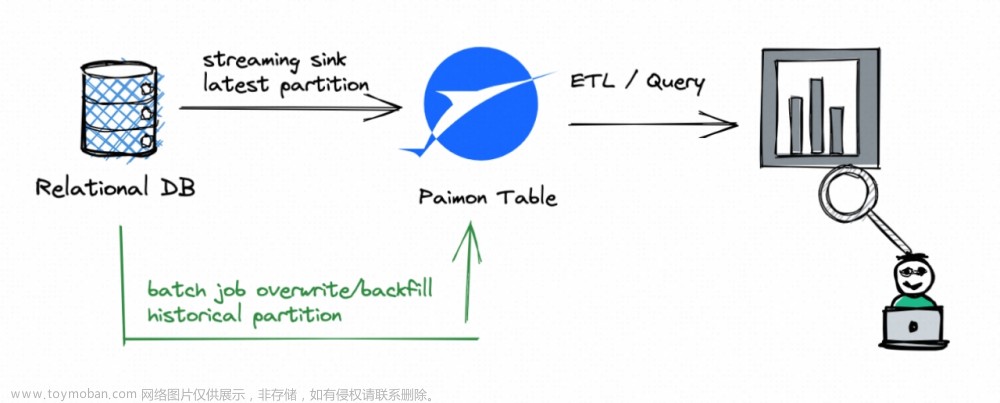
Partial Update
数据打宽
通过不同的流写不同的字段,打宽了数据的维度,填充了数据内容;如下所示:
--FlinkSQL参数设置
set
`table.dynamic-table-options.enabled` = `true`;
SET
`env.state.backend` = `rocksdb`;
SET
`execution.checkpointing.interval` = `60000`;
SET
`execution.checkpointing.tolerable-failed-checkpoints` = `3`;
SET
`execution.checkpointing.min-pause` = `60000`;
--创建Paimon catalog
CREATE CATALOG paimon WITH (
'type' = 'paimon',
'metastore' = 'hive',
'uri' = 'thrift://localhost:9083',
'warehouse' = 'hdfs://paimon',
'table.type' = 'EXTERNAL'
);
--创建Partial update结果表
CREATE TABLE if not EXISTS paimon.dw.order_detail (
`order_id` string,
`product_type` string,
`plat_name` string,
`ref_id` bigint,
`start_city_name` string,
`end_city_name` string,
`create_time` timestamp(3),
`update_time` timestamp(3),
`dispatch_time` timestamp(3),
`decision_time` timestamp(3),
`finish_time` timestamp(3),
`order_status` int,
`binlog_time` bigint,
PRIMARY KEY (order_id) NOT ENFORCED
) WITH (
'bucket' = '20',
-- 指定20个bucket
'bucket-key' = 'order_id',
-- 记录排序字段
'sequence.field' = 'binlog_time',
-- 选择 full-compaction ,在compaction后产生完整的changelog
'changelog-producer' = 'full-compaction',
-- compaction 间隔时间
'changelog-producer.compaction-interval' = '2 min',
'merge-engine' = 'partial-update',
-- 忽略DELETE数据,避免运行报错
'partial-update.ignore-delete' = 'true'
);
INSERT INTO
paimon.dw.order_detail
-- order_info表提供主要字段
SELECT
order_id,
product_type,
plat_name,
ref_id,
cast(null as string) as start_city_name,
cast(null as string) as end_city_name,
create_time,
update_time,
dispatch_time,
decision_time,
finish_time,
order_status,
binlog_time
FROM
paimon.ods.order_info
/*+ OPTIONS ('scan.mode'='latest') */
union
all
-- order_address表提供城市字段
SELECT
order_id,
cast(null as string) as product_type,
cast(null as string) as plat_name,
cast(null as bigint) as ref_id,
start_city_name,
end_city_name,
cast(null as timestamp(3)) as create_time,
cast(null as timestamp(3)) as update_time,
cast(null as timestamp(3)) as dispatch_time,
cast(null as timestamp(3)) as decision_time,
cast(null as timestamp(3)) as finish_time,
cast(null as int) as order_status,
binlog_time
FROM
paimon.ods.order_address
/*+ OPTIONS ('scan.mode'='latest') */
;
完整的Changlog
Paimon中的表被多流填充数据且打宽维度后,支持流读、批读的方式提供完整的Changelog给下游。
Sequence-Group
配置:'fields.G.sequence-group'='A,B'
由字段G控制是否更新字段A, B;总得来说,G的值如果为null或比更新值大将不更新A,B;如下单测
public void testSequenceGroup() {
sql(
"CREATE TABLE SG ("
+ "k INT, a INT, b INT, g_1 INT, c INT, d INT, g_2 INT, PRIMARY KEY (k) NOT ENFORCED)"
+ " WITH ("
+ "'merge-engine'='partial-update', "
+ "'fields.g_1.sequence-group'='a,b', "
+ "'fields.g_2.sequence-group'='c,d');");
sql("INSERT INTO SG VALUES (1, 1, 1, 1, 1, 1, 1)");
// g_2 should not be updated
sql("INSERT INTO SG VALUES (1, 2, 2, 2, 2, 2, CAST(NULL AS INT))");
// select *
assertThat(sql("SELECT * FROM SG")).containsExactlyInAnyOrder(Row.of(1, 2, 2, 2, 1, 1, 1));
// projection
assertThat(sql("SELECT c, d FROM SG")).containsExactlyInAnyOrder(Row.of(1, 1));
// g_1 should not be updated
sql("INSERT INTO SG VALUES (1, 3, 3, 1, 3, 3, 3)");
assertThat(sql("SELECT * FROM SG")).containsExactlyInAnyOrder(Row.of(1, 2, 2, 2, 3, 3, 3));
// d should be updated by null
sql("INSERT INTO SG VALUES (1, 3, 3, 3, 2, 2, CAST(NULL AS INT))");
sql("INSERT INTO SG VALUES (1, 4, 4, 4, 2, 2, CAST(NULL AS INT))");
sql("INSERT INTO SG VALUES (1, 5, 5, 3, 5, CAST(NULL AS INT), 4)");
assertThat(sql("SELECT a, b FROM SG")).containsExactlyInAnyOrder(Row.of(4, 4));
assertThat(sql("SELECT c, d FROM SG")).containsExactlyInAnyOrder(Row.of(5, null));
}
其作用是:
- 在多个数据流更新期间的无序问题。每个数据流都定义自己的序列组。
- 真正的部分更新,而不仅仅是非空值的更新。
- 接受删除记录来撤销部分列。
Changelog-Producer
Paimon通过Changelog-Producer支持生成changelog,并支持下游以流读、批读的形式读取changelog。
Changelog的生成有多种方式,input、lookup、full-compaction;其生成代价是由低到高。
None
不查找旧值,不额外写Changelog;但会下游任务中通过ChangelogNormalize算子补足Changelog。
Input
不查找旧值,额外写Changelog;适用与CDC的数据源。
Lookup
查找旧值,额外写Changelog;如果不是CDC数据源,需要通过LookupCompaction查找旧值,即在 compaction 的过程中, 会去向高层查找本次新增 key 的旧值, 如果没有查找到, 那么本次的就是新增 key, 如果有查找到, 那么就生成完整的 UB 和 UA 消息。
Full-Compaction
查找旧值,额外写Changelog;在 full compact 的过程中, 其实数据都会被写到最高层, 所以所有 value 的变化都是可以推演出来的.
数据一致性
通过数据血缘、数据版本实现了数据的一致性保证。
数据版本
通过Flink的checkpoint机制,生成Snapshot并标记版本,即,一个Snapshot对应数据的一个版本。
比如 Job-A 基于 Table-A 的 Snapshot-20 产出了 Table-B 的 Snapshot-11。Job-B 基于 Table-A 的Snapshot-20产出了 Table-C 的 Snapshot-15。那么 Job-C 的查询就应该基于 Table-B 的 Snapshot-11 和 Table-C 的 Snapshot-15 进行计算,明确了数据版本,从而实现计算的一致性。
生成的snapshot-xx,就是数据的版本号。
数据对齐
将 Checkpoint 插入到两个 Snapshot 的数据之间。如果当前的 Snapshot 还没有完全被消费,这个 Checkpoint 的触发会被推迟,从而实现按照 Snapshot 对数据进行划分和对齐。
实现分为两个部分。
- 在提交阶段,需要去血缘关系表中查询上下游表的一致性版本,并且基于查询结果给对应的上游表设置起始的消费位置。
- 在运行阶段,按照消费的 Snapshot 来协调 Checkpoint,在 Flink 的 Checkpoint Coordinator 向 Source 发出 Checkpoint 的请求时,会强制要求将 Checkpoint 插入到两个 Snapshot 的数据之间。如果当前的 Snapshot 还没有完全被消费,这个 Checkpoint 的触发会被推迟,从而实现按照 Snapshot 对数据进行划分和处理。
数据血缘
概念
数据从产生到消费的整个流转过程中所经历的各种转换、处理和流动的轨迹。数据血缘提供了数据的来源、去向以及中间处理过程的透明度,帮助用户理解数据如何在系统中被处理和移动,以及数据是如何从原始状态转化为最终的可消费形态。文章来源:https://www.toymoban.com/news/detail-776371.html
实现
在checkpoint的提交时将数据的血缘关系写入到System Table,记录血缘关系。 文章来源地址https://www.toymoban.com/news/detail-776371.html
文章来源地址https://www.toymoban.com/news/detail-776371.html
到了这里,关于聊聊流式数据湖Paimon(四)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!