温馨提示:文末有 CSDN 平台官方提供的博主 的联系方式,有偿帮忙部署
基于赶集网租房信息的数据分析与可视化
一、实验环境
(1)Linux: Ubuntu 16.04
(2)Python: 3.6
(3)Hadoop:3.1.3(4)Spark: 2.4.0(5)Web框架:flask 1.0.3
(6)可视化工具:Echarts
(7)开发工具:Visual Studio Code
二、小组成员及分工
(1)成员:林xx,xxx,xxx
(2)分工:xxx负责xxxx部分,xxx负责xxxx部分,xxx负责xxxx部分。
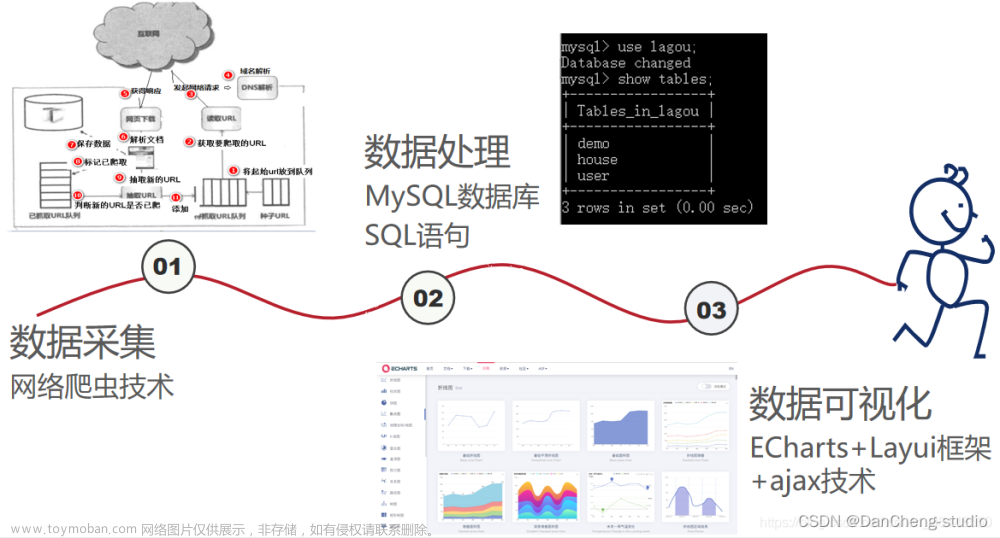
三、数据采集
3.1数据集说明
爬取网站:http://xm.ganji.com/zufang/pn1/。是赶集网的厦门房产的租房信息网站。数据文件:ganji_rent1.csv。其中包含了1504条与租房信息有关的数据。
数据格式为:

图 3. 1 采集数据格式
数据中包含的内容如下:
(1)name: 房源的标题
(2)house_type: 房源的类型
(3)Area: 房源的面积(m²)
(4)direction: 房源的朝向
(5)renovation: 房源的装修程度
(6)price: 房源的月租(元/月)
(7)location:: 房源所处位置
3.2.爬取数据集以及将其保存到本地E盘文件中的流程
(1)选取所需要爬取的页面进行遍历爬取
(2)通过正则表达式抓取所需要的数据
(3)将爬取出的数据转化为dataframe格式并保存为csv文件存放在E盘
四、数据清洗与预处理
略文章来源地址https://www.toymoban.com/news/detail-776573.html
五、spark数据分析
5.1 数据分析目标
本文对音乐专辑数据集ganji_rent1.csv进行了一系列的分析,包括:
(1)房源的房租分布情况。(观察月租价格大体集中在哪个分段,得出月租趋势)
(2)房源的朝向分布情况。(观察房源的基本朝向,得出最佳朝向)
(3)房源的区域分布情况。(观察哪些区域房源多)
(4)房源的房型分布情况。(观察哪种房型数量最多)
(5)房源的面积分布情况。(观察面积大体集中在哪个分段)
(6)房源的装修程度分布情况。(观察房源最基本装修程度)
(7)不同区域的租价分布情况。(观察月租价格大体集中在哪个分段)
(8)热门房源标题词云展示。(观察最热门的标题,得出标题最好应具备的元素)
六、数据可视化
本实验的可视化基于Echarts实现。
6.1.可视化环境
利用和鲸社区虚拟环境进行可视化操作,最后的代码结构如下。
6.2 图表展示与结论分析
(1)通过统计房源的房租分布情况进行数据可视化图表分析

图 6.2.1 房租分布情况
分析结论:通过这个图可以看出月租大体集中在3004500这里,这也说明大部分租房的人租房都会租相对便宜的,比如3002300这里,所以相对的月租便宜的房源也就多,而月租4500以上的房源因为租的人少,所以相对的房源也就少了。虽然数据量很少,但从这也可看300~4500的房源数量有1290,而4500以上的房源只有214,前者时后者的6倍有余,从这我们也可大胆推测,我国中底层收入人数,是中高层收入的6倍左右。
(2)通过统计房源的朝向分布情况进行数据可视化图表分析

图 6.2.2 朝向分布情况
分析结论:通过这个图我们可以看出朝向绝大部分都是南向或者南北向,或者是跟南、北有关的,这也反映了我国房子基本都是“坐北朝南”的。因为我国地处北温带,这样以便于采光通风。这也就是所谓的“南北通透”。
所以:①如果你是租房人想要房间采光透气好,就租南北向的房子,这种房源也比较多也好租到;②如果你是出租房源的人,你的房源最好是要南北向的,这样你的价格也可以租的相比于其他方向的房源的价格高。
(3)通过统计房源的区域分布情况进行数据可视化图表分析

图 6.2.3_1 区域分布情况

图 6.2.3_2 区域分布情况
分析结论:通过这两个图我们可以看出大部分房源都集中在县后,滨海社区,孙板路,高新技术园,软件园等,这些地方都有一些共同的特征,如:附近交通便利,靠近工作区,离相对的市中心有点距离等等。而环岛路等地的房源就相对较少,这也说明虽然那附近的风景优美,但是交通不够便利,只有享受生活的人才会租这些地方,而享受生活的人,大部分也都是有钱了,他们也不会租,他们是直接就买了住了,所以这些地方的房源就相对较少。
所以:①如果你是租房人,你想要租房就可以结合自己工作的地方然后多往县后,滨海社区,孙板路,高新技术园,软件园等这几个地点考虑,这些地点房源多,出行也便利;②如果你是出租房源的人,你就可以多购进这县后,滨海社区,孙板路,高新技术园,软件园等几个地点的房源,这样也会相对其他地方比较好出售。
(4)通过统计房源的房型分布情况进行数据可视化图表分析

图 6.2.4 房型分布情况
分析结论:通过这个图我们可以看出大部分房源都是1室的,这也说明现在租房的人大部分都是打工人,他们基本都是独自一人出来工作,就算是两三人结伴,也基本会一室的房子挤一挤就好,他们在考虑价格方面都会多于房子环境。
所以:①如果你是租房人,你经济不允许的话租一室的就好了,这样也能让你省下不少的房租费,绝大部分人都是如此过来的。②如果你是出租房源的人,在相对靠近集中的工作区的地方,你就可以多购进一室的房源,因为这些地方对于一室的房源需求量大。而在相对靠近市中心的地方,你就可以多购进2室或以上的房源,因为在这些地方租房的人会比较在意房源的环境跟户型。
(5)通过统计房源的面积分布情况进行数据可视化图表分析

图 6.2.5 面积分布情况
分析结论:通过这个图我们可以看出50%左右的房源的面积都是在45m²以下,这就跟上面4)的房型分布相呼应了。也侧面说明了50%左右的租房人是比较不在意房子环境,而比较在意价格的。
(6)通过统计房源的装修程度分布情况进行数据可视化图表分析

图 6.2.6 装修程度分布
分析结论:通过这个图我们可以看出房源的装修程度几乎都是精装修。而毛胚房只有个位数。所以:如果你是出租房源的人,你就应该至少把你的房源简单装修,最好是精装修,虽然这样要花钱,但是你的竞争力也会更大,回本也会更快。
(7)通过统计不同区域的租价分布情况进行数据可视化图表分析

图 6.2.7 不同区域的租价分布
分析结论:因为是经过排序的原因,所以数量基本上分布在左边,所以热力图的左边颜色较深,这也说明了我本身获取的数据量不足,才会导致热力图大部分颜色都很淡。通过图7.1我们可以看出县后、软件园、高新技术产业园,高崎的房源月租集中在3001300、13002300、2300~4500(因为区域过多,所以很多区域需要在可视化出来的图上用鼠标放在热力图上才可以显示位置。),这也说明了在这些地方附近普通打工人居多,而4500以上的房源集中在滨海社区、环东海域、马銮湾新城、瑞景等,这也说明了这些地方附近相对繁荣热闹、或者环境相对优美。
所以:①你想找简单的工作话可以在县后、软件园、高新技术产业园等附近找,这些地方附近月租便宜,而且房源多,也就说明了这些地方附近工作多。而想在比较热闹的地方租房的话可在马銮湾新城、瑞景、滨海社区等地租房,当然月租也很贵。②如果你是租房人话,你可以多在县后、软件园、高新技术产业园等地购进300~2300的房源,这些地方相对低价月租的房源需求量大,而在滨海社区、环东海域、马銮湾新城、瑞景等地就应该购进环境好的房型大的房源。
(8)通过统计热门房源标题进行数据可视化图表分析

图 6.2.8 热门房源标题词云展示
分析结论:通过这个图我们可以看出几乎所有房源标题都会把他们的卖点贴出来,比如几室几厅,位于的地点,装修程度等,这就跟我们日常看到新闻一样,他们都会把比较吸引眼球的点贴出来。
所以:①如果你是租房人,就算它的标题写的再好,你点进去后一定要仔细看一下其他具体的内容,不要盲目就下单,不然很容易被坑。②如果你是出租房源的人,你一定要把你的优势,比如装修程度,位于的地点贴出来,还有可以贴上低价,豪华装修等字眼吸引租房人,这样你的租房信息的浏览量就会往上增,看的人多了,自然把房子租出去的机会也就大了。
七、心得体会文章来源:https://www.toymoban.com/news/detail-776573.html
略
到了这里,关于【大数据实训】基于赶集网租房信息的数据分析与可视化(七)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!