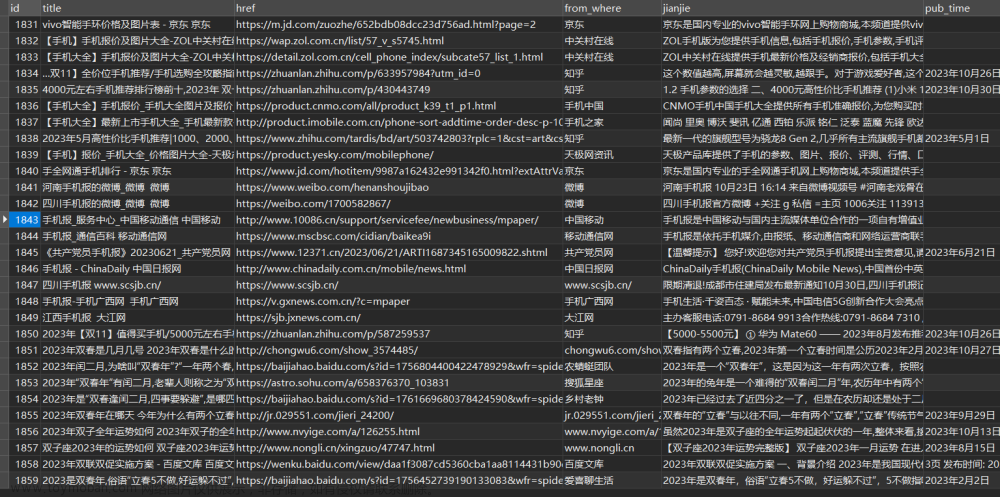
Python是一种功能强大的编程语言,可以用于各种任务,包括网络爬虫。
在本文中,我们将使用selenium库,来实现爬取百度翻译结果的功能。百度翻译是一个广泛使用的在线翻译工具,它提供了多种语言之间的即时翻译服务。selenium库可通过pip安装:pip install selenium。
使用Selenium库,我们可以模拟用户在浏览器中的操作,从而实现自动化地访问百度翻译网页、输入要翻译的文本、获取翻译结果等功能。
先放代码运行效果: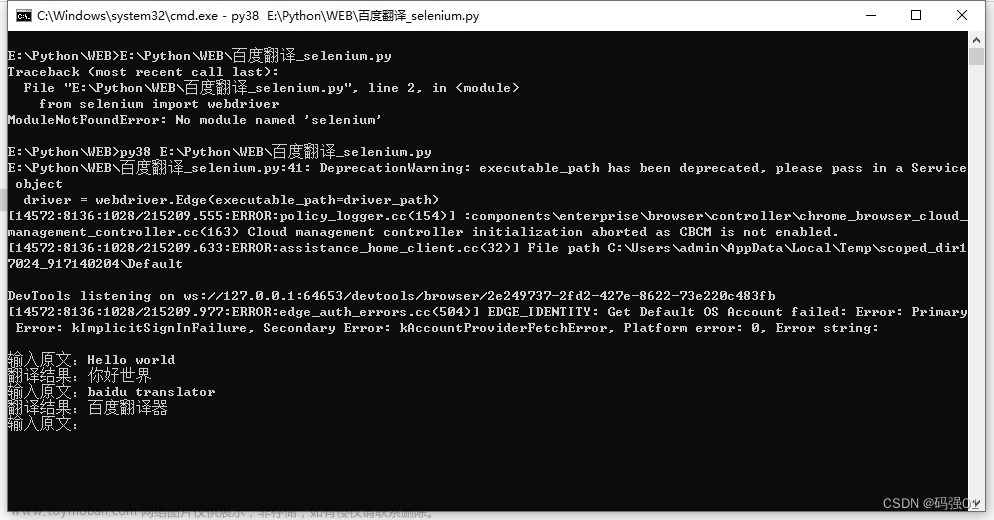
代码首先加载网页。由于初次加载网页会有广告提示,需要首先点击关闭按钮。
然后是正儿八经的输入原文、点击按钮、等待结果、获取译文的过程。
废话少说直接上代码:
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time,traceback
def translate(string):
global prev_result
if not completed:
raise Exception("页面未加载完成")
# 输入要翻译的文本。注意未登录时原文最多为1000字,超出的不会翻译(已登录后为5000字)
input_element = driver.find_element(By.ID, 'baidu_translate_input')
input_element.clear()
input_element.send_keys(string)
# 点击翻译按钮
translate_button = driver.find_element(By.ID, 'translate-button')
translate_button.click()
# 等待结果出现
wait.until(EC.presence_of_element_located((By.CLASS_NAME, 'ordinary-output.target-output.clearfix')))
# 等待新的结果变化
while driver.find_element(By.CLASS_NAME, 'ordinary-output.target-output.clearfix').text==prev_result:
time.sleep(0.05)#pass
# 获取翻译结果
output_element = driver.find_element(By.CLASS_NAME, 'ordinary-output.target-output.clearfix')
output_text = output_element.text
prev_result=output_text
# 输出翻译结果
return output_text
driver_path = r"D:\Users\Administrator\msedgedriver.exe"
completed=False
prev_result=""
# 初始化Chrome浏览器驱动
driver = webdriver.Edge(executable_path=driver_path)
# 打开百度翻译网页
# 百度翻译网址构成:https://fanyi.baidu.com/#<源语种>/<目标语种>/<初始原文>
# 常用语种缩写:中文:zh,英语:en,日语:jp,韩语:kor,粤语:yue,俄语:ru,德语:de,法语:fra
# 泰语:th,葡萄牙语:pt,西班牙语:spa,阿拉伯语:ara,自动检测:auto
from_lang="en"
to_lang="zh"
driver.get('https://fanyi.baidu.com/#%s/%s' % (from_lang,to_lang))
# 等待页面加载完成
wait = WebDriverWait(driver, 10)
wait.until(EC.presence_of_element_located((By.ID, 'baidu_translate_input')))
completed=True
# (自己新增)点击关闭提示按钮
close_btn=driver.find_element(By.CLASS_NAME, 'app-guide-close')
close_btn.click()
try:
while True:
s=input("输入原文:")
if s.strip():
print("翻译结果:"+translate(s))
finally:
driver.quit()
综上所述,使用Python的selenium库可以方便地实现对翻译结果的自动化爬取。通过代码,我们可以学习selenium库进行页面元素定位、模拟用户输入和点击的实现。
希望这篇文章对您学习和应用selenium库有所帮助。欢迎点赞、评论、收藏。文章来源:https://www.toymoban.com/news/detail-775621.html
----------这里还没有结束-------------------
拓展:使用API获取百度翻译结果的代码:文章来源地址https://www.toymoban.com/news/detail-775621.html
import http.client
import hashlib
import json
import urllib
import random
import traceback
def baidu_translate(content):
appid = '' # 省略,需自行购买百度翻译的API
secretKey = '' # 省略, 原因同上
httpClient = None
myurl = '/api/trans/vip/translate'
q = content
fromLang = 'en' # 源语言
toLang = 'zh' # 翻译后的语言
salt = random.randint(32768, 65536)
sign = appid + q + str(salt) + secretKey
sign = hashlib.md5(sign.encode()).hexdigest()
myurl = myurl + '?appid=' + appid + '&q=' + urllib.parse.quote(
q) + '&from=' + fromLang + '&to=' + toLang + '&salt=' + str(
salt) + '&sign=' + sign
try:
httpClient = http.client.HTTPConnection('api.fanyi.baidu.com')
httpClient.request('GET', myurl)
# response是HTTPResponse对象
response = httpClient.getresponse()
jsonResponse = response.read().decode("utf-8")# 获得返回的结果,结果为json格式
js = json.loads(jsonResponse) # 将json格式的结果转换字典结构
if js.get("error_msg",None):
raise Exception(str(js["error_code"])+js["error_msg"])
dst = str(js["trans_result"][0]["dst"]) # 取得翻译后的文本结果
return dst
except Exception:
traceback.print_exc()
finally:
if httpClient:
httpClient.close()
while True:
text=input("输入英文:")
if text:
print(baidu_translate(text) or '')
到了这里,关于Python selenium 爬取百度翻译结果的代码实现的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!