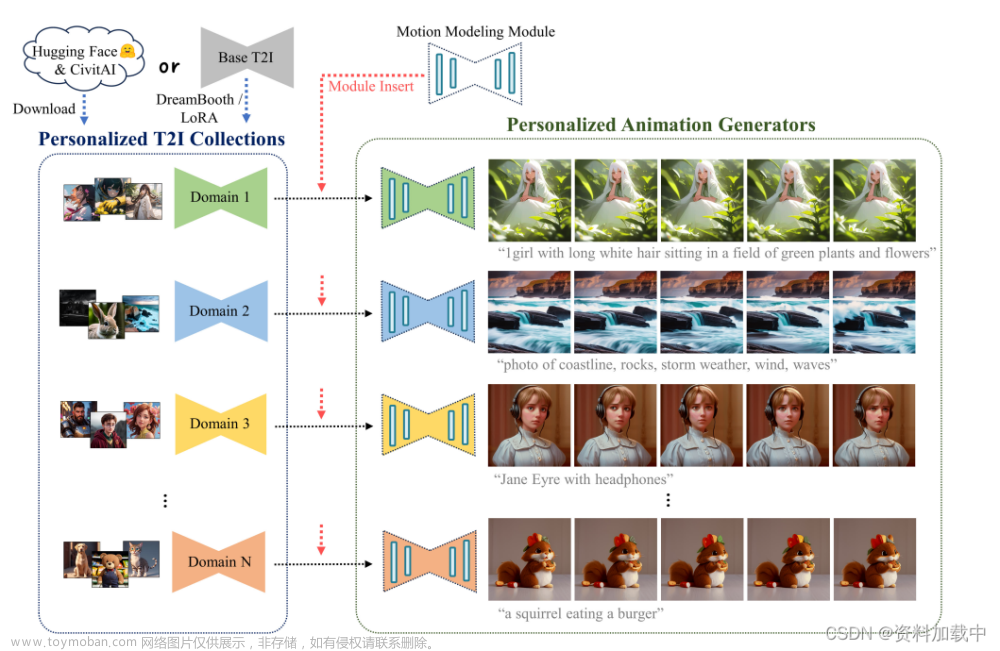
AnimateDiff可以搭配扩散模型算法(Stable Diffusion)来生成高质量的动态视频,其中动态模型(Motion Models)用来实时跟踪人物的动作以及画面的改变。我们使用 AnimaeDiff 实现时间一致性,使用ControlNet复制参考视频的运动,然后改变不同时间点的提示prompt,打造多种场景再组合成视频。它克服了 AnimateDiff 运动不佳的弱点,并保持了较高的帧间一致性。工作流程文件执行的操作为1.将视频作为输入。2.将OpenPose预处理器应用于视频帧以提取人体姿势。3.将AnimateDiff运动模型和ControlNet Openpose 控制模型应用于每个帧。4.支持提示行进,为不同的帧指定不同的提示。5.保存最终视频。
2.软件安装
我们使用ComfyUI来搭配AnimateDiff做视频转视频的工作流,软件地址如下:ComfyUI:https://github.com/comfyanonymous/ComfyUIAnimateDiff:https://github.com/guoyww/AnimateDiff
3.ComfyUI AnimateDiff视频转视频工作流
步骤1:加载工作流程文件。直接把下面这张图拖入ComfyUI界面,它会自动载入工作流,或者下载这个工作流的JSON文件,在ComfyUI里面载入文件信息。

步骤 2:安装缺少的节点第一次载入这个工作流之后,ComfyUI可能会提示有node组件未被发现,我们需要通过ComfyUI manager安装,它会自动找到缺失的组件并下载安装(!!需要网络通畅)。


重新启动 ComfyUI 并单击队列提示。如果不再看到 ComfyUI 提示缺少节点,则可以继续执行下一步。步骤 3:下载checkpoint 模型下载模型DreamShaper 8。将safetensors文件放入文件夹ComfyUI > models > checkpoints中。刷新浏览器标签页。 找到节点“Load Checkpoint”。

点击ckpt_name下拉菜单,选择dreamshaper_8模型。当然,你也可以使用不同的模型。
步骤4:选择 VAE。下载Stability AI发布的VAE 。将文件放入文件夹ComfyUI > models > vae中。刷新浏览器页面。在“加载 VAE”节点中,选择刚刚下载的文件。

步骤5:下载AnimateDiff动态特征模型下载mm_sd_v15_v2.ckpt,放到ComfyUI > custom_nodes > ComfyUI-AnimateDiff-Evolved > models文件夹。刷新页面在AnimateDiff Loader里,可以选择我们需要的动态特征模型

步骤6:选择Openpose ControlNet模型下载openpose ControlNet 模型。将文件放入ComfyUI > models > controlnet中。刷新 ComfyUI 页面。在加载 ControlNet 模型(高级)中,在下拉菜单中选择control_v11p_sd15_openpose.pth 。

步骤7:在加载视频(上传)节点中,单击视频并选择刚刚下载的视频。

步骤8:生成视频可以点击Queue Prompt开始生成视频了视频生成的大部分时间都集中在KSampler这个组件里,在生成过程中上面有一个进度条
4. 调优
4.1生成不同的视频。更改种子值以生成不同的视频。

4.2 更改提示前缀和提示行即可更改主题和背景。
 文章来源:https://www.toymoban.com/news/detail-773362.html
文章来源:https://www.toymoban.com/news/detail-773362.html
 文章来源地址https://www.toymoban.com/news/detail-773362.html
文章来源地址https://www.toymoban.com/news/detail-773362.html
到了这里,关于AnimateDiff搭配Stable diffution制作AI视频的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!