前言
链表是一种常见的数据结构,它可以用来存储一组数据,并支持快速的插入和删除操作。相比于数组,链表的大小可以动态地增加或减小,因此在某些场景下更加灵活和高效。本文将详细介绍链表的定义、基本操作和应用场景,希望能够帮助读者深入理解链表的原理和实现。
链表的定义
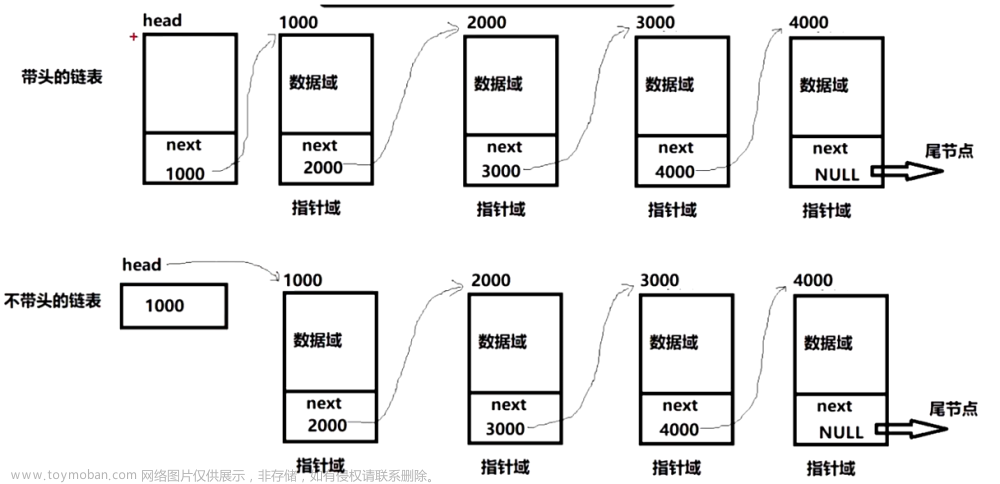
链表是一种线性数据结构,它由一系列节点组成,每个节点包含一个数据元素和一个指向下一个节点的指针。链表中的节点可以在内存中任意位置,因此它们不必按照顺序连续存储。链表的头节点是第一个节点,尾节点是最后一个节点,它们分别由指向第一个节点和最后一个节点的指针来表示。
链表可以分为单向链表、双向链表和循环链表三种类型。单向链表每个节点只有一个指向下一个节点的指针,双向链表每个节点有一个指向前一个节点和一个指向后一个节点的指针,循环链表的尾节点指向头节点,形成一个环形结构。
以下是单向链表的定义:
//构造链表节点
struct Node
{
int data;//数据域,存储数据
struct Node *next;//指针域,存储下一个的地址
};单向链表的创建
//创建单向链表
struct Node * create()
{
//创建空链表
//头结点
//malloc 创建头结点,返回值就是结点的地址,得到头结点的地址
//使用头指针,就可以操作链表
struct Node * head = malloc(sizeof(struct Node));//使用malloc分配链表节点空间,并返回地址指针
head->next = NULL;//设定头结点的next指针为NULL,初始值
return head;
}链表的基本操作
链表支持的基本操作包括插入、删除、查找和遍历。下面分别介绍这些操作的实现方法。
插入操作
链表的插入操作可以分为在头部插入、在尾部插入和在中间插入三种情况。以单向链表为例,它们的实现方法如下:
- 在头部插入:新节点的指针指向原来的头节点,将新节点设置为头节点即可。
- 在尾部插入:遍历链表找到尾节点,将尾节点的指针指向新节点,将新节点设置为尾节点即可。
- 在中间插入:遍历链表找到插入位置的前一个节点,将新节点的指针指向插入位置的后一个节点,将插入位置的前一个节点的指针指向新节点即可。
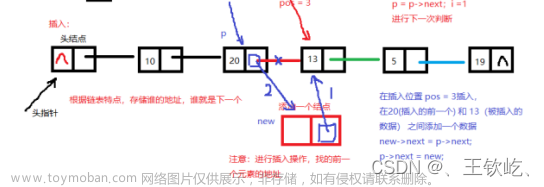
示例代码(任何位置进行插入):
//链表插入结点,参数:链表(链表头指针),插入位置,插入值
void insert(struct Node *head,int pos,int data)
{
//找到pos-1位置:pos-1这个结点的地址
struct Node *p = head;
int i = 0;
while(p->next != NULL)
{
if(i == pos-1)
{
break;
}
p = p->next;
i++;
}
//如果没找到 p 是最后一个结点的地址
//如果找到 p 就是结点位置
//插入
//创建新结点
struct Node *new = malloc(sizeof(struct Node));
new->data = data;
//设置新结点的下一个结点是谁
new->next = p->next;
//设置前一个结点p存储新结点
p->next = new;
}上述代码中,通过传入链表地址,要插入的位置,数据来进行链表的插入,由于链表特性是离散的(即所存储的数据是不确定的),故不需要向顺序表插入时需要判断是否空间满的情况,只需要查看所插入位置是否存在即可(不存在时直接在尾部插入)。故使用循环操作找到要插入位置的前一个后,进行插入,先设置新结点的下一个结点(即原链表中插入位置所在结点),再设置前一个结点存储新结点。
删除操作
链表的删除操作可以分为删除头节点、删除尾节点和删除中间节点三种情况。以单向链表为例,它们的实现方法如下:
- 删除头节点:将头节点的指针指向下一个节点,释放原来的头节点即可。
- 删除尾节点:遍历链表找到尾节点的前一个节点,将其指针指向空,释放原来的尾节点即可。
- 删除中间节点:遍历链表找到要删除的节点的前一个节点,将其指针指向要删除的节点的后一个节点,释放要删除的节点即可。

示例代码(任何位置进行删除):
//删除链表元素(以传入的位置进行删除)
void delete_link(struct Node *head,int pos)
{
if(head->next == NULL)//判断链表是否为空
{
printf("链表为空\n");
return;//函数为无返回值,故只需要return就行,不能带值
}
struct Node *p = head;
int i = 0;
//找到pos-1位置:pos-1这个结点的地址
while(p->next != NULL)
{
if(i == pos-1)
{
break;
}
p = p->next;
i++;
//改为删除指定元素,要找到删除元素的前一个地址
//如果当前位置的下一个元素 == 要删除元素
}
//判断不是最后一个,是找到了前一个位置
if(p->next == NULL)
{
printf("没有位置");
return ;
}
//删除操作
struct Node *q = p->next;//创建一个新结点,来存储要删除结点,便于后续空间的释放
p->next = q->next;
printf("删除元素:%d\n",q->data);
free(q);
}上述代码中,函数接收一个指向链表头结点的指针 head 和一个要删除的位置 pos。如果链表为空,直接输出提示信息并返回。接着,定义一个指向头结点的指针 p,并初始化一个计数器 i。通过循环遍历链表,找到要删除的位置的前一个位置,即第 pos-1 个位置。如果找到了,跳出循环;如果循环结束后还没有找到,说明链表中没有这个位置,输出提示信息并返回。
接下来,定义一个指向要删除结点的指针 q,并将其指向要删除的位置。将要删除位置的前一个位置的 next 指针指向要删除位置的下一个位置,即实现了删除操作。最后,输出被删除元素的值,并释放 q 所指向的内存空间,防止内存泄漏。
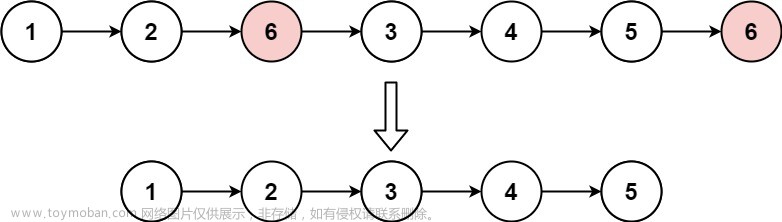
除了一个结点一个结点的删除,还可以将整个链表都删除。
示例代码(删除链表结点,只留下头结点):
//删除链表结点,只剩下头结点
void link_delete(struct Node *head)
{
struct Node *p = head;
while(p->next != NULL)
{
p = p->next;
printf("%d ",p->data);
free(head);
head = p;
}
printf("\n");
}函数接收一个指向链表头结点的指针 head。定义一个指向头结点的指针 p,并通过循环遍历链表,将 p 指向链表中的每个结点。在循环中,输出当前结点的值,并释放头结点 head 所指向的内存空间。因为链表中的每个结点都是通过动态内存分配得到的,所以需要释放每个结点所占用的内存空间,防止内存泄漏。最后,将头结点 head 指向当前结点 p,以便下一次循环。
需要注意的是,这段代码中只释放了每个结点的内存空间,但没有释放头结点 head 所占用的内存空间。如果不释放头结点所占用的内存空间,就会出现内存泄漏的问题。因此,在函数结束时,应该释放头结点 head 所占用的内存空间。
示例代码(删除链表所有结点包括头结点):
//删除所有结点包括头结点
void link_delete(struct Node *head)
{
struct Node *p = head;
while(p != NULL)
{
head = p->next;
printf("%d ",p->data);
free(p);
p = head;
}
printf("\n");
}
在循环中,先将头结点 head 的下一个结点赋值给 p,然后释放头结点 head 所指向的内存空间,并将头结点指针 head 指向下一个结点。这样就可以释放链表中每个结点所占用的内存空间,包括头结点。最后,输出换行符以便下一行输出。
查找操作
链表的查找操作可以通过遍历链表来实现。以单向链表为例,它的实现方法如下:
- 查找节点:从头节点开始遍历链表,依次比较每个节点的数据元素是否等于目标元素,如果找到了目标元素则返回该节点的指针,否则返回空指针。

示例代码:
//查找结点
void search(struct Node *head,int data)
{
struct Node *p = head;
while((p->next != NULL)&&(p->next->data != data))
{
p = p->next;
}
if(p->next == NULL)
{
printf("该位置不存在\n");
return;
}
printf("该数据%d存在\n",p->next->data);
}在上述代码中,函数接收一个指向链表头结点的指针 head 和一个要查找的值 data。定义一个指向头结点的指针 p,并通过循环遍历链表,将 p 指向链表中的每个结点。在循环中,如果当前结点的值等于要查找的值 data,则输出该结点的值并返回函数。如果循环结束后仍未找到要查找的值,就输出不存在的提示信息。
遍历操作
链表的遍历操作可以通过循环遍历链表中的每个节点来实现。以单向链表为例,它的实现方法如下:
- 遍历节点:从头节点开始遍历链表,依次访问每个节点的数据元素,直到遍历到尾节点为止。
示例代码:
//遍历
void show(struct Node *head)
{
struct Node *p = head;
//当前结点有 下一个结点,有下一个结点就遍历下一个结点
while(p->next != NULL)
{
p = p->next;//找到下一个结点
printf("%d ",p->data);
}
printf("\n");
}在上述代码中,函数接收一个指向链表头结点的指针 head。定义一个指向头结点的指针 p,并通过循环遍历链表,将 p 指向链表中的每个结点,并输出每一个结点的值。
主函数
通过使用主函数来调用链表的操作,完成链表的功能。
示例代码:
int main()
{
struct Node *head = create();//创建链表
delete_link(head,1)//删除位置为1的结点
for(int i = 1;i < 11;i++)
{
insert(head,i);//插入结点
}
show(head);//遍历
delete_link(head,3);//删除位置为3的结点
show(head);//遍历
search(head,5);//查找数据为5的结点
link_delete(head);//删除链表所有结点
return 0;
}完整代码
#include <stdio.h>
#include <stdlib.h>
//构造链表节点
struct Node
{
int data;//数据域,存储数据
struct Node *next;//指针域,存储下一个的地址
};
//创建单向链表
struct Node * create()
{
//创建空链表
//头结点
//malloc 创建头结点,返回值就是结点的地址,得到头结点的地址
//使用头指针,就可以操作链表
struct Node * head = malloc(sizeof(struct Node));//使用malloc分配链表节点空间,并返回地址指针
head->next = NULL;//设定头结点的next指针为NULL,初始值
return head;
}
//链表插入结点,参数:链表(链表头指针),插入位置,插入值
void insert(struct Node *head,int pos,int data)
{
//找到pos-1位置:pos-1这个结点的地址
struct Node *p = head;
int i = 0;
while(p->next != NULL)
{
if(i == pos-1)
{
break;
}
p = p->next;
i++;
}
//如果没找到 p 是最后一个结点的地址
//如果找到 p 就是结点位置
//插入
//创建新结点
struct Node *new = malloc(sizeof(struct Node));
new->data = data;
//设置新结点的下一个结点是谁
new->next = p->next;
//设置前一个结点p存储新结点
p->next = new;
}
//删除链表元素(以传入的位置进行删除)
void delete_link(struct Node *head,int pos)
{
if(head->next == NULL)//判断链表是否为空
{
printf("链表为空\n");
return;//函数为无返回值,故只需要return就行,不能带值
}
struct Node *p = head;
int i = 0;
//找到pos-1位置:pos-1这个结点的地址
while(p->next != NULL)
{
if(i == pos-1)
{
break;
}
p = p->next;
i++;
//改为删除指定元素,要找到删除元素的前一个地址
//如果当前位置的下一个元素 == 要删除元素
}
//判断不是最后一个,是找到了前一个位置
if(p->next == NULL)
{
printf("没有位置");
return ;
}
//删除操作
struct Node *q = p->next;//创建一个新结点,来存储要删除结点,便于后续空间的释放
p->next = q->next;
printf("删除元素:%d\n",q->data);
free(q);
}
//删除所有结点包括头结点
void link_delete(struct Node *head)
{
struct Node *p = head;
while(p != NULL)
{
head = p->next;
printf("%d ",p->data);
free(p);
p = head;
}
printf("\n");
}
//查找结点
void search(struct Node *head,int data)
{
struct Node *p = head;
while((p->next != NULL)&&(p->next->data != data))
{
p = p->next;
}
if(p->next == NULL)
{
printf("该位置不存在\n");
return;
}
printf("该数据%d存在\n",p->next->data);
}
//遍历
void show(struct Node *head)
{
struct Node *p = head;
//当前结点有 下一个结点,有下一个结点就遍历下一个结点
while(p->next != NULL)
{
p = p->next;//找到下一个结点
printf("%d ",p->data);
}
printf("\n");
}
int main()
{
struct Node *head = create();//创建链表
delete_link(head,1)//删除位置为1的结点
for(int i = 1;i < 11;i++)
{
insert(head,i);//插入结点
}
show(head);//遍历
delete_link(head,3);//删除位置为3的结点
show(head);//遍历
search(head,5);//查找数据为5的结点
link_delete(head);//删除链表所有结点
return 0;
}
循环链表及双向链表

循环链表和双向链表是链表的两种变体形式。
循环链表是一种特殊的链表,它的最后一个节点指向第一个节点,形成一个环形结构。因此,循环链表可以像链表一样遍历所有节点,但不需要判断链表是否到达结尾。循环链表的插入、删除等操作与链表类似,但需要注意循环链表的头节点和尾节点的处理。
双向链表是在链表基础上增加了一个指向前驱节点的指针。双向链表可以双向遍历,即可以从头节点开始向后遍历,也可以从尾节点开始向前遍历。双向链表的插入、删除等操作相比链表更加灵活,但需要注意双向链表的指针更新。
下面是循环链表和双向链表的定义:
//循环链表结点定义
struct CNode{
int data;
struct CNode *next;
};
//双向链表结点定义
struct DNode{
int data;
struct DNode *prev;
struct DNode *next;
};
需要注意的是,循环链表和双向链表的操作实现与单向链表略有不同,但基本操作上大体相似,只需要根据具体情况进行调整就行。
链表的应用场景
链表的应用场景非常广泛,它可以用来实现栈、队列、哈希表等数据结构,也可以用来解决一些具体的问题,例如:文章来源:https://www.toymoban.com/news/detail-774738.html
- 实现文件系统中的目录结构;
- 实现各种图形算法中的图形表示;
- 实现高效的大整数运算。
结语
本文介绍了链表的定义、基本操作和应用场景,希望能够帮助读者更深入地理解链表的原理和实现。链表虽然在某些场景下比数组更加灵活和高效,但也存在一些缺点,例如访问链表中的任意元素的时间复杂度为 O(n),而数组可以在 O(1) 的时间内访问任意元素。因此,在实际应用中需要根据具体情况选择合适的数据结构。文章来源地址https://www.toymoban.com/news/detail-774738.html
到了这里,关于数据结构之链表详解的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!