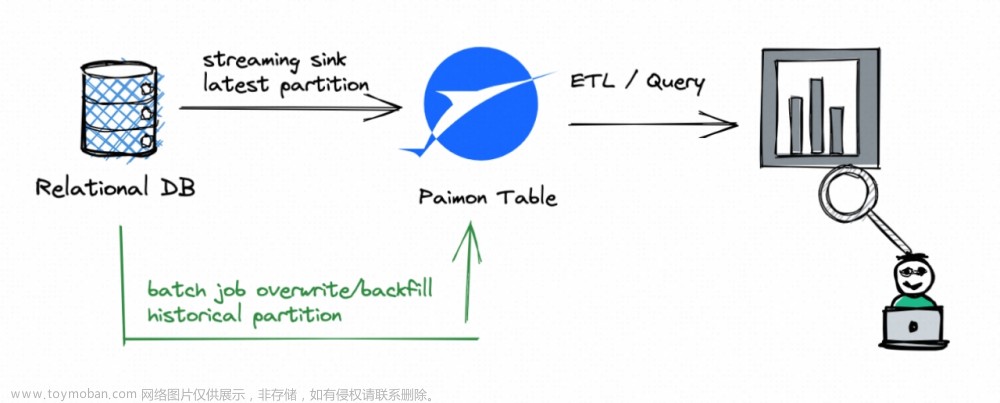
从Demo入手,了解Paimon/Flink项目搭建的全过程。记录下采坑之旅。
创建Flink项目
在IDEA中创建Flink项目,由于没有Flink的archetype,因此需要手动创建一下。
参考:idea快速创建flink项目,至此Flink的项目框架就搭建起来了。
注意:必须注释掉pom文件中的Error: A JNI error has occurred, please check your installation and try again
搭建Flink伪集群
在 Flink包地址 中,选择对应的版本,下载文件
解压后,其文件内容,如下
在bin目录下,运行start-cluster.bat脚本即可。打开浏览器访问:localhost:8081,就可以查看Flink的webui
高版本的Flink中已经没有bat脚本,可参考 flink新版本无bat启动文件的解决办法文章来源:https://www.toymoban.com/news/detail-776376.html
补充缺失的依赖
Flink的框架搭建好之后,参考 新一代数据湖存储技术Apache Paimon入门Demo 写一个简单的Paimon程序。但在这个过程中,必须补充 缺失的POM依赖。而这些依赖在编译时并不会报错,一旦运行,各种各样的抛错:java.lang.ClassNotFoundException: org.apache.hadoop.conf.ConfigurationUnable to create catalog xxxUnsupported SQL query! executeSql()
如下是所有需要的pom依赖:文章来源地址https://www.toymoban.com/news/detail-776376.html
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>${flink.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>${flink.version}</version>
<!-- <scope>provided</scope>-->
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge</artifactId>
<version>1.18.0</version>
</dependency>
<dependency>
<groupId>org.apache.paimon</groupId>
<artifactId>paimon-flink-1.18</artifactId>
<version>0.6.0-incubating</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-loader</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-runtime</artifactId>
<version>1.18.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-base</artifactId>
<version>${flink.version}</version>
</dependency>
<!-- Add connector dependencies here. They must be in the default scope (compile). -->
<!-- Example:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka</artifactId>
<version>3.0.0-1.17</version>
</dependency>
-->
<!-- Add logging framework, to produce console output when running in the IDE. -->
<!-- These dependencies are excluded from the application JAR by default. -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-slf4j-impl</artifactId>
<version>${log4j.version}</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>${log4j.version}</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>${log4j.version}</version>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.2.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs-client</artifactId>
<version>3.2.3</version>
</dependency>
到了这里,关于聊聊流式数据湖Paimon(五)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!