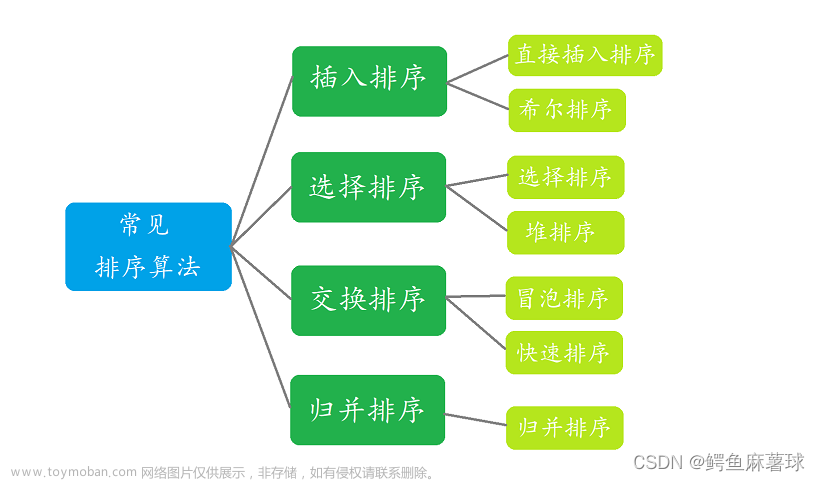
- 一、前言
-
二、选择排序
- 2.1 选择排序(基础版)【必会】
- 2.2 选择排序(优化版)
-
三、冒泡排序
- 3.1 冒泡排序(基础版)【必会】
- 3.2 冒泡排序(外循环优化版)
- 3.3 冒泡排序(内循环优化版)
- 四、总结
一、前言🍖
排序法主要分为两种:比较排序和非比较排序。常见的比较排序有:选择排序、冒泡排序、插入排序、归并排序、堆排序、快速排序等。而比较排序是通过两两元素之间的比较来排序的,每个元素都必须和其他元素进行比较才能确定自己的位置。至于常见的非比较排序有:计数排序、基数排序、桶排序等。而非比较排序是通过确定每个元素之前应该有多少个元素来排序的。(这一期只讲解其中的两种排序,其他的留到以后再讲,我会建立一个关于“排序算法”的专栏,以后如果想看其他的排序可以去这个专栏里找)
相信只要接触过C语言的同学都或多或少了解排序问题,而最基本且最为人所熟知的应该是下面这两种排序:选择排序、冒泡排序(因为这就是基础啊,只要学《C语言》这门课的期末考试就必然会考到)。但我想就算在学校听老师讲过一遍之后,还是会有一些同学对这两种排序的实现模棱两可。下面我会带着大家重新把这两种排序方法走一遍,使你能够透彻的理解这两种算法的原理,能把它们清晰的区分开,并且分别实现这两种排序的算法优化。
二、选择排序🍖

选择排序是一种简单且直观的排序算法。它的工作原理是:第一趟先从待排序的数据元素种选出最小(或最大)的一个元素,存放在序列的起始位置;然后第二趟再从剩余未查找的元素中寻找最大(或最小)元素放置在该次序列的首位。以此类推,每一趟都可以向前放置一个最小(或最大)元素,直至只剩下两个元素未被排序,这时是不是只需要再进行一趟排序就可以使得整个序列有序。所以从这里我们可以知道:选择排序的趟数是由元素个数来决定的,若现在有n个元素要对其进行排序,那只需要进行n-1趟就好了,如上图所示。
还有一点值得注意的是:在选择排序中,每趟都会选出最大元素与最小元素,然后与两端元素交换。若此时,待排序序列中如果存在与原来两端元素相等的元素,稳定性就可能被破坏。如[5,3,5,2,9],在array[0]与array[3]元素交换时,序列的稳定性就被破坏了,所以选择排序是一种不稳定的排序算法。
2.1 选择排序(基础版)【必会】🍖
就如面所讲的就是选择排序最基本的算法,下面就举个例子:现有个序列6、7、5、1、4、3、8 ,请将他们进行从小到大依次排序。注意:选择排序是用两层for循环嵌套来实现的,第一层for循是环是对趟数控制,第二层for循环是对比较的次数的控制,而每一趟走下来都能使一个元素找到对应位置,执行(n-1)趟后就可以完成排序,一定记住!!!
代码如下:
#include<stdio.h>
void Swap(int* parr, int min, int i)
{
int tmp = parr[min];
parr[min] = parr[i];
parr[i] = tmp;
}
void sel_sort(int* parr, int n)
{
int i = 0;
//每一趟都可以确定一个最小数值,然后把其放到该趟的最前面的下标底下。
//下一趟从前一趟的最小值下标后一个下标开始进行
for (i = 0; i < n - 1; i++)//总的比较的趟数
{
int j = 0;
//先假设前面的元素为最小元素的下标
int min = i;
//每趟比较,将前面的元素与其后的元素逐个比较
for (j = i + 1; j < n; j++)
{
if (parr[j] < parr[min])
{
//min变量保存该趟比较过程中,最小元素所对应的数组下标
min = j;
}
}
//交换此次查到的最小值和原最小值
Swap(parr, min, i);
}
}
int main()
{
int i = 0;
int arr[] = { 6,7,5,3,4,1,8 };
int sz = sizeof(arr) / sizeof(arr[0]);//求数组元素个数
sel_sort(arr, sz);//选择排序
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
}

2.2 选择排序(优化版)🍖
选择排序的优化思路一般是在一趟遍历中,同时找出最大值与最小值,放到数组两端,这样就能将遍历的趟数减少一半。过程如下:
这样每次找出最大值与最小值放到数组两端后,left和right会靠的越来越近。如果还像上边那样执行(n-1)趟的话left和right必然会交错,但这里完全没有必要执行(n-1)趟,因为把left<right的所有情况走完数组就已经有序排列了,完全没有必要把后面left>=right的情况再走一遍。程序如下:
#include<stdio.h>
void Swap(int* arr, int x, int y)
{
int tmp = arr[x];
arr[x] = arr[y];
arr[y] = tmp;
}
void sel_sort(int* arr, int num)
{
int left = 0;
int right = num - 1;
while (left < right)
{
//先假设最左侧元素的下标未为最小元素的下标,最右侧元素的下标为最大元素的下标。
int min = left;
int max = right;
int i = 0;
for (i = left; i <= right; i++)
{
if (arr[i] < arr[min])
{
min = i;
}
if (arr[i] > arr[max])
{
max = i;
}
}
//最大值放在最右端
Swap(arr, max, right);
//由于上一步把下标(right)和(max)上的数据进行了交换
//所以得考虑最小值(arr[min])在位置(right)的情况,即:此时的 min = right;
if (min == right)
{
min = max;
}
//最小值放在最左端
Swap(arr, min, left);
//每趟遍历,元素总个数减少2,左右端各减少1,left和right索引分别向内移动1
left++;
right--;
}
}
int main()
{
int i = 0;
int arr[] = { 3,5,9,2,4,7 };
int sz = sizeof(arr) / sizeof(arr[0]);//计算数组元素个数
sel_sort(arr, sz);//选择排序
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}

三、冒泡排序🍖

冒泡排序是比较基础的排序算法之一,其核心思想是相邻的元素两两比较。但与选择排序不同的是,冒泡排序每一趟走下来不仅可以得到一个最大(或最小)的元素,还能使得数列中较大的数下沉,较小的数冒起来。如此走下去,数列必然在n-1趟之前就基本可以做到有序,可见冒泡排序的效率是高于选择排序的。纵观整个排序过程你会发现数列中的元素就如同气泡和水一样,大的下沉小的冒起,所以该排序才会被生动形象的称作冒泡排序,如上图所示。
值得注意的是:在冒泡排序中,遇到相等的值,是不进行交换的,只有遇到不相等的值才进行交换,所以是稳定的排序方式。
3.1 冒泡排序基础版【必会】🍖
就如上面所说的冒泡排序每趟会排好一个元素,且使得这次数列中大数下沉小数冒起。排序中将执行n-1趟,每趟会比较n-1次,所以和比较排序一样用两个嵌套的for循环来实现就行了。如下图所示:
实现程序如下:
#include<stdio.h>
void bubble_sort(int* arr, int num)
{
int i = 0;
//该循环决定趟数
for (i = 0; i < num - 1; i++)
{
int j = 0;
//该循环决定每趟中元素比较的次数
for (j = 0; j < num - 1 - i; j++)
{
if (arr[j] > arr[j + 1])
{
//交换两元素
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
}
}
}
}
int main()
{
int i = 0;
int arr[] = { 6,7,5,3,4,1,8 };
int sz = sizeof(arr) / sizeof(arr[0]);//计算数组元素的个数
bubble_sort(arr, sz);//冒泡排序
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}

3.2 冒泡排序(外循环优化版)🍖
如果逐语句的走一遍冒泡排序案例后,你必然会发现很多时候冒泡排序压根就不需要执行n-1趟,排序有时可能仅仅只需要执行一趟就可以使得整个序列有序,就如下图所示的案例:

那我们该怎么做才能使得排序时不用重复那么多趟呢?也就是说:若整个序列达到了有序但趟数还没有达到n-1趟时,剩下的趟数就被必要执行了。那程序上该怎么改进呢?其实也不难,只需加一个bool变量来判断整个序列是否有序就行,若达到有效就直接退出循环。下面是代码:
#include<stdbool.h>
void bubble_sort(int* arr, int num)
{
int i = 0;
//该循环决定趟数
for (i = 0; i < num - 1; i++)
{
bool flag = true;
int j = 0;
//该循环决定每趟中元素比较的次数
for (j = 0; j < num - 1 - i; j++)
{
if (arr[j] > arr[j + 1])
{
//交换两元素
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
flag = false;
}
}
//判断整个数组是否有序
//若flag=true则表示数组已经有序,否则表示数组还是无序的;
if (flag)
{
break;
}
}
}
int main()
{
int i = 0;
int arr[] = { 6,7,5,3,4,1,8 };
int sz = sizeof(arr) / sizeof(arr[0]);//计算数组元素的个数
bubble_sort(arr, sz);//冒泡排序
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}

3.3 冒泡排序(内循环优化版)🍖
冒泡排序经过上面的优化后,其实还是存在着一些不必要的比较动作。因为按照现有的逻辑,有序区的长度和排序的轮数是相等的。比如第一轮排序过后的有序区长度是1,第二轮排序过后的有序区长度是2 ……但实际上,数列真正的有序区可能会大于这个长度,比如下图所示的这个前半段无序后半段有序的例子。
如果还是按照上面的方法来排序,那每一趟都必然执行 n-1-i 次的比较,但其实用不到那么多次,因为后面的5、6、7、8已然有序还去比它干神马?这是毫无意义的事。那该如何避免这种情况呢?其实可以在每一趟排序中记录下最后一次元素交换的位置,那个位置也就是无序数列的边界(再往后就是有序区了),然后通过这个位置就避免无意义的比较了。但还是有同学会有质疑:你这举得例子不全面啊,前半段数列里全是要比后半段序列小的元素。如果把上图中的元素3改成9那还能实现该功能吗?当然可以,你可别捡了芝麻丢了西瓜,别死抓着这里数列后半段为有序的这个观点,而忘了冒泡排序的每一趟都可以把一个最大的元素放置到最后!!!
下面是代码:
#include<stdio.h>
#include<stdbool.h>
void bubble_sort(int* arr, int num)
{
int i = 0;
//该循环决定趟数
for (i = 0; i < num - 1; i++)
{
bool flag = true;
int j = 0;
//无序数组的边界,每次比较只需比较到此为止
int border = num - 1;
//记录最后一次交换位置
int position = 0;
//该循环决定每趟中元素比较的次数
for (j = 0; j < border; j++)
{
if (arr[j] > arr[j + 1])
{
//交换两元素
int tmp = arr[j];
arr[j] = arr[j + 1];
arr[j + 1] = tmp;
flag = false;
//把无序数列的边界更新为最后一次交换元素的位置
position = j;
}
}
border = position;//最后的位置就是无序数组的边界
//判断整个数组是否有序
//若flag=true则表示数组已经有序,否则表示数组还是无序的;
if (flag)
{
break;
}
}
}
int main()
{
int i = 0;
int arr[] = { 9,3,4,2,1,5,6,7,8 };
int sz = sizeof(arr) / sizeof(arr[0]);//计算数组元素的个数
bubble_sort(arr, sz);//冒泡排序
for (i = 0; i < sz; i++)
{
printf("%d ", arr[i]);
}
return 0;
}

四、总结🍖
相信坚持看完本期关于比较排序和冒泡排序博客的同学,必然会对这两种排序算法有了深刻的认知;并且拓展到了新的知识点,学会如何去优化这两种排序的算法。如果还想了解关于其他的排序算法,请期待小编我下一次的更新吧=_=!!!
 文章来源:https://www.toymoban.com/news/detail-774634.html
文章来源:https://www.toymoban.com/news/detail-774634.html
这份博客👍如果对你有帮助,给博主一个免费的点赞以示鼓励欢迎各位🔎点赞👍评论收藏⭐️,谢谢!!!
如果有什么疑问或不同的见解,欢迎评论区留言欧👀。文章来源地址https://www.toymoban.com/news/detail-774634.html
到了这里,关于两个基本排序算法【选择排序,冒泡排序】【详解】的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!