导读:使用Flink实时消费Kafka数据的案例是探索实时数据处理领域的绝佳方式。不仅非常实用,而且对于理解现代数据架构和流处理技术具有重要意义。
理解Flink和Kafka
Apache Flink

Apache Flink 是一个在有界数据流和无界数据流上进行有状态计算分布式处理引擎和框架。Flink 设计旨在所有常见的集群环境中运行,以任意规模和内存级速度执行计算。
---- Apache Flink 官方文档
- 流处理引擎:Flink是一个高性能、可扩展的流处理框架,专门设计用于处理大规模数据流。
核心特性
- 事件驱动:能够处理连续的数据流,适用于实时数据处理场景。
- 精确一次性处理语义(Exactly-once semantics):确保数据不会因为任何原因(如系统故障)而丢失或重复处理。
- 状态管理和容错:提供强大的状态管理能力,并支持故障恢复。
Flink数据流创建
// 创建Flink流执行环境
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 设置数据源,这里假设是某个文件
DataStream<String> text = env.readTextFile("path/to/text");
// 定义数据处理操作
DataStream<String> processed = text
.map(new MapFunction<String, String>() {
@Override
public String map(String value) {
// 实现一些转换逻辑
return "Processed: " + value;
}
});
// 执行数据流
env.execute("Flink DataStream Example");
Apache Kafka

Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。该项目的目标是为处理实时数据提供一个统一、高吞吐、低延迟的平台。
---- 维基百科
- 消息队列系统:Kafka是一个分布式流媒体平台,主要用于构建实时数据管道和流应用程序。
核心特性
- 高吞吐量:Kafka能够处理高速流动的大量数据。
- 可扩展性:可以在不中断服务的情况下增加集群节点。
- 持久性和可靠性:数据可以持久存储在磁盘,并且支持数据备份和复制。
Kafka生产者和消费者
在Kafka中,生产者(producer)将消息发送给Broker,Broker将生产者发送的消息存储到磁盘当中,而消费者(Consumer)负责从Broker订阅并且消费消息,消费者(Consumer)使用pull这种模式从服务端拉取消息。而zookeeper是负责整个集群的元数据管理与控制器的选举。
// Kafka生产者
Properties props = new Properties();
props.put("bootstrap.servers", "localhost:9092");
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = new KafkaProducer<>(props);
producer.send(new ProducerRecord<String, String>("test-topic", "message key", "message value"));
// Kafka消费者
Properties props = new Properties();
props.setProperty("bootstrap.servers", "localhost:9092");
props.setProperty("group.id", "test");
props.setProperty("enable.auto.commit", "true");
props.setProperty("auto.commit.interval.ms", "1000");
props.setProperty("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
props.setProperty("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
Consumer<String, String> consumer = new KafkaConsumer<>(props);
consumer.subscribe(Arrays.asList("test-topic"));
while (true) {
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records)
System.out.printf("offset = %d, key = %s, value = %s%n", record.offset(), record.key(), record.value());
}
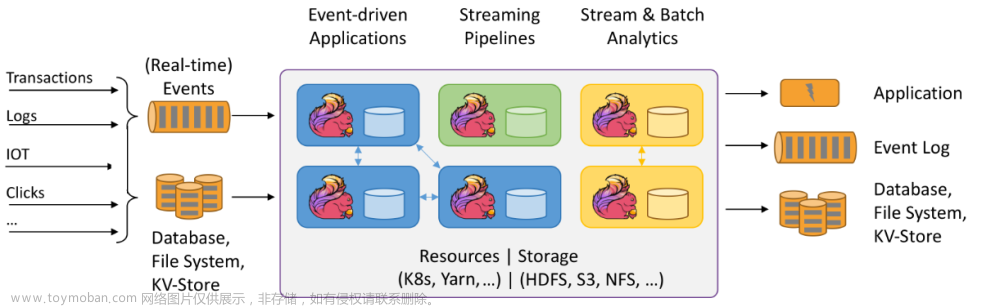
Flink与Kafka结合的优势
- 实时数据流处理:结合Flink的实时处理能力和Kafka的高吞吐量,可以实现复杂的实时数据分析和处理。
- 可靠性和容错性:Flink和Kafka都提供了故障恢复机制,保证数据处理的准确性和可靠性。
Flink与Kafka的集成
前期准备
在开始之前,确保你的开发环境中安装了Apache Flink和Apache Kafka。Flink提供了与Kafka集成的连接器,可以轻松地从Kafka读取数据并将数据写回Kafka。
Flink消费Kafka数据
要使Flink应用能够从Kafka消费数据,需要使用Flink提供的Kafka连接器。
Flink连接Kafka
创建一个Flink应用程序,从名为"topic-name"的Kafka主题中消费数据,并打印出来。
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import java.util.Properties;
public class KafkaFlinkExample {
public static void main(String[] args) throws Exception {
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("group.id", "test");
// 创建Kafka消费者
FlinkKafkaConsumer<String> consumer = new FlinkKafkaConsumer<>(
"topic-name", new SimpleStringSchema(), properties);
// 将消费者添加到数据流
DataStream<String> stream = env.addSource(consumer);
stream.print();
env.execute("Flink Kafka Integration");
}
}
处理Kafka数据流
一旦从Kafka接收数据流,可以利用Flink提供的各种操作对数据进行处理。
我们对从Kafka接收到的每条消息进行了简单的处理,并输出处理后的结果。
DataStream<String> processedStream = stream
.map(new MapFunction<String, String>() {
@Override
public String map(String value) {
return "Processed: " + value;
}
});
processedStream.print();
Flink向Kafka发送数据
除了从Kafka消费数据外,Flink还可以将处理后的数据流发送回Kafka。我们可以创建一个Flink生产者实例,并将处理后的数据流发送到名为"output-topic"的Kafka主题。
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer;
// ...
FlinkKafkaProducer<String> producer = new FlinkKafkaProducer<>(
"output-topic", new SimpleStringSchema(), properties);
processedStream.addSink(producer);
性能优化
调整并行度
- Flink作业的并行度决定了任务的处理速度。可以根据数据量和资源情况调整并行度以优化性能。
env.setParallelism(4);
状态管理和容错
- 状态管理是Flink中的一个核心概念。合理使用状态可以提升应用的性能和容错能力。
- 使用checkpointing机制来定期保存应用状态,从而在出现故障时能够恢复。
env.enableCheckpointing(10000); // 每10000毫秒进行一次checkpoint
选择合适的时间特性
- Flink支持不同的时间特性(如事件时间、处理时间),选择合适的时间特性对于确保应用的准确性和性能至关重要。
----------------文章来源:https://www.toymoban.com/news/detail-776530.html
觉得有用欢迎点赞收藏~ 欢迎评论区交流~文章来源地址https://www.toymoban.com/news/detail-776530.html
到了这里,关于掌握实时数据流:使用Apache Flink消费Kafka数据的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!