一、资源获取链接
《大规模语言模型:从理论到实践》、复旦大学课件
链接/提取码:x7y6
二、概念整理
定义
大规模语言模型(Large Language Models,LLM),也称大语言模型或大型语言模型,是一种由包含数百亿以上参数的深度神经网络构建的语言模型,通常使用自监督学习方法通过大量无标注文本进行训练。
自2018年以来,Google、OpenAI、Meta、百度、华为等公司和研究机构都相继发布了包括BERT,GPT等在内多种模型,并在几乎所有自然语言处理任务中都表现出色。2019年大模型呈现爆发式的增长,特别是2022年11月ChatGPT(Chat Generative Pre-trained Transformer)发布后,更是引起了全世界的广泛关注。用户可以使用自然语言与系统交互,从而实现包括问答、分类、摘要、翻译、聊天等从理解到生成的各种任务。大规模语言模型展现出了强大的对世界知识掌握和对语言的理解能力。
深度神经网络训练需要采用有监督方法,使用标注数据进行训练,因此,语言模型的训练过程也不可避免需要构造训练语料。
但是由于训练目标可以通过无标注文本直接获得,从而使得模型的训练仅需要大规模无标注文本即可。语言模型也成为了典型的自监督学习(Self-supervised Learning)任务。
互联网的发展,使得大规模文本非常容易获取,因此训练超大规模的基于神经网络的语言模型也成为了可能。
以ELMo为代表的动态词向量模型开启了语言模型预训练的大门。此后,以GPT和BERT为代表的基于Transformer 架构的大规模预训练语言模型的出现,使自然语言处理全面进入预训练微调范式新时代。这类方法通常称为预训练语言模型(Pre-trained Language Models,PLM)。
2020 年,OpenAI 发布了由包含1750 亿参数的神经网络构成的生成式大规模预训练语言模型GPT-3(Generative Pre-trained Transformer 3)。开启了大语言模型的新时代。在不同任务上都进行微调需要消耗大量的计算资源,因此预训练微调范式不再适用于大语言模型。
通过语境学习(In-Context Learning,ICL)等方法,直接使用大语言模型就可以在很多任务的少样本场景下取得很好的效果。此后,研究人员提出了面向大语言模型的提示词(Prompt)学习方法、模型即服务范式(Model as a Service,MaaS)、指令微调(Instruction Tuning)等方法。
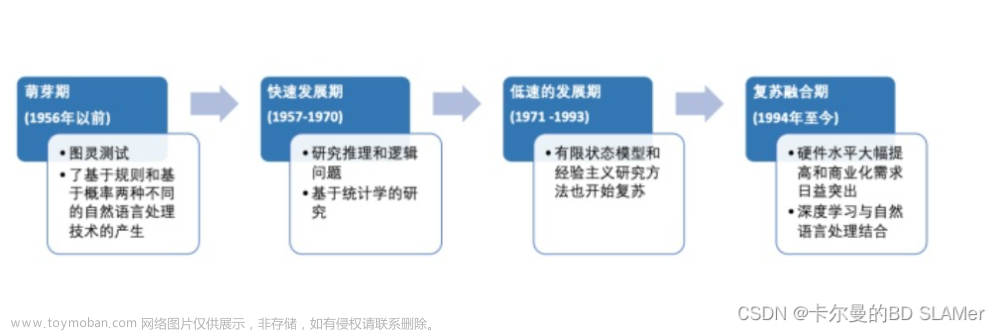
发展历程
大语言模型的发展历程虽然只有短短不到五年,但是发展速度相当惊人,截止2023 年6 月,国内外有超过百种大模型相继发布。

 文章来源:https://www.toymoban.com/news/detail-776681.html
文章来源:https://www.toymoban.com/news/detail-776681.html
大模型的基本构成

预训练(Pretraining)阶段需要利用海量的训练数据,数据来自互联网网页、维基百科、书籍、GitHub、论文、问答网站等,构建包含数千亿甚至数万亿单词的具有多样性的内容。
利用由数千块高性能GPU 和高速网络组成超级计算机,花费数十天完成深度神经网络参数训练,构建基础语言模型(Base Model)
有监督微调(Supervised Finetuning),也称为指令微调,利用少量高质量数据集合,包含用户输入的提示词和对应的理想输出结果。用户输入包括问题、闲聊对话、任务指令等多种形式和任务。
利用这些有监督数据,使用与预训练阶段相同的语言模型训练算法,在基础语言模型的基础上进行训练,得到有监督微调模型(SFT 模型)。
经过训练的SFT 模型具备初步的指令理解能力和上下文理解能力,能够完成开放领域问答、阅读理解、翻译、生成代码等任务,也具备了一定的对未知任务的泛化能力。
很多类ChatGPT的模型都属于该类型,包括Alpaca、Vicuna、MOSS、ChatGLM-6B 等。很多这类模型的效果非常好,甚至在一些评测中达到了ChatGPT 的90% 的效果。
奖励建模(Reward Modeling)阶段的目标是构建一个文本质量对比模型,对于同一个提示词,SFT 模型给出的多个不同输出结果的质量进行排序。奖励模型(RM 模型)可以通过二分类模型,对输入的两个结果之间的优劣进行判断。RM 模型与基础语言模型和SFT 模型不同,RM 模型本身并不能单独提供给用户使用。
奖励模型的训练通常和SFT 模型一样,使用数十块GPU,通过几天时间完成训练。由于RM 模型的准确率对强化学习阶段的效果有至关重要的影响,因此通常需要大规模的训练数据对该模型进行训练。
强化学习(Reinforcement Learning)阶段根据数十万用户给出的提示词,利用前一阶段训练的RM模型,给出SFT模型对用户提示词补全结果的质量评估,并与语言模型建模目标综合得到更好的效果。
使用强化学习,在SFT 模型基础上调整参数,使得最终生成的文本可以获得更高的奖励(Reward)。该阶段需要的计算量相较预训练阶段也少很多,通常仅需要数十块GPU,数天即可完成训练。文章来源地址https://www.toymoban.com/news/detail-776681.html
到了这里,关于大模型语言模型:从理论到实践的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!