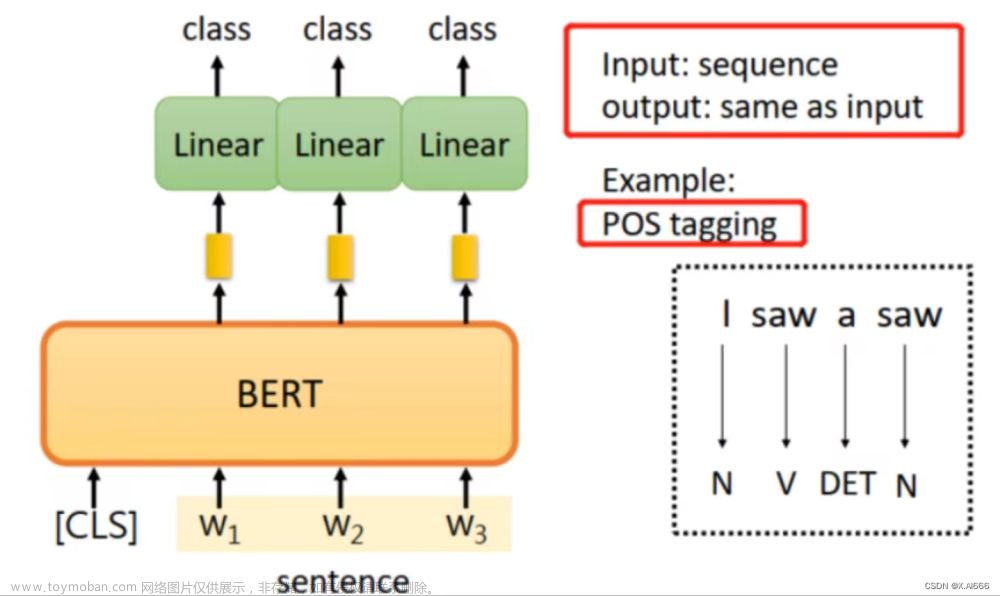
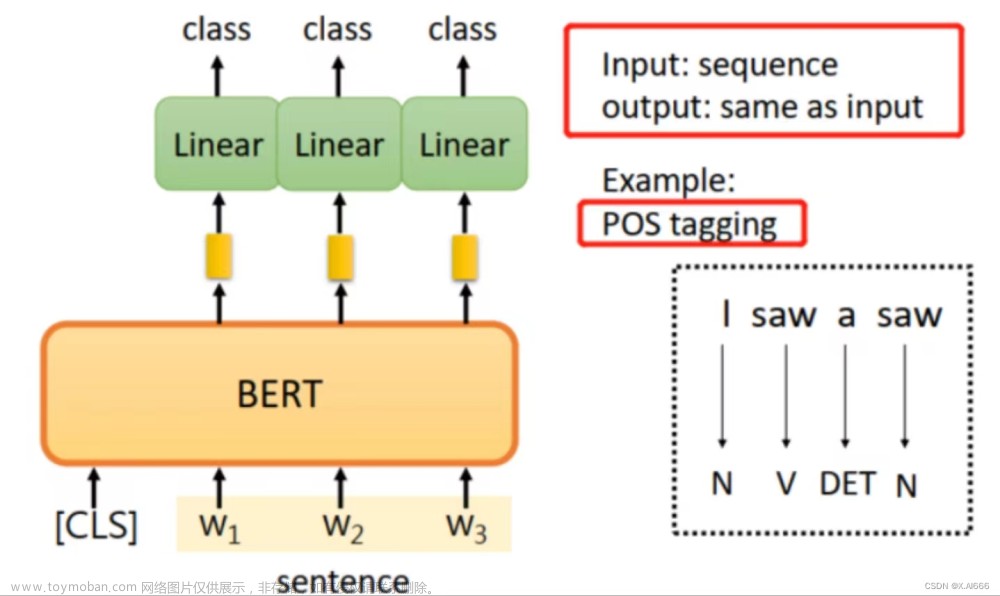
自然语言处理(Natural Language Processing,简称NLP)被誉为人工智能皇冠上的明珠,是计算机科学和人工智能领域的一个重要方向。它主要研究人与计算机之间,使用自然语言进行有效通信的各种理论和方法。简单来说,计算机以用户的自然语言数据作为输入,在其内部通过定义的算法进行加工、计算等系列操作后(用以模拟人类对自然语言的理解),再返回用户所期望的结果,如 图1 所示。 
自然语言处理是一门融合语言学、计算机科学和数学于一体的科学。它不仅限于研究语言学,还是研究能高效实现自然语言理解和自然语言生成的计算机系统,特别是其中的软件系统,因此它是计算机科学的一部分。
随着计算机和互联网技术的发展,自然语言处理技术在各领域广泛应用,如 图2 所示。在过去的几个世纪,工业革命用机械解放了人类的双手,在当今的人工智能革命中,计算机将代替人工,处理大规模的自然语言信息。我们平时常用的搜索引擎,新闻推荐,智能音箱等产品,都是以自然语言处理技术为核心的互联网和人工智能产品。

图2:自然语言处理技术在各领域的应用
此外,自然语言处理技术的研究也在日新月异变化,每年投向ACL(Annual Meeting of the Association for Computational Linguistics,计算语言学年会,自然语言处理领域的顶级会议)的论文数成倍增长,自然语言处理的应用效果被不断刷新,有趣的任务和算法更是层出不穷。
本节为您简要介绍自然语言处理的发展历程、主要挑战,以及如何使用飞桨快速完成各项常见的自然语言处理任务。
致命密码:一场关于语言的较量
事实上,人们并非只在近代才开始研究和处理自然语言,在漫长的历史长河中,是否妥当处理自然语言,成为战争的胜利或是政权的更迭的关键因素。
16世纪的英国大陆,英格兰和苏格兰刚刚完成统一,统治者为英格兰女王伊丽莎白一世,苏格兰女王玛丽因被视为威胁而遭到囚禁。玛丽女王和其他苏格兰贵族谋反,这些贵族们通过信件与玛丽女王联络,商量营救方案并推翻伊丽莎白女王的统治。为了能更安全地与同伙沟通,玛丽使用了一种传统的文字加密形式 - 凯撒密码对她们之间的信件进行加密,如 图3 所示。

这种密码通过把原文中的字母替换成另外一个字符的形式,达到加密手段。然而他们的阴谋活动早在英格兰贵族监控之下,英格兰国务大臣弗朗西斯·沃尔辛厄姆爵士通过统计英文字母的出现频率和玛丽女王密函中的字母频率,找到了破解密码的规律。最终,玛丽和其他贵族在举兵谋反前夕被捕。这是近代西方第一次破译密码,开启了近现代密码学的先河。
自然语言处理的发展历程
自然语言处理有着悠久的发展史,可粗略地分为兴起、符号主义、连接主义和深度学习四个阶段,如 图4 所示:

兴起时期
大多数人认为,自然语言处理的研究兴起于1950年前后。在二战中,破解纳粹德国的恩尼格玛密码成为盟军对抗纳粹的重要战场。经过二战的洗礼,曾经参与过密码破译的香农和图灵等科学家开始思考自然语言处理和计算之间的关系。

1948年香农把马尔可夫过程模型(Markov Progress)应用于建模自然语言,并提出把热力学中“熵”(Entropy)的概念扩展到自然语言建模领域。香农相信,自然语言跟其它物理世界的信号一样,是具有统计学规律的,通过统计分析可以帮助我们更好地理解自然语言。
1950年,艾伦图灵提出著名的图灵测试,标志着人工智能领域的开端。二战后,受到美苏冷战的影响,美国政府开始重视机器自动翻译的研究工作,以便于随时监视苏联最新的科技进展。1954年美国乔治城大学在一项实验中,成功将约60句俄文自动翻译成英文,被视为机器翻译可行的开端。自此开始的十年间,政府与企业相继投入大量的资金,用于机器翻译的研究。
1956年,乔姆斯基(Chomsky)提出了“生成式文法”这一大胆猜想,他假设在客观世界存在一套完备的自然语言生成规律,每一句话都遵守这套规律而生成。总结出这个客观规律,人们就掌握了自然语言的奥秘。从此,自然语言的研究就被分为了以语言学为基础的符号主义学派,以及以概率统计为基础的连接主义学派。
符号主义时期
在自然语言处理发展的初期阶段,大量的自然语言研究工作都聚焦从语言学角度,分析自然语言的词法、句法等结构信息,并通过总结这些结构之间的规则,达到处理和使用自然语言的目的。这一时期的代表人物就是乔姆斯基和他提出的“生成式文法”。1966年,完全基于规则的对话机器人ELIZA在MIT人工智能实验室诞生了,如 图6 所示。

图6:基于规则的聊天机器人ELIZA
然而同年,ALPAC(Automatic Language Processing Advisory Committee,自动语言处理顾问委员会)提出的一项报告中提出,十年来的机器翻译研究进度缓慢、未达预期。该项报告发布后,机器翻译和自然语言的研究资金大为减缩,自然语言处理和人工智能的研究进入寒冰期。
连接主义时期
1980年,由于计算机技术的发展和算力的提升,个人计算机可以处理更加复杂的计算任务,自然语言处理研究得以复苏,研究人员开始使用统计机器学习方法处理自然语言任务。
起初研究人员尝试使用浅层神经网络,结合少量标注数据的方式训练模型,虽然取得了一定的效果,但是仍然无法让大部分人满意。
神经网络模型的灵感来源于我们大脑中的生物神经元,它们也由多个输入、输出和隐藏层组成,每一层都有许多的神经元。神经网络模型也有类似于树突、细胞体和轴突的结构,它们可以接收、处理和传递信息。不过,神经网络模型的信息是以数值的形式表示的,它们之间的连接是以权重的形式表示的,它们的激活是以函数的形式表示的。
使用神经元作为人工智能的模型的想法可以追溯到20世纪初,当时一些心理学家和神经科学家提出了连接主义理论。连接主义是一种强调神经元之间的连接在信息处理和学习中起作用的理论。根据连接主义,大脑不是一个静态和固定的结构,而是一个动态和适应的系统,它可以根据环境和经验改变其连接和功能。

连接主义的先驱之一是唐纳德·赫布,他在1949年提出了赫布学习规则。赫布学习规则是一个简单而直观的原则,它表明“一起激活的神经元,就会一起连接”。换句话说,如果两个神经元同时被激活,它们之间的连接就会被加强,反之亦然。这个规则意味着大脑可以从经验中学习,并在刺激和反应之间形成联系。这种连接的逻辑也就是上文中我们提到的神经元信号传递选择的基础逻辑。
后来研究者开始使用人工提取自然语言特征的方式,结合简单的统计机器学习算法解决自然语言问题。其实现方式是基于研究者在不同领域总结的经验,将自然语言抽象成一组特征,使用这组特征结合少量标注样本,训练各种统计机器学习模型(如支持向量机、决策树、随机森林、概率图模型等),完成不同的自然语言任务。
由于这种方式基于大量领域专家经验积累(如解决一个情感分析任务,那么一个很重要的特征 — 是否命中情感词表),以及传统机器学习简单、鲁棒性强的特点,这个时期神经网络技术被大部分人所遗忘。
深度学习时期
从2006年深度神经网络反向传播算法的提出开始,伴随着互联网的爆炸式发展和计算机(特别是GPU)算力的进一步提高,人们不再依赖语言学知识和有限的标注数据,自然语言处理领域迈入了深度学习时代。
这里以RNN和LSTM为代表的技术成为自然语言处理的主流技术以解决长序列自然语言的关联记忆问题。

长短期记忆(Long short-term memory, LSTM)是一种特殊的RNN,主要是为了解决长序列训练过程中的梯度消失和梯度爆炸问题。简单来说,就是相比普通的RNN,LSTM能够在更长的序列中有更好的表现。

LSTM可参考此文:https://zhuanlan.zhihu.com/p/32085405
基于互联网海量数据,并结合深度神经网络的强大拟合能力,人们可以非常轻松地应对各种自然语言处理问题。越来越多的自然语言处理技术趋于成熟并显现出巨大的商业价值,自然语言处理和人工智能领域的发展进入了鼎盛时期。
自然语言处理的发展经历了多个历史阶段的演进,不同学派之间相互补充促进,共同推动了自然语言处理技术的快速发展。
自然语言处理技术面临的挑战
如何让机器像人一样,能够准确理解和使用自然语言?这是当前自然语言处理领域面临的最大挑战。为了解决这一问题,我们需要从语言学和计算两个角度思考。
语言学角度
自然语言数量多、形态各异,理解自然语言对人来说本身也是一件复杂的事情,如同义词、情感倾向、歧义性、长文本处理、语言惯性表达等。通过如下几个例子,我们一同感受一下。
同义词问题
请问下列词语是否为同义词?(题目来源:四川话和东北话6级模拟考试)
瓜兮兮 和 铁憨憨
嘎嘎 和 肉(you)
磕搀 和 难看
吭呲瘪肚 和 速度慢情感倾向问题
请问如何正确理解下面两个场景?
场景一:女朋友生气了,男朋友电话道歉。
女生:就算你买包我也不会原谅你!
男生:宝贝,放心,我不买,你别生气了。
问:女生会不会生气?场景二:甲和乙是同宿舍的室友,他们之间的对话。
甲:钥匙好像没了,你把锁别别。
乙:到底没没没?
甲:我也不道没没没。
乙:要没没你让我别,别别了,别秃鲁了咋整?
问:到底别不别?
歧义性问题
请问如何理解下面三句话?
一行行行行行,一行不行行行不行。
来到杨过曾经生活过的地方,小龙女说:“我也想过过过儿过过的生活”。
来到儿子等校车的地方,邓超对孙俪说:“我也想等等等等等过的那辆车”。相信大多数人都需要花点脑筋去理解上面的句子,在不同的上下文中,相同的单词可以具有不同的含义,这种问题我们称之为歧义性问题。
对话/篇章等长文本处理问题
在处理长文本(如一篇新闻报道,一段多人对话,甚至于一篇长篇小说)时,需要经常处理各种省略、指代、话题转折和切换等语言学现象,给机器理解自然语言带来了挑战,如 图7 所示。

图7:多轮对话中的指代和省略
探索自然语言理解的本质问题
研表究明,汉字的顺序并不定一能影阅响读,比如当你看完这句话后,才发这现里的字全是都乱的。
上面这句话从语法角度来说完全是错的,但是对大部分人来说完全不影响理解,甚至很多人都不会意识到这句话的语法是错的。
计算角度
自然语言技术的发展除了受语言学的制约外,在计算角度也天然存在局限。顾名思义,计算机是计算的机器,现有的计算机都以浮点数为输入和输出,擅长执行加减乘除类计算。自然语言本身并不是浮点数,计算机为了能存储和显示自然语言,需要把自然语言中的字符转换为一个固定长度(或者变长)的二进制编码,如 图8 所示。

由于这个编码本身不是数字,对这个编码的计算往往不具备数学和物理含义。例如:把“法国”和“首都”放在一起,大多数人首先联想到的内容是“巴黎”。但是如果我们使用“法国”和“首都”的UTF-8编码去做加减乘除等运算,是无法轻易获取到“巴黎”的UTF-8编码,甚至无法获得一个有效的UTF-8编码。因此,如何让计算机可以有效地计算自然语言,是计算机科学家和工程师面临的巨大挑战。
此外,目前也有研究人员正在关注自然语言处理方法中的社会问题:包括自然语言处理模型中的偏见和歧视、大规模计算对环境和气候带来的影响、传统工作被取代后,人的失业和再就业问题等。
Token&Vectorization
那么要实现自然语言理解和生成,我们必须解决语言学上的上下文语境和计算中的编码问题。
理解LLM(即Large Language Model,大语言模型)是如何做的呢?
-
为了读懂人类提问和输出回答,LLM必须先将单词翻译成它们能理解的语言。

-
首先,一块文字被分割成令牌(tokens) ——可以编码的基本单位。令牌通常代表词的片段,但我们会将每个完整的词变成一个令牌。

-
为了掌握一个词的意思,例如work,LLM首先通过使用大量训练数据观察它的上下文,注意它的
邻近词。这些数据集基于收集互联网上发表的文本,新LLM使用数十亿个词进行训练。
-
最终,我们得到一个巨大的与work在训练数据中一起出现的词集(E.g:roof),以及那些没有(E.g:dove)与它一起出现的词集。

-
通过这种方式我们可以将语法和词性学习出来

-
在利用Transformer体系结构的一个关键概念是自注意力(Attention)。我们解决了上下文问
 按兴趣的可以细读此文:科普神文,一次性讲透AI大模型的核心概念令牌,向量,嵌入,注意力,这些AI大模型名词是否一直让你感觉熟悉又陌生,如果答案肯定的话,那么朋友,今天这篇科普神文不容错过。我将结合大量示例及可视化的图形手段,为你由浅入深一次性讲透AI大模型的核心概念。https://mp.weixin.qq.com/s/KGU3uekq585dTCel9y9_5w
按兴趣的可以细读此文:科普神文,一次性讲透AI大模型的核心概念令牌,向量,嵌入,注意力,这些AI大模型名词是否一直让你感觉熟悉又陌生,如果答案肯定的话,那么朋友,今天这篇科普神文不容错过。我将结合大量示例及可视化的图形手段,为你由浅入深一次性讲透AI大模型的核心概念。https://mp.weixin.qq.com/s/KGU3uekq585dTCel9y9_5w
大模型时代
大模型的“万恶之源”:《Attention is All You Need》,由谷歌机器翻译团队提出的由多组 Encoder、Decoder 构成的机器翻译模型 Transformer 。

有关transfomer可以看台大李宏毅的课程,b站和知乎上都有,这里不作详细描述
【DL】图解 Transformer -- 李宏毅 - 知乎
关于大模型的文章可以参考此文:此文写的何其好啊!
GPT 应用开发和思考Ladder@在过去几个月的时间中,我们似乎正处于人工智能的革命中。除了大多数人了解的 OpenAI ChatGPT 之外,许多非常新颖、有趣、实用的 AI 应用也是层出不穷,并且在使用这些应用时时,笔者也确确实实的感受到了生产力的提高。但是关于 GPT 应用的开发知识和路线,目前似乎还没有太多的资料,所以笔者决定将自己的一些经验和思考整理成一个系列,希望能够帮助到大家。https://guangzhengli.com/blog/zh/gpt-embeddings/
参考:文章来源:https://www.toymoban.com/news/detail-775337.html
自然语言处理综述 - 飞桨AI Studio星河社区文章来源地址https://www.toymoban.com/news/detail-775337.html
到了这里,关于【大模型的前世今生】从自然语言处理说起的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!