环境准备
准备三台虚拟机,配置最好是 2C 4G 以上
本文准备三台机器的内网ip分别为
172.17.0.10
172.17.0.11
172.17.0.12
本机配置/etc/hosts
cat >> /etc/hosts<<EOF
172.17.0.10 hadoop01
172.17.0.11 hadoop02
172.17.0.12 hadoop03
EOF
本机设置与服务器地址免密登录
这一步可以设置也可以不设置,在mac电脑上设置免密登录比较方便
如果是通过工具入secure-crt那也可以记住密码就行
ssh-copy-id -i ~/.ssh/id_rsa.pub root@hadoop01
ssh-copy-id -i ~/.ssh/id_rsa.pub root@hadoop02
ssh-copy-id -i ~/.ssh/id_rsa.pub root@hadoop01
ssh root@hadoop01 测试看能不能登录
主机修改hostname
分别进入三台虚拟机,设置对应的hostname
hostnamectl set-hostname hadoop01
hostnamectl set-hostname hadoop02
hostnamectl set-hostname hadoop03
效果如图所示
主机配置hosts
与本机操作一样
cat >> /etc/hosts<<EOF
172.17.0.10 hadoop01
172.17.0.11 hadoop02
172.17.0.12 hadoop03
EOF
ping hadoop02
PING hadoop02 (172.17.0.11) 56(84) bytes of data.
64 bytes from hadoop02 (172.17.0.11): icmp_seq=1 ttl=64 time=0.195 ms
64 bytes from hadoop02 (172.17.0.11): icmp_seq=2 ttl=64 time=0.147 ms
网络时间同步
每台机器时间最好同步下,避免后面出现问题
查看是否有 ntpdate
which ntpdate
# 如果没有就安装
yum install ntpdate -y
统一时区上海时区
ln -snf /usr/share/zoneinfo/Asia/Shanghai /etc/localtime
bash -c "echo 'Asia/Shanghai' > /etc/timezone"
使用阿里服务器进行时间更新
# 使用阿里服务器进行时间更新
ntpdate ntp1.aliyun.com
查看当前时间
date
Thu Nov 16 10:08:47 CST 2023
配置jdk
由于hadoop以及zk都需要jdk环境,所以我们把jdk配置到全局访问路径下
我们就放在自己的目录下 /apps/svr
创建文件夹 mkdir -p /apps/svr
赋权 chmod -R 777 /apps/svr
上传jdk scp jdk.tar.gz root@hadoop01:/apps/svr
解压 tar -zxvf jdk.tar.gz
配置环境变量加到 /etc/bashrc 的最后面
export JAVA_HOME=/apps/svr/jdk
PATH=$PATH:$JAVA_HOME/bin
export PATH
source /etc/bashrc
查看java版本
java -version
java version "1.8.0_131"
Java(TM) SE Runtime Environment (build 1.8.0_131-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode)
如上所示表示配置成功,其它两台机器一样的操作配置
总结
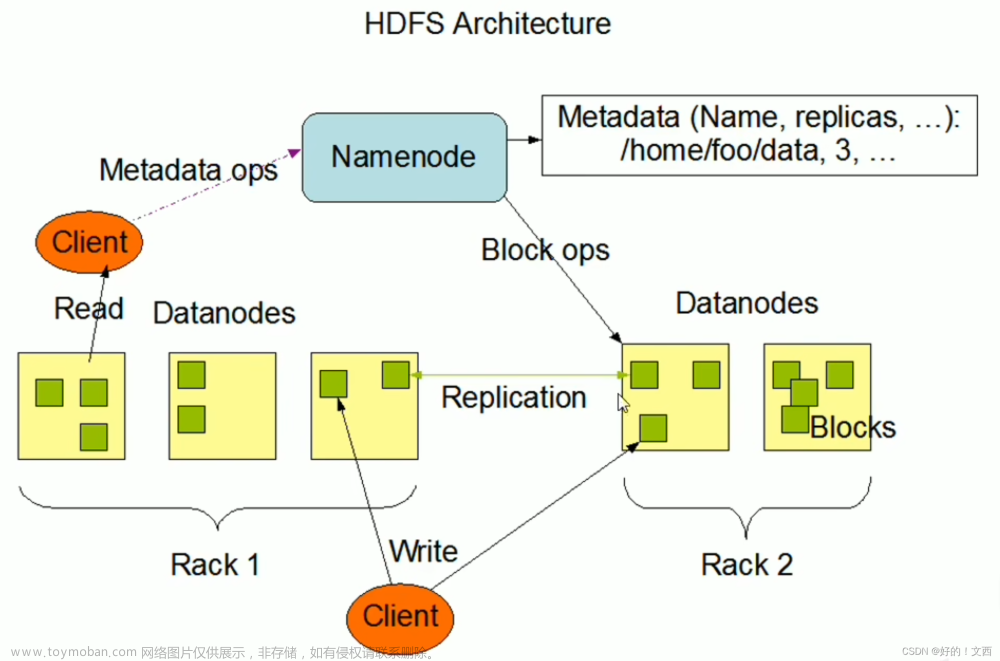
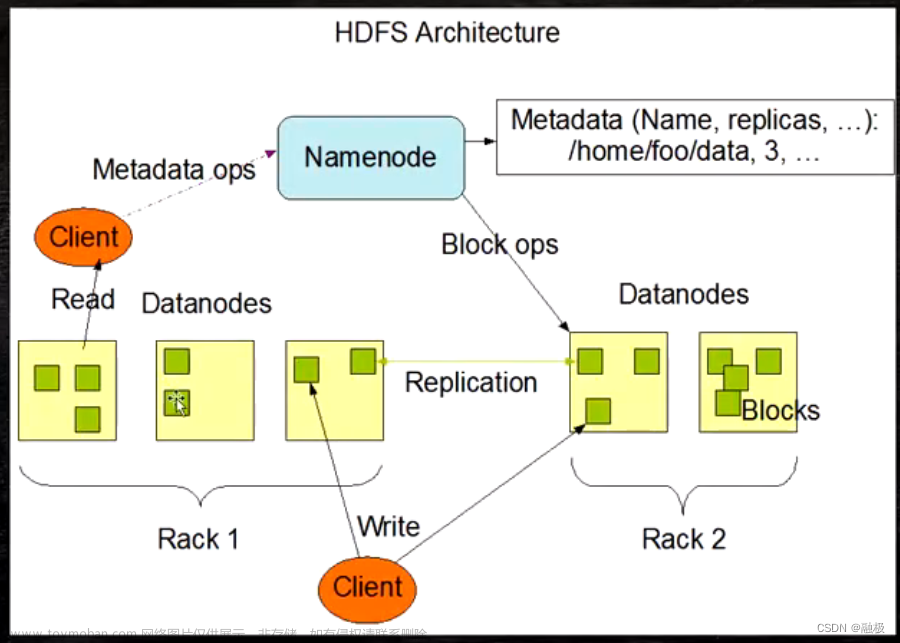
hadoop集群的环境准备就到这里,后面我们基于这套环境部署zk,hdfs,yarn文章来源:https://www.toymoban.com/news/detail-775839.html
欢迎关注,学习不迷路!文章来源地址https://www.toymoban.com/news/detail-775839.html
到了这里,关于1. hadoop环境准备的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!