一、前言
本项目通过yolov8/yolov7/yolov5+CRNN训练自己的数据集,实现了一个车牌识别、车牌关键点定位、车牌检测算法,可实现12种单双层车牌的字符识别:单行蓝牌、单行黄牌、新能源车牌、白色警用车牌、教练车牌、武警车牌、双层黄牌、双层白牌、使馆车牌、港澳粤Z牌、双层绿牌、民航车牌。
视频实时测试效果展示如下:
【准确度顶满!车牌识别、关键点定位-YOLOv8+CRNN(原创毕设)】 https://www.bilibili.com/video/BV1hc41117Ms/?spm_id_from=333.999.0.0&vd_source=8c532ded7c7c9041f04e35940d11fdae
【准确度顶满!车牌识别-YOLOv8+CRNN(原创毕设)】 https://www.bilibili.com/video/BV12c411U76h/?spm_id_from=333.999.0.0&vd_source=8c532ded7c7c9041f04e35940d11fdae
1、项目介绍
车牌识别技术通过图像处理和模式识别,能够自动识别车辆的车牌信息。其意义在于提高交通管理效率、强化治安监控、优化停车管理和促进智慧城市建设。车牌识别可以实现快速准确的车辆识别,帮助监测交通违法行为、追踪犯罪嫌疑车辆,提升交通流畅度和安全性。在停车场管理中,车牌识别技术可实现自动识别进出车辆,提高停车效率。综合运用于城市管理系统,车牌识别有助于建设更智能、安全、便捷的城市生活。本设计旨在开发一个能够及时、准确地识别车牌的算法,其主要目标包括:实时检测现实道路上的车辆并定位车牌四个角点位置;提供可靠的车牌字符识别结果。
我们的项目可为兄弟们的毕设、课设、大作业等提供参考,可训练自己的数据集,可以换成yolov8/yolov7/yolov5各种版本的权重。包含特别详细的read.md文件和常见问题解答,关于本项目的任何问题都能在其中找到答案,对刚接触深度学习、目标检测的小白非常友好,兄弟们放心哈。
2、图片测试效果展示
可以看到,我们实验室的项目能对图片、视频中出现的各类车牌字符进行有效识别,且准确率较高。
二、项目环境配置
不熟悉pycharm的anaconda的大兄弟请先看这篇csdn博客,了解pycharm和anaconda的基本操作。
https://blog.csdn.net/ECHOSON/article/details/117220445
anaconda安装完成之后请切换到国内的源来提高下载速度 ,命令如下:
conda config --remove-key channels
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/main/
conda config --add channels https://mirrors.ustc.edu.cn/anaconda/pkgs/free/
conda config --add channels https://mirrors.bfsu.edu.cn/anaconda/cloud/pytorch/
conda config --set show_channel_urls yes
pip config set global.index-url https://mirrors.ustc.edu.cn/pypi/web/simple
首先创建python3.8的虚拟环境,请在命令行中执行下列操作:
conda create -n yolov8 python==3.8.5
conda activate yolov8
1、pytorch安装(gpu版本和cpu版本的安装)
实际测试情况是yolov8/yolov7/yolov5在CPU和GPU的情况下均可使用,不过在CPU的条件下训练那个速度会令人发指,所以有条件的小伙伴一定要安装GPU版本的Pytorch,没有条件的小伙伴最好是租服务器来使用。GPU版本安装的具体步骤可以参考这篇文章:https://blog.csdn.net/ECHOSON/article/details/118420968。
需要注意以下几点:
1、安装之前一定要先更新你的显卡驱动,去官网下载对应型号的驱动安装
2、30系显卡只能使用cuda11的版本
3、一定要创建虚拟环境,这样的话各个深度学习框架之间不发生冲突
我这里创建的是python3.8的环境,安装的Pytorch的版本是1.8.0,命令如下:
conda install pytorch==1.8.0 torchvision torchaudio cudatoolkit=10.2 # 注意这条命令指定Pytorch的版本和cuda的版本
conda install pytorch==1.8.0 torchvision==0.9.0 torchaudio==0.8.0 cpuonly # CPU的小伙伴直接执行这条命令即可
安装完毕之后,我们来测试一下GPU是否可以有效调用:

2、pycocotools的安装
pip install pycocotools-windows
3、其他包的安装
另外的话大家还需要安装程序其他所需的包,包括opencv,matplotlib这些包,不过这些包的安装比较简单,直接通过pip指令执行即可,我们cd到yolov8/yolov7/yolov5代码的目录下,直接执行下列指令即可完成包的安装。
pip install -r requirements.txt
三、yolov8/yolov7/yolov5+CRNN-中文车牌识别、车牌关键点定位、车牌检测算法
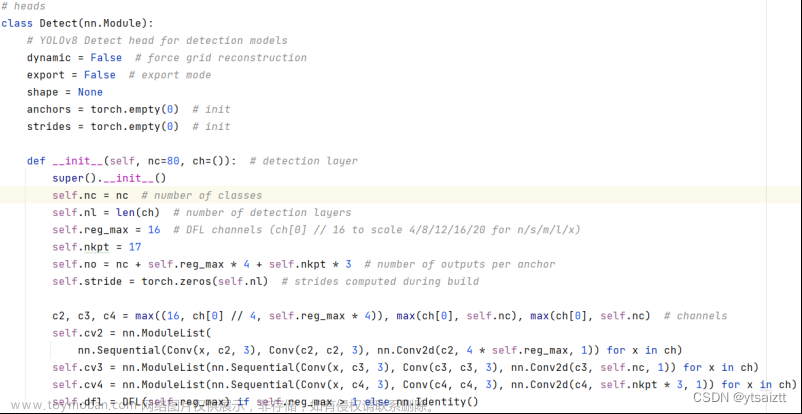
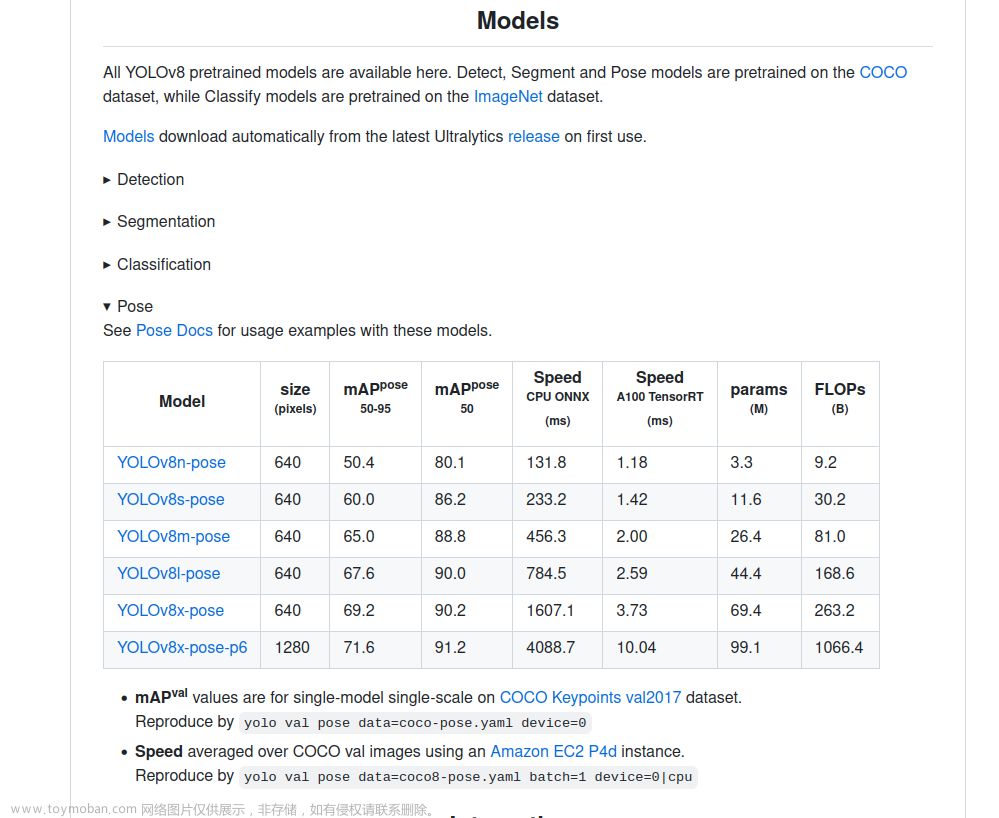
1、yolov8算法介绍
yolov8是yolo系列的最新算法,检测效果优于之前的所有的yolo算法。这里,我们采用了ultralytics官方版本的yolov8来检测车牌。
在学习Yolov8之前,我们需要对Yolov8所做的工作有一定的了解,这有助于我们后面去了解网络的细节,Yolov8在预测方式上与之前的Yolo并没有多大的差别,依然分为三个部分:分别是Backbone,FPN以及Yolo Head。
Backbone是Yolov8的主干特征提取网络,输入的图片首先会在主干网络里面进行特征提取,提取到的特征可以被称作特征层,是输入图片的特征集合。在主干部分,我们获取了三个特征层进行下一步网络的构建,这三个特征层我称它为有效特征层。
FPN是Yolov8的加强特征提取网络,在主干部分获得的三个有效特征层会在这一部分进行特征融合,特征融合的目的是结合不同尺度的特征信息。在FPN部分,已经获得的有效特征层被用于继续提取特征。在YoloV8里依然使用到了Panet的结构,我们不仅会对特征进行上采样实现特征融合,还会对特征再次进行下采样实现特征融合。
Yolo Head是Yolov8的分类器与回归器,通过Backbone和FPN,我们已经可以获得三个加强过的有效特征层。每一个特征层都有宽、高和通道数,此时我们可以将特征图看作一个又一个特征点的集合,每个特征点作为先验点,而不再存在先验框,每一个先验点都有通道数个特征。Yolo Head实际上所做的工作就是对特征点进行判断,判断特征点上的先验框是否有物体与其对应。Yolov8所用的解耦头是分开的,也就是分类和回归不在一个1X1卷积里实现。
因此,整个Yolov8网络所作的工作依然就是 特征提取-特征加强-预测先验框对应的物体情况。
2、CRNN算法介绍
CRNN是“卷积递归神经网络”(Convolutional Recurrent Neural Network)的缩写。它是一种深度学习架构,结合了卷积神经网络(CNN)和循环神经网络(RNN)的优势,主要用于处理具有序列性和空间信息的数据,比如图像中的文字识别。
CRNN的结构包含了卷积层、循环层和连接层。首先,卷积层用于提取图像特征,将输入图像转换为高层次的抽象特征表示。这些特征捕获了文字在不同尺度和方向上的信息,使得模型对文字的变化和形态有较强的理解能力。
接着,循环层(通常采用长短时记忆网络,LSTM,或者门控循环单元,GRU)用于处理序列数据,它能够保留文字之间的上下文信息。这使得CRNN能够更好地理解文字之间的关系,并且有助于纠正识别错误。
最后,连接层用于将卷积层和循环层的输出结合起来,并通过全连接层进行最终的分类或识别。这个结构允许模型同时利用局部特征和全局上下文信息,提高了对文字的准确识别能力。
CRNN在文字识别领域取得了很大成功,特别是在场景文本识别(如自然场景中的文字识别)方面。它能够处理不同字体、大小、角度和背景的文字,并且对于不同语言的文字具有一定的通用性。
总的来说,CRNN作为结合了CNN和RNN的深度学习架构,具有处理序列数据和空间信息的能力,特别适用于文字识别等领域,为处理具有结构性数据的任务提供了一种有效的解决方案。
3、算法流程设计
首先,通过卷积神经网络(CNN)提取输入图像的特征。然后,使用Anchor Boxes来生成候选区域,这些区域包含可能的目标边界框。通过对这些候选区域进行分类和定位回归,确定最终的目标边界框和其类别。YOLOv8采用多尺度特征融合,以捕捉不同尺度的信息,提高检测性能。此外,它使用自适应的Anchor Box来适应不同目标形状。整个过程通过端到端的训练来优化网络参数,实现高效、准确的车牌检测。YOLOv8检测到的车牌如图:
如上图所示,检测有可能定位不准,导致车牌周边图像也被包含在感兴趣区域内。另外,检测出来的车牌会存在一定倾角,不利于后续的车牌字符识别。因此,对车牌进行关键点回归定位。如图所示:
定位到车牌四个角点之后,使用数学图像处理中的透视变化技术对其进行矫正。透视变换原理详见,此处不再赘述。具体代码实现如下:
def four_point_transform(image, pts): #透视变换得到车牌小图
rect = order_points(pts)
(tl, tr, br, bl) = rect
widthA = np.sqrt(((br[0] - bl[0]) ** 2) + ((br[1] - bl[1]) ** 2))
widthB = np.sqrt(((tr[0] - tl[0]) ** 2) + ((tr[1] - tl[1]) ** 2))
maxWidth = max(int(widthA), int(widthB))
heightA = np.sqrt(((tr[0] - br[0]) ** 2) + ((tr[1] - br[1]) ** 2))
heightB = np.sqrt(((tl[0] - bl[0]) ** 2) + ((tl[1] - bl[1]) ** 2))
maxHeight = max(int(heightA), int(heightB))
dst = np.array([
[0, 0],
[maxWidth - 1, 0],
[maxWidth - 1, maxHeight - 1],
[0, maxHeight - 1]], dtype = "float32")
M = cv2.getPerspectiveTransform(rect, dst)
warped = cv2.warpPerspective(image, M, (maxWidth, maxHeight))
return warped
得到的矫正后车牌图像:
再将矫正后的车牌输入CRNN中进行字符识别,得到最终的字符识别效果,并在图像上以文本的形式输出。
class_label= int(class_num) #车牌的的类型0代表单牌,1代表双层车牌
roi_img = four_point_transform(img,landmarks_np) #透视变换得到车牌小图
if class_label: #判断是否是双层车牌,是双牌的话进行分割后然后拼接
roi_img=get_split_merge(roi_img)
plate_number ,plate_color= get_plate_result(roi_img,device,plate_rec_model) #对车牌小图进行识别,得到颜色和车牌号
for dan in danger: #只要出现‘危’或者‘险’就是危险品车牌
if dan in plate_number:
plate_number='危险品'
# cv2.imwrite("roi.jpg",roi_img)
result_dict['class_type']=class_type[class_label]
result_dict['rect']=rect #车牌roi区域
result_dict['landmarks']=landmarks_np.tolist() #车牌角点坐标
result_dict['plate_no']=plate_number #车牌号
result_dict['roi_height']=roi_img.shape[0] #车牌高度
result_dict['plate_color']=plate_color #车牌颜色
result_dict['object_no']=class_label #单双层 0单层 1双层
result_dict['score']=conf #车牌区域检测得分
return result_dict
4、代码使用
直接执行项目中的Car_recognition.py即可。如下主函数中:“–detect_model”参数为检测模型的权重,“----rec_model”参数为车牌识别+车牌颜色识别模型的权重,“----image_path”参数为测试图片文件夹的路径,‘–img_size’代表输入模型进行推理的图像尺寸(理论上这个值越接近原始大小,车牌识别越准确,但推理帧率也会有一定程度下降),’–output’为输出图像存放的文件夹名称或输出视频的名称,'–video’为输入视频的路径。要实现视频推理,在“–video”参数处设置视频路径即可。
if __name__ == '__main__':
parser = argparse.ArgumentParser()
parser.add_argument('--detect_model', nargs='+', type=str, default='weights/detect.pt', help='model.pt path(s)') #检测模型
parser.add_argument('--rec_model', type=str, default='weights/plate_rec_color.pth', help='model.pt path(s)')#车牌识别+车牌颜色识别模型
parser.add_argument('--car_rec_model',type=str,default='weights/car_rec_color.pth',help='car_rec_model') #车辆识别模型
parser.add_argument('--image_path', type=str, default='test', help='source')
parser.add_argument('--img_size', type=int, default=1080, help='inference size (pixels)')
parser.add_argument('--output', type=str, default='result', help='source')
parser.add_argument('--video', type=str, default='test/test.mp4', help='source')
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
四、自己训练的步骤
对于兄弟们的毕设、课设项目来说,没有必要再重新训练一遍。一方面耗时费力,自己的电脑也不一定跑的动;另一方面我这边会提供所有的训练过程曲线、数据、和训练好的权重,直接调用就行。
1、下载数据集
数据是从CCPD和CRPD数据集中选取并转换的,为yolo格式:
label x y w h pt1x pt1y pt2x pt2y pt3x pt3y pt4x pt4y
关键点依次是(左上、右上、右下、左下)。坐标都是经过归一化,x、y是中心点除以图片宽高,w、h是框的宽高除以图片宽高,ptx、pty是关键点坐标除以宽高。车辆标注不需要关键点,关键点全部置为-1即可。
2、修改路径
换成自己的数据集路径。
train: /your/train/path #修改成你的路径
val: /your/val/path #修改成你的路径
# number of classes
nc: 3 #这里用的是3分类,0 单层车牌 1 双层车牌 2 车辆
# class names
names: [ 'single_plate','double_plate','Car']
3、开始训练
python3 train.py --data data/plateAndCar.yaml --cfg models/yolov5n-0.5.yaml --weights weights/detect.pt --epoch 250
五、车牌识别、检测自建数据集
我们实验室手动收集、整理了一个高质量的车牌识别、检测数据集,包含41892张车辆车牌图片和对应的txt格式标签。已将其划分为训练集、测试集。本数据集可直接用于训练yolo系列等神经网络,可提供给兄弟们的毕设、课设项目及企业课题进行使用。数据集展示如下:

六、训练曲线等介绍
我们的项目代码还能自动生成训练过程的loss损失曲线、map平均准确度曲线,不用手动画(太麻烦了,能用代码做的事尽量不手动),兄弟可以直接将这些图插入论文或课设报告中。当然,也可以自己训练,重新生成对应的图。训练结束后,这些图和训练数据会(以envents文件形式)存放在根目录下的runs文件夹中。我项目中已导出为PNG图片和CSV表格,可以直接拿去用。


包含完整word版本说明文档,可用于写论文、课设报告的参考。
七、资源获取(yolov8/yolov7/yolov5版本均可提供)
yolov8/yolov7/yolov5车牌识别、定位、检测系统的实现和训练、数据的整理耗费了我们实验室大量的时间和精力。所以有偿提供使用,感谢兄弟们理解。有需要的兄弟可通过以下方式获取资源。我们的代码有详细注释,包全程指导,任何问题都可以随时问我。不过有的时候我太忙,可能不会及时回复消息,看到了肯定回你哈。文章来源:https://www.toymoban.com/news/detail-775416.html
获取整套代码、测试图片视频、车牌识别数据集、训练好的权重和说明文档(有偿)
上交在读博士,技术够硬,也可以指导深度学习毕设、大作业等。
--------------qq---------------------
3582584734
-------------------------------------
 文章来源地址https://www.toymoban.com/news/detail-775416.html
文章来源地址https://www.toymoban.com/news/detail-775416.html
到了这里,关于YOLOv8/YOLOv7/YOLOv5+CRNN-车牌识别、车牌关键点定位、车牌检测(毕业设计)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!