1.背景介绍
自然语言处理(Natural Language Processing,NLP)是人工智能(Artificial Intelligence,AI)领域的一个重要分支,其目标是让计算机理解、生成和翻译人类语言。随着大数据、云计算和深度学习等技术的发展,深度学习的NLP(Deep Learning for NLP)在处理自然语言文本和语音的能力得到了显著提升。在本文中,我们将从Word2Vec到BERT,深入探讨深度学习的NLP的核心概念、算法原理、具体操作步骤以及代码实例。
2.核心概念与联系
2.1 Word2Vec
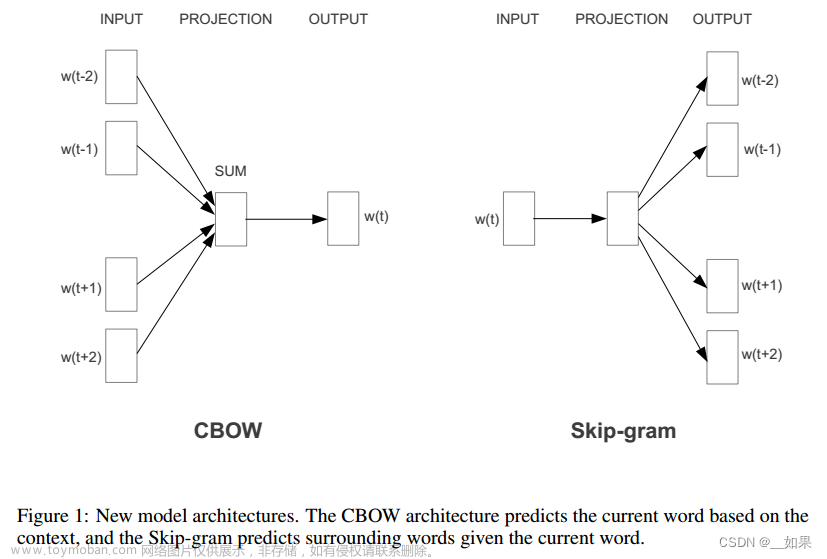
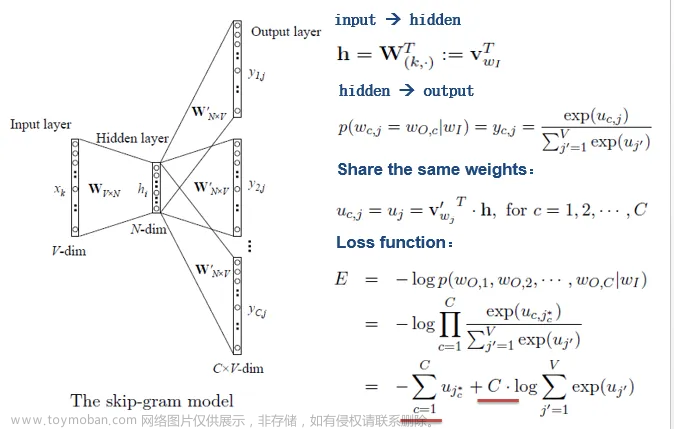
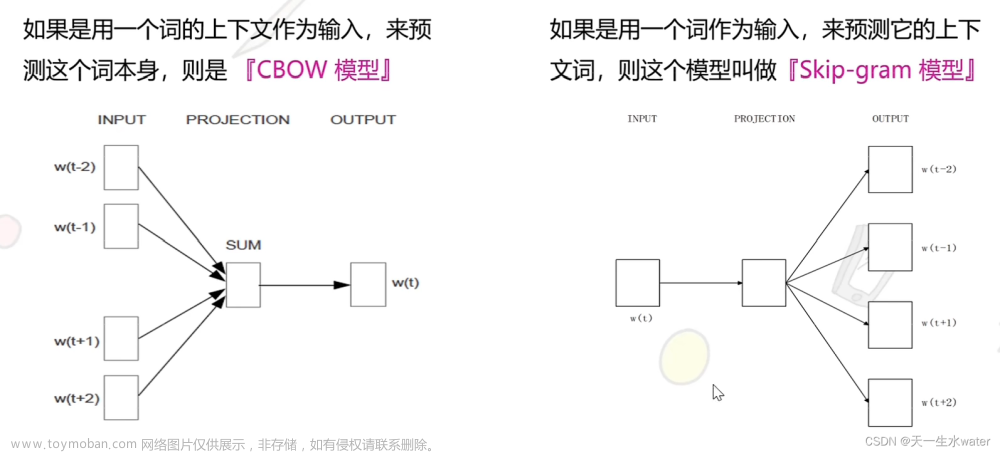
Word2Vec是一个基于深度学习的词嵌入(word embedding)模型,可以将词汇转换为高维的向量表示,从而捕捉词汇之间的语义关系。Word2Vec的核心思想是通过将大量的文本数据分成多个短语(sentence),然后将每个短语中的词汇映射到一个连续的向量空间中,从而实现词汇之间的相似度计算。Word2Vec的主要算法有两种:文章来源:https://www.toymoban.com/news/detail-775265.html
- 连续Bag-of-Words模型(Continuous Bag-of-Words,CBOW):给定一个词,CBOW将该词周围的上下文词汇作为输入,通过一个三层神经网络进行训练,目标是预测给定词。
- Skip-Gram模型:给定一个词,Skip-Gram将该词周围的上下文词汇作为输入,通过一个三层神经网络进行训练,目标是预测给定词。
2.2 GloVe
GloVe(Global V文章来源地址https://www.toymoban.com/news/detail-775265.html
到了这里,关于深度学习的Natural Language Processing:从Word2Vec到BERT的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!