SQL/HQL
HQL(Hibernate Query Language) 是面向对象的查询语言
SQL的操作对象是数据列、表等数据库数据 ; 而HQL操作的是类、实例、属性
#FROM
String hql = "from com.demo.bean.User" = "select * from user"
#WHERE
"form User u where u.id = 1 " = "select * form user where id = 1"
#查询出一个String/或者其他类型的属性,封装为List<Object>
public List<String> getAllUsernames(){
Session session = new HibernateSessionFactory().getSession();
String hql = "select u.username from User as u where status = 0";
Query query = session.createQuery(hql);
List<String> list = query.list(); //返回出的List对象中,封装的对象的类型,看具体的情况而定的
return list;
}
#使用统计函数
String hql = "select count(*) from User where status = 0";
String hql = "select count(*),min(u.age) from User as u where status = 0";
#分组和排序
String hql = “select u.username form User as u order by u.age desc” 按年龄的降序排列取出姓名
String hql =”select count(user),age from User group by age having count(user)>3”;
#实体更新和删除 HQL对数据库的修改操作,需要事务来实现
有条件删除 String hql = "delete from User where age<15";
有条件更新 String hql = "update User set username='tom' where id=2";
public void updateSome(){
Session session = new HibernateSessionFactory().getSession();
String hql = "update User set username='tom' where id=2";
Query query = session.createQuery(hql);
Transaction tr = session.beginTransaction();
query.executeUpdate();
tr.commit();
session.close();
}
#参数绑定
顺序占位符:用?来代表参数,用query.setXxx(0, ??); 给参数赋值,参数的序号从0开始
String hql = "update User set username=? where id=?";
引用占位符:用“:占位字符串”实现
String hql = "from User where username=:username and password =:password";
数据仓库基本理论
数据仓库的定义 英文名称为Data Warehouse,可简写为DW或DWH。
为企业级别的决策制定过程,提供所有类型数据支持的战略集合。
它出于分析性报告和决策支持目的而创建,为需要业务智能的企业,提供指导业务流程改进、监视时间、成本、质量以及控制。
数据仓库的意义 根据以往的数据进行分析,优化流程和确定决策
数据仓库的特点 面向对象的、集成的、不可更新的、随时间变化的
数据仓库和数据库的区别
数据库 OLTP用于存放数据的仓库;数据库软件用来实现数据库的逻辑功能
数据仓库 OLAP主要用于数据挖掘和数据分析,辅助领导做决策
在IT架构体系,需要一个放数据的地方,这个地方就是数据库
在BI方面,数据库的表设计往往是某个应用,但针对数据分析和挖掘较为困难;数据仓库的表结构是按照分析需求、分析维度、** 分析指标**进行设计的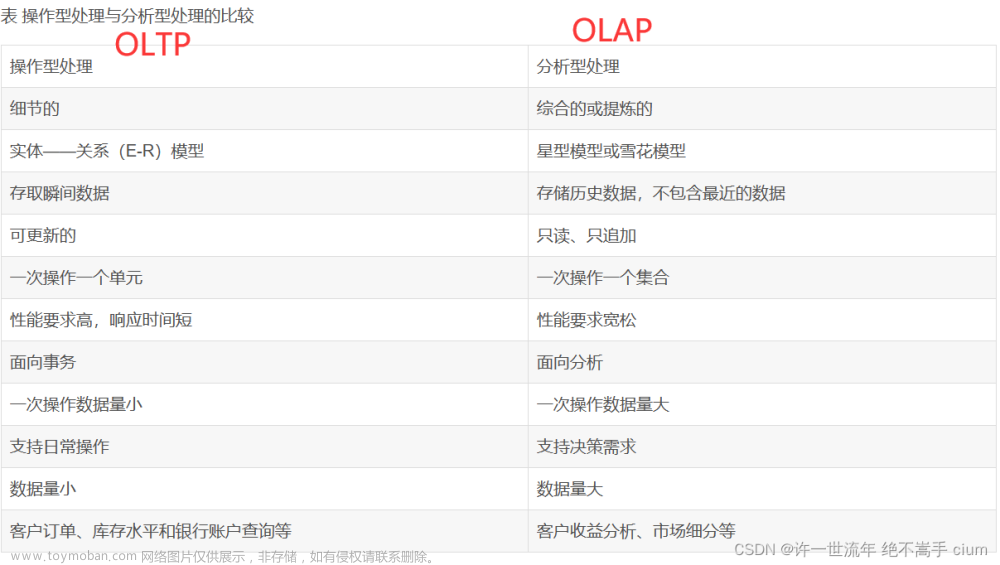
数据仓库分层ODS(临时存储层)、PDW(数据仓库层)、DM(数据集市层)、APP(应用层)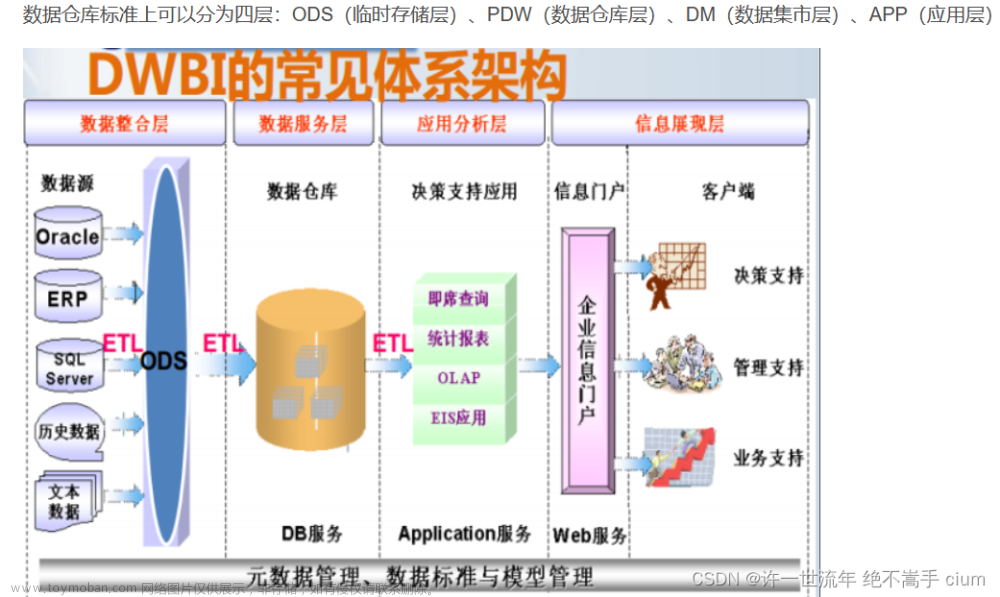
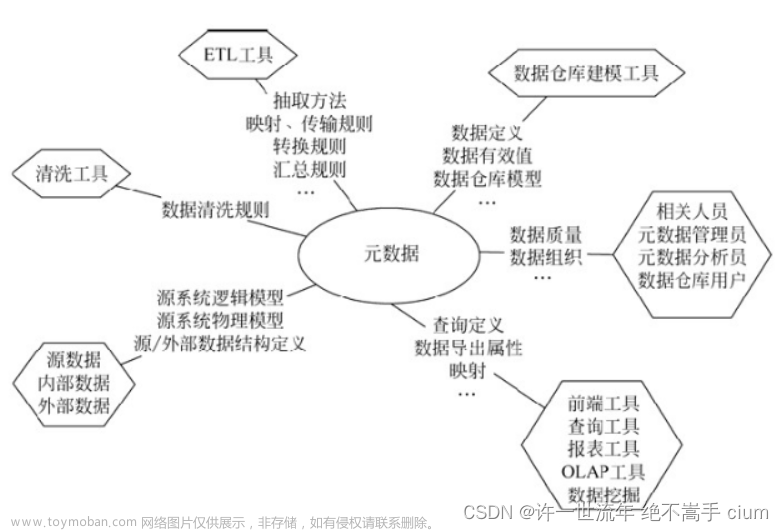
SQL性能调优
sql执行流程
1、客户端请求到服务端,服务端通过数据库连接池,用JDBC连接数据库驱动。
2、数据库端的连接池接收到服务端的连接,然后把服务端对数据库的请求交给数据库的线程。
3、通过数据库获取SQL接口,获取到连接中的SQL语句。
4、然后是通过数据库解析器对SQL进行解析(解析成数据库认识的语言)。
5、然后通过SQL查询优化器获得最优执行SQL。
6、最终把最优SQL交给数据库执行器。
7、执行器选择当前数据库的存储引擎(图例采用InnoDB为例)。
8、然后先去数据库的BufferPool(缓存)中查询,这里如果命中了缓存则直接返回结果。
9、如果没有在缓存中命中结果,那么会去硬盘中读取数据,然后返回结果集并缓存起来,以便下次取用。
数据库使用规范
1、表命名必须小写字母且下划线分割单词;
2、表名称及字段名称不要用数据库的关键字;
3、数据库表命名不超过32个字符;
4、遵循数据库三范式;
5、合理的反三范式使用(比如合理的冗余字段再一张表)
sql调优技巧
1.合理使用索引
(B树索引常用于有序数据的访问,而哈希索引则常用于无序数据的访问。在使用索引时,需要根据实际情况选择合适的索引类型,避免使用不必要的索引。同时,建议为频繁访问的列创建索引,以提升查询效率。)
2.避免全表扫描
(优化SQL查询语句,使用索引和优化器来提升查询效率。在使用索引时,需要保证索引列和查询列保持一致,避免类型不匹配造成查询失败)
3.优化SQL查询语句
(尽可能避免子查询和视图的使用;注意优化日期和时间戳的格式;避免使用SELECT * 查询、避免SELECT DISTINCT 语句)
4.处理大量数据时,需要合理使用查询优化器,避免重复查询和不必要的排序操作
5.削减不必要的数据传输,需要避免传输不必要的数据列、避免重复查询和避免使用JOIN查询等
Kettle、Sqoop等ETL工具
kettle 水壶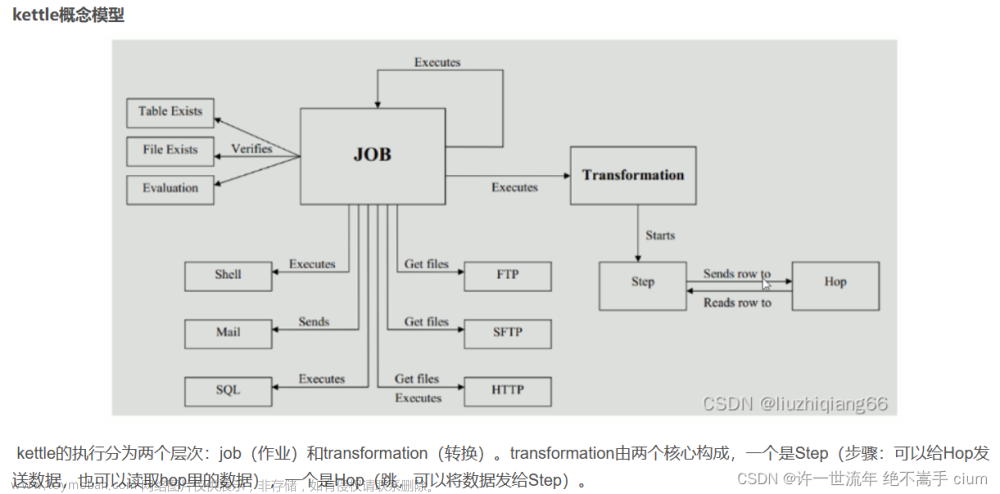
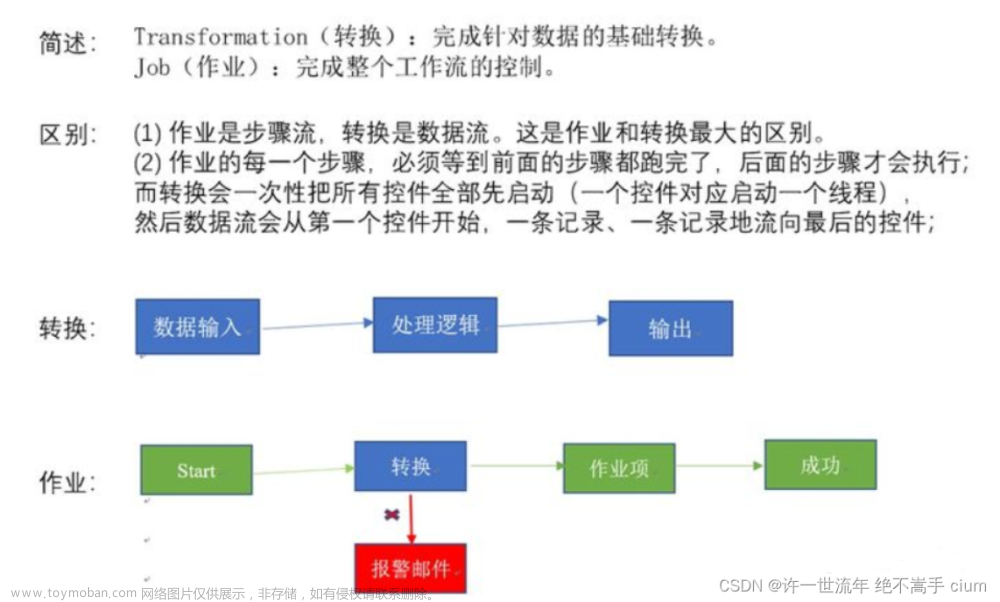
sqoop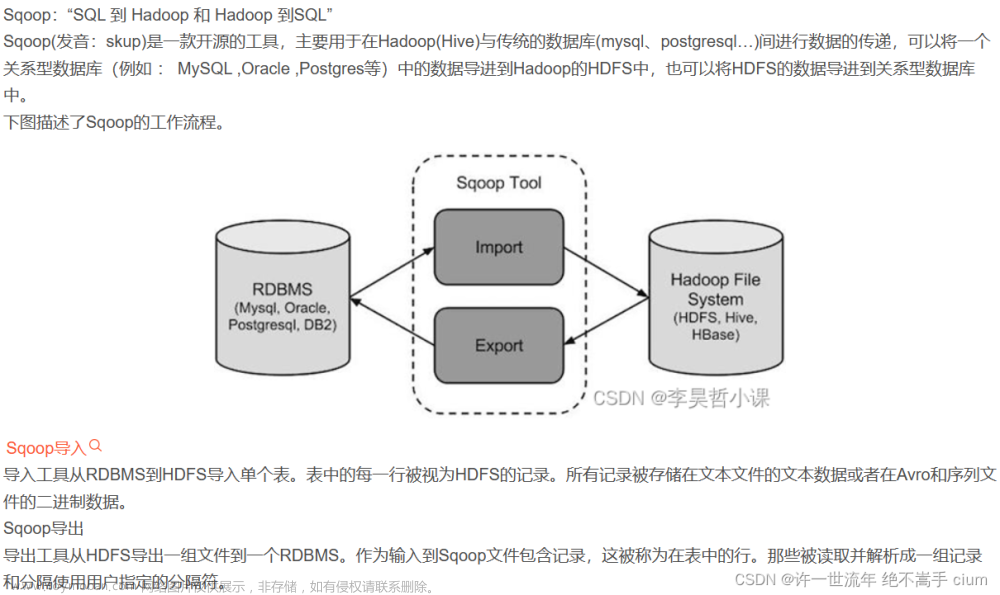
hive sql
Hive SQL是一种基于Hadoop的数据仓库工具
它允许用户使用类似于SQL的语法来查询和分析存储在Hadoop集群中的数据
1. 数据定义语言(DDL):
- 创建数据库:`CREATE DATABASE database_name;`
- 删除数据库:`DROP DATABASE database_name;`
- 显示所有数据库:`SHOW DATABASES;`
- 使用数据库:`USE database_name;`
- 创建表:`CREATE TABLE table_name (column1 data_type, column2 data_type, ...);`
- 删除表:`DROP TABLE table_name;`
- 显示所有表:`SHOW TABLES;`
- 修改表结构:`ALTER TABLE table_name ADD/ALTER/DROP COLUMN column_name data_type;`
2. 数据操作语言(DML):
- 插入数据:`INSERT INTO table_name (column1, column2, ...) VALUES (value1, value2, ...);`
- 查询数据:`SELECT column1, column2, ... FROM table_name WHERE condition;`
- 更新数据:`UPDATE table_name SET column1 = value1, column2 = value2, ... WHERE condition;`
- 删除数据:`DELETE FROM table_name WHERE condition;`
3. 数据查询语言(DQL):
- 聚合函数:`COUNT(), SUM(), AVG(), MIN(), MAX()`
- 分组:`GROUP BY column1, column2, ... HAVING condition;`
- 排序:`ORDER BY column1 ASC/DESC, column2 ASC/DESC, ...;`
- 分页:`LIMIT start, count;`
- 连接查询:`JOIN table1 ON table1.column = table2.column;`
- 子查询:`SELECT * FROM table_name WHERE column IN (SELECT column FROM another_table);`
4. 数据控制语言(DCL):
- 授权:`GRANT permissions ON database_name.table_name TO user_name;`
- 撤销权限:`REVOKE permissions ON database_name.table_name FROM user_name;`
- 创建用户:`CREATE USER user_name IDENTIFIED BY password;`
- 删除用户:`DROP USER user_name;`
5. 其他常用语句:
- 查看表结构:`DESCRIBE table_name;`
- 查看表详情:`DESCRIBE FORMATTED table_name;`
- 查看表分区:`SHOW PARTITIONS table_name;`
- 查看表统计信息:`ANALYZE table_name;`
- 查看表数据文件位置:`MSCK REPAIR table_name;`
hive sql和SQL的区别文章来源:https://www.toymoban.com/news/detail-776226.html
1.hive不支持等值连接,一般使用left join、right join 或者inner join替代。
2、分号字符
分号是sql语句的结束符号,在hive中也是,但是hive对分号的识别没有那么智能,有时需要进行转义 “;” --> “\073”
3、NULL
sql中null代表空值,但是在Hive中,String类型的字段若是空(empty)字符串,即长度为0,那么对它 is null 判断结果为False
4、Hive不支持将数据插入现有的表或分区中
Hive仅支持覆盖重写整个表。
insert overwrite 表 (重写覆盖)
5、Hive不支持 Insert into 表 Values(), UPDATA , DELETE 操作
insert into 就是往表或者分区中追加数据。
6、Hive支持嵌入mapreduce程序,来处理复杂的逻辑
7、Hive支持将转换后的数据直接写入不同的表,还能写入分区,hdfs和本地目录
需避免多次扫描输入表的开销。
8、HQL不支持行级别的增、改、删,所有数据在加载时就已经确定,不可更改。
python
基础语法 文章来源地址https://www.toymoban.com/news/detail-776226.html
Python的六大数据类型如下所示:
(1)数字(Numbers):int(整型),long(长整型),complex(复数),float(浮点型),bool(布尔型);
(2)字符串(String):"Python",'Python';
(3)列表(List):[1,2,3,4],[5,6,7,[8,9],10];
(4)字典(Dictionary):{1:"study",2:"Python"};
(5)元组(Tuple):(1, "shuai",2);
(6)集合(Set):{'P', 'y', 't', 'h', 'o', 'n'}
不可变数据(3 个):Number(数字)、String(字符串)、Tuple(元组)
可变数据(3 个) :List(列表)、Dictionary(字典)、Set(集合)
列表支持字符,数字,字符串甚至可以包含列表(也就是嵌套)
元组用"()"标识。内部元素用逗号隔开。但是元素不能二次赋值,相当于只读列表。
字典用"{ }"标识。字典由索引 (key) 和它对应的值 value 组成,
字典 (dictionary) 是除列表以外 Python 之中最灵活的内置数据结构类型。
列表是有序的对象集合,字典是无序的对象集合。
两者之间的区别在于:字典当中的元素是通过键来存取的,而不是通过偏移存取。
注释
#这是单行注释
"""
这是多行注释
这是多行注释
"""
'''
也可以用三个单引号来进行多行注释
也可以用三个单引号来进行多行注释
'''
分块 python的函数不需要{} 用缩进表示
Python 使用缩进来表示代码块。缩进的空格数是可变的,但是同一个代码块的语句必须包含相同的缩进空格数。
python可以用type函数来检查一个变量的类型:
type(name))
input()函数作为输出流,print()函数作为输入流
到了这里,关于hql、数据仓库、sql调优、hive sql、python的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!