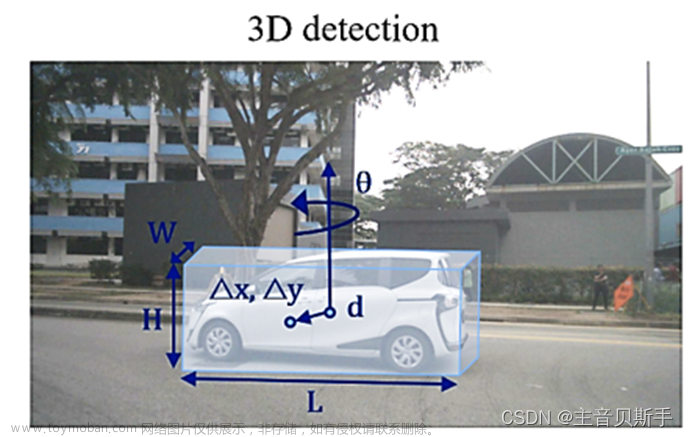
本文为个人学习过程中所记录笔记,便于梳理思路和后续查看用,如有错误,感谢批评指正!
参考:
paper:
code:
Abstract:
采用Pointfusion 和VoxelFusion实现了相机和点云的早融合。在KITTI数据集上包括5类别的鸟瞰数据和3D检测数据中获得前2名的数据。
I. INTRODUCTION
目前做3D检测有常见的两种思路:(1)将3D点云转换成手工特征,比如BEVmap,然后采用2DCNN的方法进行检测和分类,该方法收到量化的影响,当目标较少,上面的点云较少时,性能下降严重。(2)直接采用3DCNN对三维点云进行处理,该方法所需内存太大,存在计算瓶颈。
VoxelNet的提出,大大提升了对于点云的处理效率。
本文中,将VoxelNet扩展到了多模态,将点云和图像的语义特征在早期进行融合,具体有两种融合方法:
(1)PointFusion:将2D图像特征提取器提取图像特征,将原始点云投影到图像上,提取有点云对应的位置的图像特征,然后维度处理以后和点云特征直接相加融合,最后将结果输入VoxelNet进行处理。
(2)VoxelFusion:采用voxelnet生成3D voxels,然后投影到图像,然后针对每个投影后的voxel采用与训练的CNN进行特征提取。与Pointfusion 相比,voxelfusion是一个相对的后融合技术。
II. RELATED WORK
III. PROPOSED METHOD
PointFusion or VoxelFusion是选其一进行采用的。
PointFusion:将原始点云投影到图像上,然后和图像一起输入2D预训练特征提取器。
VoxelFusion:将voxel网格化后非空的结果投影到图像上,然后再一起输入2D特征提取器。
2D Detection Network
采Faster rcnn框架提取特征。VGG16骨干。
B. VoxelNet
包括VFE、卷积中间层和3DRPN。
VFE解码在独立的voxel水平的原始点云,VFE全连接层。详细见点云处理方式笔记
C. Multimodal Fusion
PointFusion: 见后续代码分析。
VoxelFusion:非空的voxel投影到图像上产生2D的ROI,然后进行ROI pooling。相比于pointfusion,内存需求更低,速度更快,并且更容易通过投影所有voxel的方式扩展,使得更多利用图像特征,避免点云覆盖不到的目标物漏检的情况。(遗憾的是,该方法暂无代码实现,可能因为该方法在论文中指标更低的缘故。)
D. Training Details
在VoxelFusion中,将所有的voxel都投影到图像上能够更好的处理远距离目标的检测。
测试了将原始图片直接投影到图像上的效果不如经过CNN提取特征后投影的效果。
代码分析:参考mmdetection3d框架,PointFusion方法。
模型部分代码整体结构如下:
def forward(self,
inputs: Union[dict, List[dict]],
data_samples: OptSampleList = None,
mode: str = 'tensor',
**kwargs) -> ForwardResults:
"""The unified entry for a forward process in both training and test.
The method should accept three modes: "tensor", "predict" and "loss":
- "tensor": Forward the whole network and return tensor or tuple of
tensor without any post-processing, same as a common nn.Module.
- "predict": Forward and return the predictions, which are fully
processed to a list of :obj:`Det3DDataSample`.
- "loss": Forward and return a dict of losses according to the given
inputs and data samples.
Note that this method doesn't handle neither back propagation nor
optimizer updating, which are done in the :meth:`train_step`.
Args:
inputs (dict | list[dict]): When it is a list[dict], the
outer list indicate the test time augmentation. Each
dict contains batch inputs
which include 'points' and 'imgs' keys.
- points (list[torch.Tensor]): Point cloud of each sample.
- imgs (torch.Tensor): Image tensor has shape (B, C, H, W).
data_samples (list[:obj:`Det3DDataSample`],
list[list[:obj:`Det3DDataSample`]], optional): The
annotation data of every samples. When it is a list[list], the
outer list indicate the test time augmentation, and the
inter list indicate the batch. Otherwise, the list simply
indicate the batch. Defaults to None.
mode (str): Return what kind of value. Defaults to 'tensor'.
Returns:
The return type depends on ``mode``.
- If ``mode="tensor"``, return a tensor or a tuple of tensor.
- If ``mode="predict"``, return a list of :obj:`Det3DDataSample`.
- If ``mode="loss"``, return a dict of tensor.
"""
if mode == 'loss':
return self.loss(inputs, data_samples, **kwargs)
elif mode == 'predict':
if isinstance(data_samples[0], list):
# aug test
assert len(data_samples[0]) == 1, 'Only support ' \
'batch_size 1 ' \
'in mmdet3d when ' \
'do the test' \
'time augmentation.'
return self.aug_test(inputs, data_samples, **kwargs)
else:
return self.predict(inputs, data_samples, **kwargs)
elif mode == 'tensor':
return self._forward(inputs, data_samples, **kwargs)
else:
raise RuntimeError(f'Invalid mode "{mode}". '
'Only supports loss, predict and tensor mode')
分为训练和推理两种模式,两种模式的通用的第一步均是特征提取,主要包括图像特征提取和点云特征提取。以推理过程为例:
def predict(self, batch_inputs_dict: Dict[str, Optional[Tensor]],
batch_data_samples: List[Det3DDataSample],
**kwargs) -> List[Det3DDataSample]:
"""Forward of testing.
Args:
batch_inputs_dict (dict): The model input dict which include
'points' keys.
- points (list[torch.Tensor]): Point cloud of each sample.
batch_data_samples (List[:obj:`Det3DDataSample`]): The Data
Samples. It usually includes information such as
`gt_instance_3d`.
Returns:
list[:obj:`Det3DDataSample`]: Detection results of the
input sample. Each Det3DDataSample usually contain
'pred_instances_3d'. And the ``pred_instances_3d`` usually
contains following keys.
- scores_3d (Tensor): Classification scores, has a shape
(num_instances, )
- labels_3d (Tensor): Labels of bboxes, has a shape
(num_instances, ).
- bbox_3d (:obj:`BaseInstance3DBoxes`): Prediction of bboxes,
contains a tensor with shape (num_instances, 7).
"""
batch_input_metas = [item.metainfo for item in batch_data_samples]
img_feats, pts_feats = self.extract_feat(batch_inputs_dict,
batch_input_metas)
if pts_feats and self.with_pts_bbox:
results_list_3d = self.pts_bbox_head.predict(
pts_feats, batch_data_samples, **kwargs)
else:
results_list_3d = None
if img_feats and self.with_img_bbox:
# TODO check this for camera modality
results_list_2d = self.predict_imgs(img_feats, batch_data_samples,
**kwargs)
else:
results_list_2d = None
detsamples = self.add_pred_to_datasample(batch_data_samples,
results_list_3d,
results_list_2d)
return detsamples
调用函数:img_feats, pts_feats = self.extract_feat(batch_inputs_dict, batch_input_metas)下面将分别做介绍。
首先图像特征提取模块,采用FASTERNCNN结构,resnet50提取特征,然后采用FPN作为neck,调用函数img_feats = self.extract_img_feat(imgs, batch_input_metas)
def extract_img_feat(self, img: Tensor, input_metas: List[dict]) -> dict:
"""Extract features of images."""
if self.with_img_backbone and img is not None:
input_shape = img.shape[-2:]
# update real input shape of each single img
for img_meta in input_metas:
img_meta.update(input_shape=input_shape)
if img.dim() == 5 and img.size(0) == 1:
img.squeeze_()
elif img.dim() == 5 and img.size(0) > 1:
B, N, C, H, W = img.size()
img = img.view(B * N, C, H, W)
img_feats = self.img_backbone(img) # backbone采用resnet50
else:
return None
if self.with_img_neck:
img_feats = self.img_neck(img_feats) #NECK采用FPN网络
return img_feats
"""
img_feats[0].shape: ([1, 256, 176, 232])
img_feats[1].shape: ([1, 256, 88, 116])
img_feats[2].shape: ([1, 256, 44, 58])
img_feats[3].shape: ([1, 256, 22, 29])
img_feats[4].shape: ([1, 256, 11, 15])
"""
点云特征提取与图像点云融合模块,调用函数:pts_feats = self.extract_pts_feat(voxel_dict, points=points, img_feats=img_feats, batch_input_metas=batch_input_metas)
def extract_pts_feat(
self,
voxel_dict: Dict[str, Tensor],
points: Optional[List[Tensor]] = None,
img_feats: Optional[Sequence[Tensor]] = None,
batch_input_metas: Optional[List[dict]] = None
) -> Sequence[Tensor]:
"""Extract features of points.
Args:
voxel_dict(Dict[str, Tensor]): Dict of voxelization infos.
points (List[tensor], optional): Point cloud of multiple inputs.
img_feats (list[Tensor], tuple[tensor], optional): Features from
image backbone.
batch_input_metas (list[dict], optional): The meta information
of multiple samples. Defaults to True.
Returns:
Sequence[tensor]: points features of multiple inputs
from backbone or neck.
"""
if not self.with_pts_bbox:
return None
voxel_features, feature_coors = self.pts_voxel_encoder(
voxel_dict['voxels'], voxel_dict['coors'], points, img_feats,
batch_input_metas) # torch.Size([11986, 128]) torch.Size([11986, 4])# 见类DynamicVFE,完成点云特征处理以及融合
batch_size = voxel_dict['coors'][-1, 0] + 1
x = self.pts_middle_encoder(voxel_features, feature_coors, batch_size) # torch.Size([1, 256, 200, 150])
x = self.pts_backbone(x) # 2x5个2D卷积层 输出为两个特征图,分别为torch.Size([1, 128, 200, 150])torch.Size([1, 256, 100, 75])
if self.with_pts_neck:
x = self.pts_neck(x) # 采用反卷积对齐连个特征图为torch.Size([1, 256, 200, 150]),最后concat torch.Size([1, 512, 200, 150])
return x
点云特征处理以及融合模块, 调用函数:self.pts_voxel_encoder(voxel_dict['voxels'], voxel_dict['num_points'], voxel_dict['coors'], img_feats, batch_input_metas)
见类DynamicVFE:
def forward(self,
features: Tensor,
coors: Tensor,
points: Optional[Sequence[Tensor]] = None,
img_feats: Optional[Sequence[Tensor]] = None,
img_metas: Optional[dict] = None,
*args,
**kwargs) -> tuple:
"""Forward functions.
self.pts_voxel_encoder(
voxel_dict['voxels'], voxel_dict['coors'], points, img_feats,
batch_input_metas)
Args:
features (torch.Tensor): Features of voxels, shape is NxC.
coors (torch.Tensor): Coordinates of voxels, shape is Nx(1+NDim).
points (list[torch.Tensor], optional): Raw points used to guide the
multi-modality fusion. Defaults to None.
img_feats (list[torch.Tensor], optional): Image features used for
multi-modality fusion. Defaults to None.
img_metas (dict, optional): [description]. Defaults to None.
Returns:
tuple: If `return_point_feats` is False, returns voxel features and
its coordinates. If `return_point_feats` is True, returns
feature of each points inside voxels.
"""
features_ls = [features] # features is just points
# Find distance of x, y, and z from cluster center
if self._with_cluster_center: # True
voxel_mean, mean_coors = self.cluster_scatter(features, coors)#torch.Size([11986, 4])
points_mean = self.map_voxel_center_to_point(
coors, voxel_mean, mean_coors)
# TODO: maybe also do cluster for reflectivity
f_cluster = features[:, :3] - points_mean[:, :3]
features_ls.append(f_cluster) # 加入去中心点后的特征
# Find distance of x, y, and z from pillar center
if self._with_voxel_center:
f_center = features.new_zeros(size=(features.size(0), 3))
f_center[:, 0] = features[:, 0] - (
coors[:, 3].type_as(features) * self.vx + self.x_offset)
f_center[:, 1] = features[:, 1] - (
coors[:, 2].type_as(features) * self.vy + self.y_offset)
f_center[:, 2] = features[:, 2] - (
coors[:, 1].type_as(features) * self.vz + self.z_offset)
features_ls.append(f_center)# 加入去pillar中心点后的特征
if self._with_distance:
points_dist = torch.norm(features[:, :3], 2, 1, keepdim=True)
features_ls.append(points_dist)
# Combine together feature decorations
features = torch.cat(features_ls, dim=-1) # torch.Size([23878, 10])
for i, vfe in enumerate(self.vfe_layers):
point_feats = vfe(features) # 全连接 + ReLU # 进入融合层是torch.Size([23878, 64])
if (i == len(self.vfe_layers) - 1 and self.fusion_layer is not None
and img_feats is not None):
point_feats = self.fusion_layer(img_feats, points, point_feats,
img_metas) # 融合 #torch.Size([23878, 128])
voxel_feats, voxel_coors = self.vfe_scatter(point_feats, coors) #voxel 化
if i != len(self.vfe_layers) - 1:
# need to concat voxel feats if it is not the last vfe
feat_per_point = self.map_voxel_center_to_point(
coors, voxel_feats, voxel_coors)
features = torch.cat([point_feats, feat_per_point], dim=1)
if self.return_point_feats:
return point_feats
return voxel_feats, voxel_coors
融合层,调用函数:point_feats = self.fusion_layer(img_feats, points, point_feats, img_metas) # 最后一层开始融合
见类PointFusion:
def forward(self, img_feats: List[Tensor], pts: List[Tensor],
pts_feats: Tensor, img_metas: List[dict]) -> Tensor:
"""Forward function.
Args:
img_feats (List[Tensor]): Image features.
pts: (List[Tensor]): A batch of points with shape N x 3.
pts_feats (Tensor): A tensor consist of point features of the
total batch.
img_metas (List[dict]): Meta information of images.
Returns:
Tensor: Fused features of each point.
"""
# pts_feats.shape = torch.Size([23878, 64])
# 利用点云在图像上的对应坐标, 去各level特征图中采样出和点云点数N对应的点。这个过程是points级别。
img_pts = self.obtain_mlvl_feats(img_feats, pts, img_metas) # torch.Size([23878, 640])
img_pre_fuse = self.img_transform(img_pts) # 全连接 + BN torch.Size([23878, 128])
if self.training and self.dropout_ratio > 0:
img_pre_fuse = F.dropout(img_pre_fuse, self.dropout_ratio)
pts_pre_fuse = self.pts_transform(pts_feats) # 全连接 + BN torch.Size([23878, 128])
fuse_out = img_pre_fuse + pts_pre_fuse # 直接将两者特征图相加融合
if self.activate_out:
fuse_out = F.relu(fuse_out)
if self.fuse_out: # false
fuse_out = self.fuse_conv(fuse_out)
return fuse_out #torch.Size([23878, 128])
融合后的特征输入稀疏卷积,调用函数: x = self.pts_middle_encoder(voxel_features, voxel_dict['coors'], batch_size),
见类SparseEncoder:
def forward(self, voxel_features: Tensor, coors: Tensor,
batch_size: int) -> Union[Tensor, Tuple[Tensor, list]]:
"""Forward of SparseEncoder.
Args:
voxel_features (torch.Tensor): Voxel features in shape (N, C).
coors (torch.Tensor): Coordinates in shape (N, 4),
the columns in the order of (batch_idx, z_idx, y_idx, x_idx).
batch_size (int): Batch size.
Returns:
torch.Tensor | tuple[torch.Tensor, list]: Return spatial features
include:
- spatial_features (torch.Tensor): Spatial features are out from
the last layer.
- encode_features (List[SparseConvTensor], optional): Middle layer
output features. When self.return_middle_feats is True, the
module returns middle features.
"""
# voxel_features.shape torch.Size([11986, 128]) coors.shape torch.Size([11986, 4])
coors = coors.int()
input_sp_tensor = SparseConvTensor(voxel_features, coors,
self.sparse_shape, batch_size) # 根据voxel特征和voxel坐标以及空间形状和batch,建立稀疏tensor
x = self.conv_input(input_sp_tensor) # 子流线稀疏卷积+BN+Relu
encode_features = []
for encoder_layer in self.encoder_layers:
x = encoder_layer(x)
encode_features.append(x)
# for detection head
# [200, 176, 5] -> [200, 176, 2]
out = self.conv_out(encode_features[-1])
spatial_features = out.dense() # torch.Size([1, 128, 2, 200, 150])
N, C, D, H, W = spatial_features.shape
spatial_features = spatial_features.view(N, C * D, H, W) # torch.Size([1, 256, 200, 150])
if self.return_middle_feats:
return spatial_features, encode_features
else:
return spatial_features # torch.Size([1, 256, 200, 150])
将稀疏卷积处理后的融合特征输入second网络处理,调用函数:x = self.pts_backbone(x)
类SECOND:
def forward(self, x: Tensor) -> Tuple[Tensor, ...]:
"""Forward function.
Args:
x (torch.Tensor): Input with shape (N, C, H, W).
Returns:
tuple[torch.Tensor]: Multi-scale features.
"""
outs = []
for i in range(len(self.blocks)):
x = self.blocks[i](x)
outs.append(x)
return tuple(outs)# 2x5个2D卷积层 输出为两个特征图,分别为torch.Size([1, 128, 200, 150])torch.Size([1, 256, 100, 75])
接着送入SECONDFPN网络:调用函数:if self.with_pts_neck: x = self.pts_neck(x)
见类SECONDFPN:
def forward(self, x):
"""Forward function.
Args:
x (List[torch.Tensor]): Multi-level features with 4D Tensor in
(N, C, H, W) shape.
Returns:
list[torch.Tensor]: Multi-level feature maps.
"""
assert len(x) == len(self.in_channels)
ups = [deblock(x[i]) for i, deblock in enumerate(self.deblocks)] # 反卷积操作,把两个特征图分辨率对齐为torch.Size([1, 128, 200, 150])
if len(ups) > 1:
out = torch.cat(ups, dim=1)
else:
out = ups[0]
return [out] # torch.Size([1, 512, 200, 150])
至此,我们完成了图像特征提取,点云特征提取、点云特征图像特征融合几个过程,得到了img_feats, pts_feats两个输出。数据维度如下:
img_feats, pts_feats = self.extract_feat(batch_inputs_dict, batch_input_metas)
"""
img_feats[0].shape: ([1, 256, 176, 232])
img_feats[1].shape: ([1, 256, 88, 116])
img_feats[2].shape: ([1, 256, 44, 58])
img_feats[3].shape: ([1, 256, 22, 29])
img_feats[4].shape: ([1, 256, 11, 15])
pts_feats[0].shape: torch.Size([1, 512, 200, 150])
"""
当执行前向推理预测时,调用:
def predict(self, batch_inputs_dict: Dict[str, Optional[Tensor]],
batch_data_samples: List[Det3DDataSample],
**kwargs) -> List[Det3DDataSample]:
"""Forward of testing.
Args:
batch_inputs_dict (dict): The model input dict which include
'points' keys.
- points (list[torch.Tensor]): Point cloud of each sample.
batch_data_samples (List[:obj:`Det3DDataSample`]): The Data
Samples. It usually includes information such as
`gt_instance_3d`.
Returns:
list[:obj:`Det3DDataSample`]: Detection results of the
input sample. Each Det3DDataSample usually contain
'pred_instances_3d'. And the ``pred_instances_3d`` usually
contains following keys.
- scores_3d (Tensor): Classification scores, has a shape
(num_instances, )
- labels_3d (Tensor): Labels of bboxes, has a shape
(num_instances, ).
- bbox_3d (:obj:`BaseInstance3DBoxes`): Prediction of bboxes,
contains a tensor with shape (num_instances, 7).
"""
batch_input_metas = [item.metainfo for item in batch_data_samples]
img_feats, pts_feats = self.extract_feat(batch_inputs_dict,
batch_input_metas)
if pts_feats and self.with_pts_bbox: # false
results_list_3d = self.pts_bbox_head.predict(
pts_feats, batch_data_samples, **kwargs)
else:
results_list_3d = None
if img_feats and self.with_img_bbox:
# TODO check this for camera modality
results_list_2d = self.predict_imgs(img_feats, batch_data_samples,
**kwargs)
else:
results_list_2d = None
detsamples = self.add_pred_to_datasample(batch_data_samples,
results_list_3d,
results_list_2d)
return detsamples
点云特征进入pts_bbox头,调用函数:if pts_feats and self.with_pts_bbox: results_list_3d = self.pts_bbox_head.predict( pts_feats, batch_data_samples, **kwargs)文章来源:https://www.toymoban.com/news/detail-776081.html
见类Anchor3DHead:
def predict(self,
x: Tuple[Tensor],
batch_data_samples: SampleList,
rescale: bool = False) -> InstanceList:
"""Perform forward propagation of the 3D detection head and predict
detection results on the features of the upstream network.
Args:
x (tuple[Tensor]): Multi-level features from the
upstream network, each is a 4D-tensor.
batch_data_samples (List[:obj:`Det3DDataSample`]): The Data
Samples. It usually includes information such as
`gt_instance_3d`, `gt_pts_panoptic_seg` and
`gt_pts_sem_seg`.
rescale (bool, optional): Whether to rescale the results.
Defaults to False.
Returns:
list[:obj:`InstanceData`]: Detection results of each sample
after the post process.
Each item usually contains following keys.
- scores_3d (Tensor): Classification scores, has a shape
(num_instances, )
- labels_3d (Tensor): Labels of bboxes, has a shape
(num_instances, ).
- bboxes_3d (BaseInstance3DBoxes): Prediction of bboxes,
contains a tensor with shape (num_instances, C), where
C >= 7.
"""
batch_input_metas = [
data_samples.metainfo for data_samples in batch_data_samples
]
outs = self(x) # return multi_apply(self.forward_single, x)->return tuple(map(list, zip(*map_results)))
# 返回值为([cls_score], [bbox_pred], [dir_cls_pred])
predictions = self.predict_by_feat(
*outs, batch_input_metas=batch_input_metas, rescale=rescale) # rescale = false 一堆后处理,有anchor生成等,后续需要细看。
return predictions
图像特征进入图像头:源代码中没有图像头。
最后得出结果,调用函数:detsamples = self.add_pred_to_datasample(batch_data_samples, results_list_3d, results_list_2d)文章来源地址https://www.toymoban.com/news/detail-776081.html
def add_pred_to_datasample(
self,
data_samples: SampleList,
data_instances_3d: OptInstanceList = None,
data_instances_2d: OptInstanceList = None,
) -> SampleList:
"""Convert results list to `Det3DDataSample`.
Subclasses could override it to be compatible for some multi-modality
3D detectors.
Args:
data_samples (list[:obj:`Det3DDataSample`]): The input data.
data_instances_3d (list[:obj:`InstanceData`], optional): 3D
Detection results of each sample.
data_instances_2d (list[:obj:`InstanceData`], optional): 2D
Detection results of each sample.
Returns:
list[:obj:`Det3DDataSample`]: Detection results of the
input. Each Det3DDataSample usually contains
'pred_instances_3d'. And the ``pred_instances_3d`` normally
contains following keys.
- scores_3d (Tensor): Classification scores, has a shape
(num_instance, )
- labels_3d (Tensor): Labels of 3D bboxes, has a shape
(num_instances, ).
- bboxes_3d (Tensor): Contains a tensor with shape
(num_instances, C) where C >=7.
When there are image prediction in some models, it should
contains `pred_instances`, And the ``pred_instances`` normally
contains following keys.
- scores (Tensor): Classification scores of image, has a shape
(num_instance, )
- labels (Tensor): Predict Labels of 2D bboxes, has a shape
(num_instances, ).
- bboxes (Tensor): Contains a tensor with shape
(num_instances, 4).
"""
assert (data_instances_2d is not None) or \
(data_instances_3d is not None),\
'please pass at least one type of data_samples'
if data_instances_2d is None: # 赋了一个空值
data_instances_2d = [
InstanceData() for _ in range(len(data_instances_3d))
]
if data_instances_3d is None:
data_instances_3d = [
InstanceData() for _ in range(len(data_instances_2d))
]
for i, data_sample in enumerate(data_samples):
data_sample.pred_instances_3d = data_instances_3d[i]
data_sample.pred_instances = data_instances_2d[i]
return data_samples
到了这里,关于MVX-net3D算法笔记的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!