概述
当我们在使用缓存时,如果发生数据变更,那么你需要同时操作缓存和数据库,而它们两个又分属不同的系统,因此无法做到同时操作成功或失败,因此在并发读写下很可能出现缓存与数据库数据不一致的情况
理论上可以通过分布式事务保证同时操作成功或失败,但这会影响系统性能,一般很少使用。虽然没办法做到缓存和数据库强一致,但我们可以让他们的数据尽可能在绝大部分时间内保持一致,并保证最终是一致的
缓存更新设计
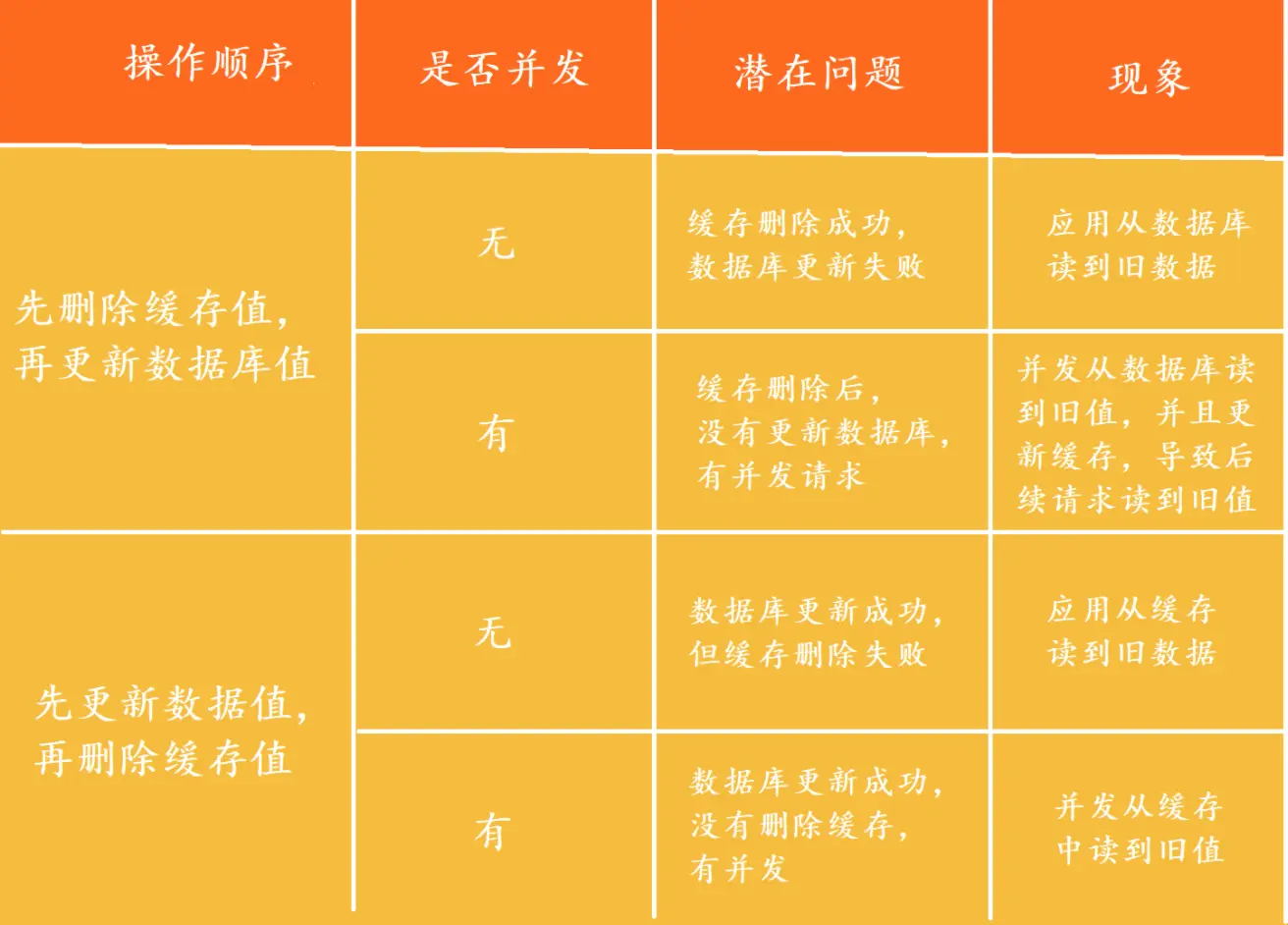
一般来说都是采用删除缓存的方式更新缓存,这就涉及到先删除缓存还是先更新数据库的顺序问题了
1. 先删除缓存,后更新数据库
先删除缓存,后更新数据库,如果数据库没有更新成功,下次读缓存发现不存在,则从数据库读取,并重建缓存,此时数据库和缓存依旧保持一致,但还是旧值
高并发下,假设有两个线程并发读写数据,可能会发生以下场景:
- 线程 A 要更新 X = 2(原值 X = 1)
- 线程 A 先删除缓存
- 线程 B 读缓存,发现不存在,从数据库中读取到旧值(X = 1)
- 线程 A 将新值写入数据库(X = 2)
- 线程 B 将旧值写入缓存(X = 1)
- 最终 X 的值在缓存中是 1(旧值),在数据库中是 2(新值),发生不一致
可见,在高并发下这种方式容易出现长时间的脏数据,一般不建议使用
2. 先更新数据库,后删除缓存
先更新数据库,后删除缓存,如果缓存没有删除成功,数据库是最新值,缓存中是旧值,会发生不一致
再看两个线程并发读写数据:
- 某一时刻缓存中 X 失效不存在(数据库 X = 1)
- 线程 A 读取数据库,得到旧值(X = 1)
- 线程 B 更新数据库(X = 2)
- 线程 B 删除缓存
- 线程 A 将旧值写入缓存(X = 1)
- 最终 X 的值在缓存中是 1(旧值),在数据库中是 2(新值),发生不一致
这种方式依旧会出现数据不一致,但概率很低,所以普遍采用这种方式
更多优化
通过前面分析,我们采用了先更新数据库,再删除缓存的方式,还可以进一步优化
1. 保证两步都执行成功
前面提到,无论采用哪种方式,只要第二步失败都会有问题,所以我们需要保证第二步成功执行
一种简单的办法是失败就重试,但这会占用资源,并且立即重试大概率还是失败,所以可以采用异步重试,就是把重试请求写到消息队列,由专门的消费者来重试,直到成功
或者更直接的做法,为了避免第二步执行失败,我们可以把操作缓存这一步,直接放到消息队列中,由消费者来操作缓存,这样做的好处是即使系统重启了,消息也不会丢失
也可以通过订阅数据库变更日志,再操作缓存的方式,以 MySQL 举例,当一条数据发生修改时,MySQL 就会产生一条变更日志(Binlog),我们可以订阅这个日志,拿到具体操作的数据,然后再根据这条数据,去删除对应的缓存。订阅变更日志,目前也有了比较成熟的开源中间件,例如阿里的 canal
2. 延迟双删
一般数据库会使用【主从复制 + 读写分离】提高性能,这种情况下也有可能出现数据不一致:文章来源:https://www.toymoban.com/news/detail-774465.html
- 线程 A 更新主库 X = 2(原值 X = 1)
- 线程 A 删除缓存
- 线程 B 查询缓存,没有命中,查询「从库」得到旧值(从库 X = 1)
- 从库「同步」完成(主从库 X = 2)
- 线程 B 将「旧值」写入缓存(X = 1)
- 最终 X 的值在缓存中是 1(旧值),在主从库中是 2(新值),也发生不一致
解决办法就是延时双删,比如线程 A 在更新数据库并删除缓存后,延迟一段时间再删除一次,延迟时间取决于主从复制的延迟时间,一般凭经验估算 1s - 5s 左右文章来源地址https://www.toymoban.com/news/detail-774465.html
到了这里,关于Redis 数据一致性的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!