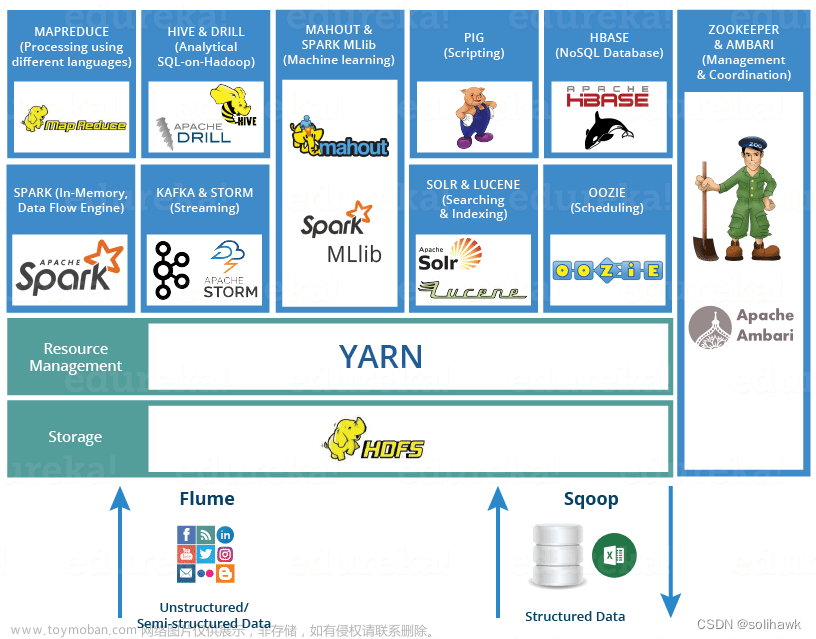
MapReduce是Hadoop的一个核心组件,它是一个编程模型和计算框架,用于处理和生成大数据集。MapReduce模型将大数据处理任务分解为两个阶段:Map阶段和Reduce阶段。在Map阶段,输入的数据被分割成一系列的键值对,然后通过用户定义的函数进行处理,生成中间的键值对。在Reduce阶段,中间的键值对被合并成最终的输出结果。
Hadoop MapReduce的主要优点是可扩展性、可靠性、数据本地性和灵活性。它能够在大量普通的硬件上运行,并且能够处理TB到PB级别的大数据集。同时,MapReduce作业具有容错性,能够在处理过程中自动处理失败的任务。
然而,MapReduce也存在一些限制和挑战。例如,MapReduce编程模型相对复杂,需要用户熟悉其概念和编程模型。此外,MapReduce对于迭代计算和流式计算的处理能力有限,对于需要实时计算和交互式分析的应用场景可能不太适合。
总的来说,Hadoop MapReduce是一个强大的分布式计算框架,适用于大规模数据集的处理和分析。它能够处理的数据量级、容错性和可扩展性使得它在许多场景下都成为一种理想的选择。在MapReduce模型中,任务被划分为多个map任务和reduce任务,这些任务在分布式系统中并行执行。Map阶段处理输入数据,生成一系列的键值对,这些键值对被分区、排序和合并,然后传递给相应的reduce任务。Reduce阶段接收来自Map阶段的键值对,对具有相同键的值进行合并或聚合操作,生成最终的输出结果。
Hadoop MapReduce的实现包括一个JobTracker和一个TaskTracker。JobTracker负责协调和管理所有的MapReduce作业,而TaskTracker负责在其所在的节点上执行Map和Reduce任务。
使用Hadoop MapReduce,用户可以使用Java、Python、C++等语言编写Map和Reduce函数,通过Hadoop的API提交作业并监视其执行情况。MapReduce模型的应用非常广泛,包括搜索引擎、机器学习、数据挖掘、日志分析等。
尽管MapReduce模型具有强大的分布式计算能力,但随着数据规模的快速增长和实时计算需求的增加,它可能不再适合所有场景。为了满足这些需求,出现了许多基于MapReduce思想的扩展和改进模型,如Apache Spark、Apache Flink等。这些模型提供了更高级别的抽象和更灵活的计算能力,使得处理大规模数据变得更加容易和高效。除了Spark和Flink等扩展模型,还有一些其他新兴的分布式计算框架也在不断发展。这些框架试图解决MapReduce在某些应用场景中的局限性,提供了更加灵活和高效的数据处理能力。
例如,Google’s TensorFlow是一个用于机器学习的开源框架,它提供了一种表达性强、灵活度高的方式来进行大规模的数值计算。与MapReduce相比,TensorFlow更适合于深度学习和机器学习领域,能够更好地支持复杂的数学运算和模型训练。
另一个例子是Apache Beam,它是一个统一的编程模型,旨在提供一种通用的方式来处理批处理和流式数据。Beam模型允许用户使用相同的编程范式来处理不同类型的输入数据,从而简化了数据处理任务的编写和调试过程。
总的来说,随着数据规模的快速增长和计算需求的多样化,分布式计算框架正在不断发展和演变。尽管MapReduce仍然是一种重要的分布式计算模型,但其他框架的出现也为我们提供了更多的选择和可能性。这些新兴框架通过提供更高级别的抽象、更灵活的计算能力和更好的性能,不断推动着大数据处理领域的发展和进步。除了上述提到的框架外,还有一些其他的分布式计算框架也在逐渐受到关注。例如,Apache Giraph是一个用于处理大规模图数据的分布式计算框架,适用于进行社交网络分析、链接分析等任务。Apache Ignite则是一个内存计算的框架,它利用内存中的数据来提高数据处理速度,适用于需要快速响应的应用,如实时分析、在线游戏等。
此外,一些框架也在尝试将分布式计算与机器学习、深度学习等算法结合,以提供更加强大的数据处理和分析能力。例如,TensorFlow和PyTorch等框架都提供了深度学习算法的实现,并支持分布式训练,从而能够处理大规模的数据集并提高模型的准确性。
总的来说,随着技术的发展和应用的多样化,分布式计算框架也在不断发展和演变。这些框架通过提供更加灵活、高效和强大的数据处理能力,帮助我们更好地应对大数据时代的挑战。虽然MapReduce仍然是一种重要的分布式计算模型,但其他框架的出现也为我们提供了更多的选择和可能性。未来,随着技术的进步和应用的需求,分布式计算框架将会继续发展并不断创新,推动大数据处理领域的发展和进步。 文章来源地址https://www.toymoban.com/news/detail-774785.html
文章来源地址https://www.toymoban.com/news/detail-774785.html
文章来源:https://www.toymoban.com/news/detail-774785.html
到了这里,关于MapReduce是Hadoop的一个核心组件,它是一个编程模型和计算框架的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!