前言
在进行数据爬取时,有时候遇到一些比较复杂的js逆向。在不考虑访问效率的情况下,使用selenium模拟浏览器的方法可以大大减少反反爬逆向工作量。但普通的selenium库是无法获取到类似set-cookie等参数的,这时候需要用到selenium-wire库。其用法类似selenium
一、安装
首先安装selenium-wire库
pip install selenium-wire

然后下载指定的chromedriver,根据电脑上的chrome版本进行下载
chromedriver下载地址
二、简易使用
from seleniumwire import webdriver
driver = webdriver.Chrome(executable_path='chromedriver.exe')
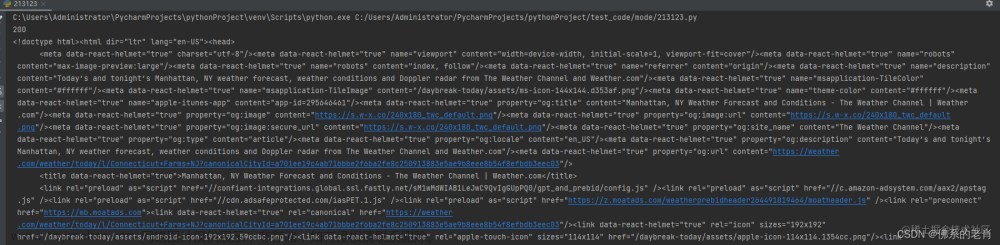
driver.get('https://www.baidu.com')
即可看到如下界面:
如果出现报错说chromedriver版本不匹配,并且提示了本地电脑上的chrome版本,则回到chromedriver下载地址下载相对应版本
三、加入参数
1. 隐藏浏览器窗口
如果要让浏览器窗口不显示而在后台允许,加入headless参数:
options = webdriver.ChromeOptions()
options.add_argument("--headless")
driver = webdriver.Chrome(executable_path='chromedriver.exe', options=options)
2. 添加cookies
使用add_cookie方法可以添加cookie,一次添加一个name和value
cookie = {
'browserid': '12345678910',
'_ga': '12345678910',
'sessionid': '12345678910',
}
for name, value in cookie.items():
driver.add_cookie({"name": name, "value": value, "domain": "baidu.com"})
driver.get('https://www.baidu.com')
此处可能会报错:
解决的办法是在add_cookie前先get一次
driver.get('https://www.baidu.com')
cookie = {
'browserid': '12345678910',
'_ga': '12345678910',
'sessionid': '12345678910',
}
for name, value in cookie.items():
driver.add_cookie({"name": name, "value": value, "domain": "baidu.com"})
driver.get('https://www.baidu.com')
之后即可成功访问并设置cookie,效果如下:
四、使用代理
有时候需要访问的网站需要科学上网,这时候需要为driver设置代理才能正常访问
代理设置为你自己的代理端口,我的是127.0.0.1:7890:
seleniumwire_options = {
'proxy': {
'http': 'http://127.0.0.1:7890',
'https': 'https://127.0.0.1:7890'
}
}
# 注意是seleniumwire_options而不是options
driver = webdriver.Chrome(executable_path='chromedriver.exe', seleniumwire_options=seleniumwire_options)
driver.get('https://www.youtube.com')
这时就可以正常访问某些网站了
五、获取cookies等参数
使用get_cookies方法即可获取到访问过程中网页set的cookie值
for item in driver.get_cookies():
print(item)
将输出类似如下结果:
也可以遍历requests获取所有访问历史的详情
for request in driver.requests:
print(request.url)
print(request.headers)
print(request.response)
可以看到每个访问: 文章来源:https://www.toymoban.com/news/detail-774247.html
文章来源:https://www.toymoban.com/news/detail-774247.html
总结
以上就是使用python selenium-wire库的一些简单使用方法。希望对大家有所帮助文章来源地址https://www.toymoban.com/news/detail-774247.html
到了这里,关于python爬虫-seleniumwire模拟浏览器反爬获取参数的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![[爬虫]2.2.1 使用Selenium库模拟浏览器操作](https://imgs.yssmx.com/Uploads/2024/02/594545-1.jpg)