【思路】
1.下载文件用requests库最方便,因为可以获取错误码,可以自定义保存文件名,且不用判断文件是否已经下载完成。
2.解析需要下载的地址,得到视频和音频文件下载地址
3.合成视频和音频,得到最终mp4文件。
本次涉及视频操作,故需要安装如下库:
pip install requests moviepy
【范例代码】
import requests
import json
import re
from moviepy.video.io.VideoFileClip import VideoFileClip
from moviepy.audio.io.AudioFileClip import AudioFileClip
def get_bilibili_video_url(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}
response = requests.get(url, headers=headers)
html = response.text
# 使用正则表达式提取视频信息
match_result = re.search(r'__playinfo__=(.*?)</script>', html)
if match_result:
play_info_str = match_result.group(1)
play_info_dict = json.loads(play_info_str)
# 获取视频下载链接
dash_info = play_info_dict['data']['dash']
video_info = dash_info['video'][0]
audio_info = dash_info['audio'][0]
video_url = video_info['base_url']
audio_url = audio_info['base_url']
return video_url, audio_url
else:
raise Exception('无法解析视频信息')
# 示例使用:
bilibili_url = "https://www.bilibili.com/video/BV17w411C7M8"
video_url, audio_url = get_bilibili_video_url(bilibili_url)
print("B站视频下载地址:", video_url)
print("B站音频下载地址:", audio_url)
# 下载视频和音频
video_content = requests.get(video_url).content
audio_content = requests.get(audio_url).content
# 保存视频和音频到本地文件
with open('video.mp4', 'wb') as f:
f.write(video_content)
with open('audio.mp3', 'wb') as f:
f.write(audio_content)
# 加载视频和音频,合并为一个MP4文件
video_clip = VideoFileClip('video.mp4')
audio_clip = AudioFileClip('audio.mp3')
final_video_clip = video_clip.set_audio(audio_clip)
final_video_clip.write_videofile('final.mp4')
print("合并完成,输出文件:final.mp4")
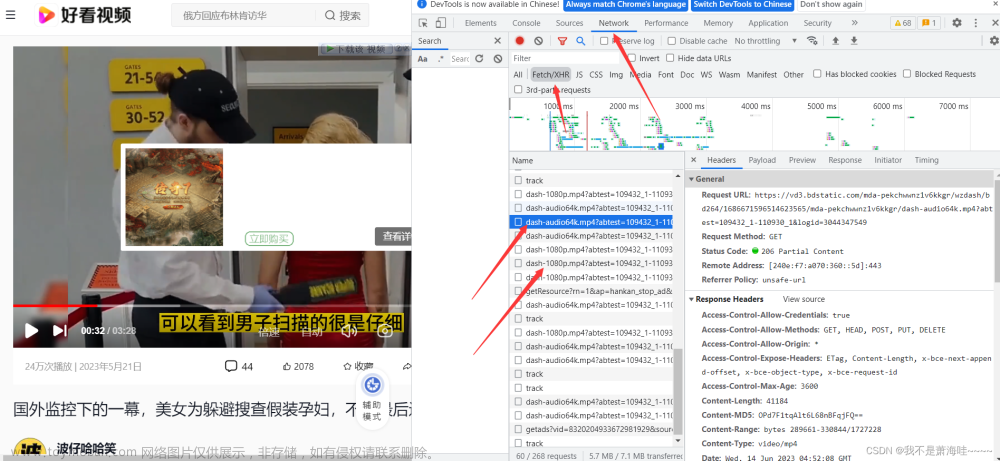
【执行效果】
见下图。
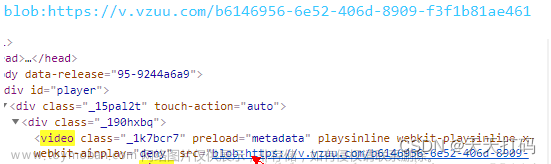
 播放最终下载视频效果,如下:
播放最终下载视频效果,如下:
 文章来源:https://www.toymoban.com/news/detail-776150.html
文章来源:https://www.toymoban.com/news/detail-776150.html
【发文章不易,请多多点赞、关注、支持!】文章来源地址https://www.toymoban.com/news/detail-776150.html
到了这里,关于python爬虫练习系列之二:下载B站视频的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!