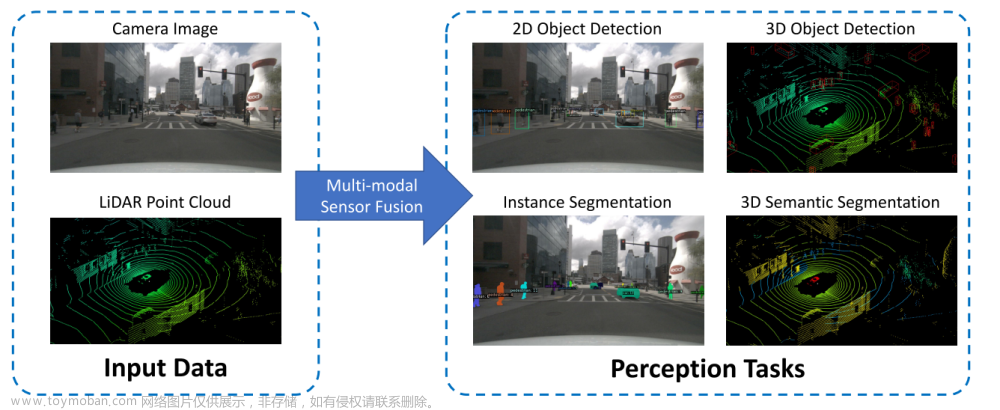
多模态背景
在驾驶场景中,自动驾驶车辆需要精准高效的感知运算,时刻预测其所处的驾驶环境。 其中,感知系统将各种传感器数据转化为语义信息,是自动驾驶系统的核心和不可缺少的组成部分。 图像具有丰富的语义信息,点云包含深度信息。 两者具有互补特性,可以提高三维物体检测精度,帮助车辆更好地感知周围环境。
图像具有丰富的语义信息,点云包含深度信息。 两者具有互补特性,可以提高三维物体检测精度,帮助车辆更好地感知周围环境。
3D 目标检测,可以智能预测车辆附近重要目标的位置、大小和类别,在感知系统中起着基础作用,为下游感知任务提供目标级信息.
最初,仅使用激光雷达点云或图像的单模态方法得到了迅速发展。 然而,只有一种模态有其自身的缺陷。
Y. Guo, H. Wang, Q. Hu, H. Liu, L. Liu, and M. Bennamoun, “Deep learning for 3d point clouds: A survey,” IEEE transactions on pattern analysis and machine intelligence, vol. 43, no. 12, pp. 4338–4364, 2020.
基于点云的方法:由于点云在纹理和遮挡区域提供的信息较差,在远距离时更为严重,因此点云的稀疏性和无序性大大限制了它们的性能。
基于图像的方法:提供了足够的纹理和上下文信息,但没有提供足够的几何信息。
为了解决单一模态的内在局限性,人们提出了多模态方法,希望通过多源融合来提供更好、更完整的 3D 环境感知。
多模态方法
Multi-view 方法提出将来自不同模态的输入融合到同一维度。
frustum-baed 模型为组合异构特征提供了一种新的方法。
基于特征的融合技术在多模态任务中得到了广泛的应用,从而开创了基于特征的多模态三维目标检测方法的发展趋势。
不同维度的特征会产生大量额外的噪声、更多的时间消耗等。
多模态方法主要关注三个问题:
1.数据表示是一个基本的组成部分,要挖掘和总结异构模式的互补性。
2.由于坐标系的异构性,需要确定两个或多个模态之间的关系。
3.要将异构数据组合成联合信息。
比较出名的 3D 目标检测工作:
3D 目标检测背景
3D 目标检测
问题描述
3D 目标检测问题定义为: β ( b 1 , b 2 , . . . , b N ) = F d e t e c t ( α ) (1) \tag{1}\beta(b_{1},b_{2},...,b_{N})=F_{detect}(\alpha) β(b1,b2,...,bN)=Fdetect(α)(1) 其中 β ( b 1 , b 2 , . . . , b N ) \beta(b_{1},b_{2},...,b_{N}) β(b1,b2,...,bN) 表示在一帧视角中一个包含 N N N 个目标状态的集合。 ( b 1 , b 2 , . . . , b N ) (b_{1},b_{2},...,b_{N}) (b1,b2,...,bN) 是 N N N 个 3D 目标。 F d e t e c t F_{detect} Fdetect 是 3D 检测函数, α \alpha α 是输入数据,通常来自于传感器。 b i b_i bi(边界框)通常包含位置、大小、类别等信息,根据模型集可能包含更多信息。
传感器类型
Monocular Camera: 相机捕捉的图像具有丰富的色彩和纹理属性,具有高帧率和可忽略不计的成本优势。 但它缺乏深度信息,易受光照影响。
Stereo Camera: 深度感知能力强,对光照条件不敏感,适合远距离测量和机器人视觉 ;但成本较高,需要校准,易失真,视野有限,不适合透明或反射表面 。
LiDAR: 激光雷达提供高精度、高密度、高分辨率的点云数据,用于目标检测。需要大量的计算资源,并且对不利的天气条件很敏感。
RADAR: 以在大范围内测量点云数据,不受环境条件影响,并探测运动物体。 但其测量精度和目标分辨率较低,且会受到反射干扰的影响。
数据集和评估指标
KITTI
Dataset:由 Karlsruhe Institute of Technology 和 Toyota Institute of Technology 在 2012 年联合创建。KITTI 数据集通过驾驶采集车获取数据,包括来自城市、公路和农村场景的数据。 每帧最多可包含15辆车和30名行人,并有不同程度的遮挡和截断。 该数据集包括 389 个立体图像对、光流图、39.2 km 可视范围序列、15000 个点云帧和 200000 个人工标记的三维目标帧。 数据采集车有两个灰度,两个彩色摄像机,一个Velodyne 64线激光雷达,四个光学镜头和一个GPS导航系统。 KITTI 提供了 3D 感知基准中的原始数据、每个对应基准的不同评估度量,以及测试和比较不同方法性能的在线测试平台。




评估:KITTI 使用
A
P
R
40
APR_{40}
APR40 插值方法作为他们的官方评估方法。 两种类型在官方的KITTI评估中排名,包括 3D 目标检测和鸟瞰(BEV)检测。 在 3D 目标检测评价中,3D 相交比 (3D intersection over Union, 3D IoU) 作为检测阈值,预测的边界框(predicted bounding box)与真实边界框(real bounding box)相交比大于阈值,则认为检测正确。 它是通过将 3D 边界框投影到地面上进行评估等来计算的。
KITTI数据集使用
A
P
R
40
APR_{40}
APR40 到2019年8月10日,3D目标检测的评价标准从
A
P
R
11
APR_{11}
APR11 调整至
A
P
R
40
APR_{40}
APR40。
KITTI数据集还根据目标的识别程度将其分为三种困难:容易、中等和难。
对于目标方位预测(For object orientation prediction),KITTI使用了一种新的评估度量,平均方向相似性 AOS (Average Orientation Similarity): A O S = 1 11 ∑ r ∈ 0 , 0.1 , . . . , 1 max r ˜ : r ˜ ≥ r s ( r ˜ ) (2) \tag 2 AOS=\frac{1}{11}\sum_{r\in0,0.1,...,1}{\max_{\~r:\~r\geq r}s(\~r)} AOS=111r∈0,0.1,...,1∑r˜:r˜≥rmaxs(r˜)(2)其中 r r r 表示 PASCAL 目标检测中的召回; s s s 表示方向相似度,取值范围为 [ 0 , 1 ] [0,1] [0,1]; s ( r ) s(r) s(r)是余弦相似度的一个变体,定义为: s ( r ) = 1 ∣ D ( r ) ∣ ∑ i ∈ D ( r ) 1 + cos Δ θ ( i ) 2 δ i (3) \tag 3 s(r)=\frac{1}{|D(r)|}\sum_{i \in {D(r)}}\frac{1+\cos \Delta_\theta^{(i)}}{2}\delta_i s(r)=∣D(r)∣1i∈D(r)∑21+cosΔθ(i)δi(3) 其中 D ( r ) D(r) D(r) 表示在召回率 r r r 下所有目标检测结果的集合。 Δ θ ( i ) \Delta_\theta^{(i)} Δθ(i) 是探测对象 i i i 的预测方向和真实方向之间的角度差。
召回率(Recall):也称为查全率,表示真正为正类别的样本中被正确分类为正类别的比例。计算公式为:Recall = TP / (TP + FN),其中TP是真正例,FN是假反例(模型错误预测为负类别的样本数)。
nuScenes
Dataset:是 NuTonomy 于2019年构建的自动驾驶大型数据集。nuScenes 提供了一些优秀的基准,如 3D 目标检测和 3D 跟踪,并提出了相应的在线基准,用于测试和比较众多作品的性能。 为了使数据多样化,Nuscenes在波士顿和新加坡进行了收集,这两个城市以复杂的交通环境和挑战性的驾驶条件而闻名。 在这两个城市中,收集了 1000 个完整的场景,每个场景约 20 秒,包含晴天、雨天和黑夜等复杂场景。 nuScenes 总共包括大约 140 万个相机图像、39 万个激光雷达扫描、130 万个毫米波雷达扫描和 140 万个 3D 物体标注。 与其他数据集相比,它的所有传感器都提供了360度的视图。 具体来说,Nuscenes有六个摄像头,五个雷达和一个激光雷达。 这些多角度摄像机和雷达允许 nuScenes 从不同角度获得视图,从而形成一个像样的360度场景。


评估:nuScenes 数据集利用 nuScenes 检测得分(NDS,nuScenes Detection Score)作为评估分析的度量: N D S = 1 10 [ 5 m A P + ∑ m T P ∈ T P ( 1 − min ( 1 , m Y P ) ) ] (4) \tag 4 NDS=\frac{1}{10}[5mAP+\sum_{mTP\in TP}(1-\min(1,mYP))] NDS=101[5mAP+mTP∈TP∑(1−min(1,mYP))](4)其中,MAP表示均值平均精度; MTP(True Positive metrics)由5个度量组成: (1)平均翻译误差 Average Translation Error (ATE); (2)平均标度误差 Average Scale Error (ASE); (3)平均方位误差 Average Orientation Error (AOE); (4)平均速度误差 Average Velocity Error (AVE); (5)平均属性误差 Average Attribute Error, (AAE)。mTP 是每个类的平均 mTP 是每个类的平均mTP: m T P = 1 ∣ C ∣ ∑ c ∈ C T P c (5) \tag 5 mTP=\frac{1}{|C|}\sum_{c\in C}TP_c mTP=∣C∣1c∈C∑TPc(5)其中 C C C 是目标类别的集合。总之,NDS是一个组合度量,它结合了预测对象的位置、大小、方向和速度的属性。 在NDS中,一半的权重来自于检测性能,另一半是对预测帧的位置、大小、方向、速度和属性的质量评估。 由于 mAVE、mAOE 和 mATE 的值将大于1,所以每个值都约束在区间 [ 0 , 1 [0,1 [0,1]内。
Waymo
Dataset:是2020年发布的大规模自动驾驶数据集,现在是最大、最多样化的多模态数据集。Waymo提供了几个 3D 感知基准,如 3D 对象检测和 3D 语义分割。它收集多个城市的数据,如旧金山、凤凰城等。这些城市有很大的地理覆盖范围,包括各种驾驶条件下的不同场景,如白天、夜晚、黎明、黄昏和下雨。 具体来说,整个数据集由1150个场景组成,每个场景大约20秒,总共有23万帧数据,其中大约1200万个对象是人工标记的。 Waymo 使用10 Hz 的频率同时获取多个传感器。 具体来说,采集设备包括五个高分辨率摄像机和五个高质量激光雷达传感器。

评估:
Waymo数据集采用航向加权平均精度(Average Precision weighted byHeading,APH)作为模型的主要评价指标。该度量是在AP的基础上改进的 :
A
P
=
100
∫
0
1
max
p
(
r
′
)
∣
r
′
>
=
r
d
r
(6)
\tag 6 AP=100\int_0^1 \max p(r^{'})|r^{'} >= rdr
AP=100∫01maxp(r′)∣r′>=rdr(6)
A
P
H
=
100
∫
0
1
max
h
(
r
′
)
∣
r
′
>
=
r
d
r
(7)
\tag 7 APH=100\int_0^1 \max h(r^{'})|r^{'} >= rdr
APH=100∫01maxh(r′)∣r′>=rdr(7)其中
h
(
r
′
)
h(r^{'})
h(r′) 的计算类似于P/R曲线,
p
(
r
)
p(r)
p(r) 是P/R曲线;
h
(
r
)
h(r)
h(r) 的计算类似于
p
(
r
)
p(r)
p(r)。其中使用的 TP(True Positives)是由方向(Heading)加权的值,
r
r
r 表示回召函数, 它使用 21 个等间距的回召间隔
r
∈
[
0
,
1
/
20
,
2
/
20
,
.
.
.
,
1
]
r∈[0,1/20,2/20,...,1]
r∈[0,1/20,2/20,...,1]。
多模态表示
由于在多模态环境中,不同的传感器可以感知三维环境,因此数据表示成为融合不同传感器信息的关键设计选择。
在多模态学习中,数据表示是决定建模任务输入最关键阶段的重要部分。
用的多模态 3D 目标检测表示:
图像:
a.原始图像 Raw Image 2D
b.虚拟点云(伪点云)Pseudo-Point 3D
c.鸟瞰图特征 BEV Feature 2D
点云:
d.原始点云 Raw Point 3D
e.前视图 Front View 2D
f.范围视图 Range View 2D
g.BEV地图 BEV Map 2D
h.体素 Voxel 3D

统一表示
统一表示旨在以重合的格式处理异构数据(或特征),以缩小 heterogeneous gap。 根据表示方法的类型,可将其分为三大类:hybrid-based, 3D-based, and BEV-based。
统一表示将多模态数据(或特征)投射到一个统一的格式(或空间)中,并解决表示或格式的不对齐问题。
Hybrid-based
Hybrid-based 旨在将异构信息以一种相同的格式组合在一起,例如,通过将三维点云转换为二维表示(与图像相同)。基于混合的方法从两个方面来解决多模态检测问题:设计新的能够处理异质性的表示形式和选择合适的学习视点。
MV3D 为前视图(类似于范围视图)和Brid-eye视图提出了一种编码方法,其中包含高度、密度和强度。
X. Chen, H. Ma, J. Wan, B. Li, and T. Xia, “Multi-view 3d object detection network for autonomous driving,” in Proceedings ofthe IEEE conference on Computer Vision and Pattern Recognition, 2017, pp. 1907–1915.
MV3D 感知融合框架:
Stereoscopic-based
基于立体的方法的目标是通过将2D表示转化为3D来融合三维空间中的异构表示。、
SFD 将图像从二维空间转换成一个同时包含几何和纹理信息的伪点云。 由于生成伪点云的这种方式需要每个像素的深度信息,基于立体的方法总是利用深度估计模型,例如深度补全。SFD 提出了一种结合原始体素和伪点特征的基本 pipeline,消除了原始数据表示之间的异构鸿沟。
X. Wu, L. Peng, H. Yang, L. Xie, C. Huang, C. Deng, H. Liu, and D. Cai, “Sparse fuse dense: Towards high quality 3d detection with depth completion,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 5418–5427.
BEV-based
在三维感知中,BEV表示具有很强的解释性,有利于扩展传感器的模态和开发下游任务。BEV表示可以解决自动驾驶场景中存在的具有挑战性的问题,如车辆遮挡、稀疏表示等。 对于点云,改变视点很容易。 相比之下,改变摄像机的视点需要费力的参数和转换决策。
原始表示
统一的多模态表示的另一种选择是原始表示,其目的是不采取额外表示、再现、翻译或编码,以保存最大限度的可用信息。
原始表示不对原始表示进行变换,以保留最大的原始信息。
Pointpainting 用来自语义分割任务的语义得分装饰原始点云。
S. Vora, A. H. Lang, B. Helou, and O. Beijbom, “Pointpainting: Sequential fusion for 3d object detection,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 4604–4612.
F-PointNet 使用2D原始表示和2D目标检测,以缩小3D表示的范围,从而得到准确的预测前景信息。
C. R. Qi, W. Liu, C. Wu, H. Su, and L. J. Guibas, “Frustum pointnets for 3d object detection from rgb-d data,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 918– 927.
虽然这些方法可以减少特征之间的差距,但它们并没有在特征级别充分利用来自异构数据的原始信息。
PointFusion 利用 Vanilla Backbones、PointNet 用于 3D 和 ResNet 用于 2D,直接从原始表示中提取特征。
Maff-net 提出了一种基于柱的编码方法,将原始表示转换为柱表示并处理柱特征。
Z. Zhang, Y. Shen, H. Li, X. Zhao, M. Yang, W. Tan, S. Pu, and H. Mao, “Maff-net: Filter false positive for 3d vehicle detection with multi-modal adaptive feature fusion,” in 2022 IEEE 25th International Conference on Intelligent Transportation Systems (ITSC). IEEE, 2022, pp. 369–376.
对图像分支中的原始图像使用2D检测,这实现了用于ROI池(感兴趣区域池)的2D和3D检测:
M. Zhu, C. Ma, P. Ji, and X. Yang, “Cross-modality 3d object detection,” in Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, 2021, pp. 3772–3781.
Epnet、Epnet++ 提出使用 encoder-decoder 结构来增强异构表示的交互和融合。 由于原始二维表示的优越性,允许更多的二维辅助任务的变体。
T. Huang, Z. Liu, X. Chen, and X. Bai, “Epnet: Enhancing point features with image semantics for 3d object detection,” in European Conference on Computer Vision. Springer, 2020, pp. 35–52.
Z. Liu, B. Li, X. Chen, X. Wang, X. Bai et al., “Epnet++: Cascade bidirectional fusion for multi-modal 3d object detection,” arXiv preprint arXiv:2112.11088, 2021.
在多模态方法中,基于特征的融合越来越普遍,原始表示可以保留原始传感器的更多信息,更适合于多模态推理。
两种表示方式对比

多模态对齐
多模态融合的输入数据具有不同形式的特征表示,通常是异构的。 因此,要构建数据与不同模态之间的对应关系。将这一步骤概括为对齐,因为如果直接使用来自不同模态的未对齐特征,很可能会降低多模态数据的增益,甚至适得其反。 因此,必须考虑特征对齐来构造不同模态数据之间的对应关系。
多模态特征对齐是指构建不同模态数据特征之间的对应关系。
激光雷达与摄像机之间的对应关系由投影矩阵构成,投影矩阵由内参数和外参数组成,将三维世界坐标空间转换为二维图像坐标。
利用标定矩阵寻找三维与二维的对应关系,实现特征对齐,是有效的,但破坏了图像的语义信息。
为了更好地解决这一问题,因此采用深度学习技术来实现特征对齐。
特征对齐方法分为两类:1)Projection-based 2)Model-based

基于投影的特征对齐
基于投影的方法大致可分为全局投影和局部投影。
全局投影: 使用整个图像作为点云的搜索区域。
局部投影: 点云的搜索区域仅为图像中用边界框标记的范围。
这两种方法的本质区别在于是否通过二维边界框缩小点云的范围。
利用摄像机投影矩阵对图像和点云进行对齐是有效的。 虽然特征的聚合是在精细像素级进行的,但点云是稀疏的,而图像是稠密的。 利用投影矩阵求出激光雷达点与图像像素的对应关系。 点云特征通过这种硬关联以粗粒度的方式聚合图像信息,会破坏图像中的语义信息。
通过软关联机制,利用交叉注意力机制来寻找激光雷达点和图像像素之间的对应关系。 它可以动态聚焦于来自图像的像素级信息。 每个点云的特征对整个图像进行查询,使得点云特征能够以细粒度的方式聚合图像信息,得到像素级的语义对齐图。 该方法虽然能更好地获取图像中的语义信息,但由于使用了注意力机制,图像中的每个像素都会进行匹配,模型计算量大,耗时较多。
全局投影
全局投影是指以实例分割网络处理后的图像特征或将图像转换成一个BEV作为输入,将点云投影到处理后的图像上,并输入到3D backbone 中进行进一步处理。
PointPainting 和 PI-RCNN 将图像分支中的图像特征和原始激光雷达点云中的语义特征进行融合,利用基于图像的语义分割增强点云。 将图像通过分割网络获得像素级语义标签,然后通过点-像素投影将语义标签附着到3D点上。
S. Vora, A. H. Lang, B. Helou, and O. Beijbom, “Pointpainting: Sequential fusion for 3d object detection,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 4604–4612.
L. Xie, C. Xiang, Z. Yu, G. Xu, Z. Yang, D. Cai, and X. He, “Pi-rcnn: An efficient multi-sensor 3d object detector with point-based attentive cont-conv fusion module,” in Proceedings of the AAAI conference on artificial intelligence, vol. 34, no. 07, 2020, pp. 12 460–12 467.
MVP 借鉴了 PointPainting 的思想,首先使用图像实例分割,通过投影矩阵建立实例分割掩码与点云的对齐关系,但不同的是MVP 随机采样每个范围内的像素,与点云一致;点投影上的像素采用最近邻连接,连接上激光点的深度作为当前像素的深度。这些点然后被投影回激光坐标系以获得虚拟激光雷达点。
T. Yin, X. Zhou, and P. Kr¨ahenb¨uhl, “Multimodal virtual point 3d detection,” Advances in Neural Information Processing Systems, vol. 34, pp. 16 494–16 507, 2021.
MVXNet 不使用PointNet 网络提取点云特征而是将原始激光雷达点云预处理为体素,以进一步使用更先进的单模三维物体检测的 backbone,并通过附着在体素上的投影方法传递相应像素的图像特征向量。MVXNet 将ROI图像特征向量附加到激光雷达点云中每个体素的密集特征向量上。
V. A. Sindagi, Y. Zhou, and O. Tuzel, “Mvx-net: Multimodal voxelnet for 3d object detection,” in 2019 International Conference on Robotics and Automation (ICRA). IEEE, 2019, pp. 7276–7282.
ContFuse、BevFusion 和 3D-CVF 三种方法统一表达了这两种模态的数据。 通过投影将图像特征转化为BEV表示,并与点云BEV表示对齐。
Contfuse:通过 MLP learning 将图像特征投影到 BEV 空间。 首先在图像中找到每个像素的k个邻域点,然后将投影矩阵传递到三维空间,然后投影到图像中。特征和对象像素的坐标偏移被输入到MLP中。 得到了目标点的图像特征。 然后与BEV特征映射融合形成稠密特征映射。
M. Liang, B. Yang, S. Wang, and R. Urtasun, “Deep continuous fusion for multi-sensor 3d object detection,” in Proceedings of the European conference on computer vision (ECCV), 2018, pp. 641–656.
BEVFusion 通过将摄像机图像转换为3D ego-汽车坐标并使用BEV编码器模块,将3D ego-汽车坐标转换为BEV表示。
T. Liang, H. Xie, K. Yu, Z. Xia, Z. Lin, Y. Wang, T. Tang, B. Wang, and Z. Tang, “Bevfusion: A simple and robust lidar-camera fusion framework,” arXiv preprint arXiv:2205.13790, 2022.
3D-CVF 通过自标定投影将 2D 相机特征转换成与 BEV 中雷达特征最大对应的平滑空间特征图。 此特征图也属于BEV。
J. H. Yoo, Y. Kim, J. Kim, and J. W. Choi, “3d-cvf: Generating joint camera and lidar features using cross-view spatial feature fusion for 3d object detection,” in European Conference on Computer Vision. Springer, 2020, pp. 720–736.
局部投影
局部投影利用二维检测从图像中提取信息,缩小三维点云中的目标候选区域,将图像信息传递到点云中,最后将增强后的点云输入到基于激光雷达的 3D 目标检测器中。
Frustum-PointNet 提出了一个具有预测的前向和后向截断径向距离的锥面,将 2D box 扩展到 3D box 。
首先,图像通过 2D 目标检测器以生成感兴趣目标周围的 2D box。 然后,使用校准矩阵将 2D box 内的对象投影到 3D frustum 中。 将 3D frustum 中的信息应用于激光雷达点云,实现图像与点云的对齐 。
C. R. Qi, W. Liu, C. Wu, H. Su, and L. J. Guibas, “Frustum pointnets for 3d object detection from rgb-d data,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 918– 927.
MV3D通过投影将激光雷达点云转换为BEV和前视图(FV),生成 proposals,然后融合BEV、FV和图像特征来预测最终的3D边界框。 在此过程中,利用三维 proposals 网络生成高精度的三维候选框,并将三维 proposals 投影到多个视图中的特征映射中,实现两种模式之间的特征对齐。 AVOD 也采用了相同的思想,但与 MV3D 不同,AVOD 删除了 FV 并提出了一个更精细的区域方案。
X. Chen, H. Ma, J. Wan, B. Li, and T. Xia, “Multi-view 3d object detection network for autonomous driving,” in Proceedings ofthe IEEE conference on Computer Vision and Pattern Recognition, 2017, pp. 1907–1915.
J. Ku, M. Mozifian, J. Lee, A. Harakeh, and S. L. Waslander, “Joint 3d proposal generation and object detection from view aggregation,” in 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS). IEEE, 2018, pp. 1–8.
AVOD 神经网络结构图
Pointaugmenting 不使用从图像实例分割网络获得的特征,而是使用目标检测网络的特征映射。
C. Wang, C. Ma, M. Zhu, and X. Yang, “Pointaugmenting: Crossmodal augmentation for 3d object detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2021, pp. 11 794–11 803.
SFD 提出了一种利用伪点云的方法,点云分支对原始点云进行处理,生成ROI区域。 利用投影矩阵将点云投影到图像上,生成带颜色的伪点云,实现两个数据的特征对齐。 最后,通过生成的ROI缩小点云的搜索范围。
基于模型的特征对齐
多模态 3D 目标检测方法提出了通过一种主要利用 attention 的学习方法对图像和点云进行对齐。
Autoalign 和 DeepFusion 都采用交叉注意力机制来实现两种模态的特征对齐。 它们将体素分别转换为查询Q和相机特征、键值K和值V。对于每个查询(即体素单元),执行查询与键值之间的内积,以获得包含体素与其所有相应相机特征之间相关性的矩阵。 采用Softmax算子对其进行归一化,然后用包含摄像机信息的V值对其进行聚合和加权。
Z. Chen, Z. Li, S. Zhang, L. Fang, Q. Jiang, F. Zhao, B. Zhou, and H. Zhao, “Autoalign: Pixel-instance feature aggregation for multimodal 3d object detection,” arXiv preprint arXiv:2201.06493, 2022.
Y. Li, A. W. Yu, T. Meng, B. Caine, J. Ngiam, D. Peng, J. Shen, Y. Lu, D. Zhou, Q. V. Le et al., “Deepfusion: Lidar-camera deep fusion for multi-modal 3d object detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 17 182–17 191.
AutoAlignV2 提出了一种跨域的 DEformCAFA 操作。 DeformCAFA使用一种可变形的交叉注意力机制,其中查询q和键值k仍然采用自动对齐中的设置。 值V有了新的变化。 首先,利用投影矩阵查询对应于体素特征的图像特征。 然后,通过MLP学习偏移量,提取与偏移量相对应的图像特征作为值V。交叉注意力使每个体素都能感知整个图像,从而实现两种模式的特征对齐。
Transfusion 中使用了 Transformer decoder。 第一 decoder 层利用稀疏的对象查询集从激光雷达特征生成初始包围盒。 第二decoder 自适应地融合对象查询和与空间和上下文关系相关的有用图像特征。
Z. Chen, Z. Li, S. Zhang, L. Fang, Q. Jiang, and F. Zhao, “Autoalignv2: Deformable feature aggregation for dynamic multi-modal 3d object detection,” arXiv preprint arXiv:2207.10316, 2022.
X. Bai, Z. Hu, X. Zhu, Q. Huang, Y. Chen, H. Fu, and C.-L. Tai, “Transfusion: Robust lidar-camera fusion for 3d object detection with transformers,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 1090–1099.
多模态融合
目前,多模态 3D 目标检测中最主要的融合方法是互补,即一种模态对另一种模态的增强。多模态方法主要是图像特征对点云特征的特征互补。在 3D 目标检测领域,点云的检测精度远高于图像。图像中深度信息的缺乏导致了 3D 目标检测的精度不高,但同时,图像信息具有丰富的语义信息,可以作为点云信息的数据补充。
目前的多模态互补方法是通过不同的融合方法来实现的。 主要区别在于多模态 3D 目标检测融合过程中是否需要学习:learning-agnostic 和 learning-based.learning-agnostic 对特征进行算术运算和拼接运算。 这些方法操作简单,易于计算,但不具有良好的可扩展性和鲁棒性。learning-based 利用对融合特征的关注,这相对复杂,并增加了参数的数量。 但可以关注权重较高的重要信息,忽略权重较低的无关信息,因此具有较高的可扩展性和鲁棒性。
Learning-Agnostic 融合
Learning-Agnostic 融合有两种主要类型:元素操作(求和、均值)和级联。
元素操作
元素操作利用算术操作来处理相同维度(求和、均值)的特征。 元素操作易于并行操作。 它将两个特征组合成一个复合向量。 具有计算简单、易于操作的优点 。同时,计算不同通道的均值或求和增加了点云特征的信息量,但特征维数并没有增加。 只是每个维度下的信息量增加。信息量的增加可以提高检测精度。
AVOD 以 MV3D 为基准(均值法融合不同视角的特征),通过元素均值从两个视图的特征映射中生成新的融合特征。 它继承了MV3D融合时计算量小的优点。 这样可以有效地融合相同形状的特征映射。
ContFuse 通过传感器坐标对应来关联特征,并使用元素求和来组合相同维度的元素映射以融合不同的模态信息。
M. Liang, B. Yang, S. Wang, and R. Urtasun, “Deep continuous fusion for multi-sensor 3d object detection,” in Proceedings of the European conference on computer vision (ECCV), 2018, pp. 641–656.
Focals Conv 提出了一种轻量级融合模块,该模块使用语义分割网络提取图像特征,并利用元素求和来聚合图像特征和体素特征。
Y. Chen, Y. Li, X. Zhang, J. Sun, and J. Jia, “Focal sparse convolutional networks for 3d object detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 5428–5437.
元素化不能准确地获得正确的前景信息,并且通常带有噪声。
级联操作
特征级联是将变换后的多模态特征转换成相同大小的特征向量,然后将图像特征向量与点云特征向量级联起来。
与元素操作不同,级联操作是通道数的合并,它比元素操作的计算强度更大。 但它避免了直接按元素操作所造成的信息损失。 同时,级联操作不受通道数目的限制。
PointFusion 是将级联操作应用于多模态 3D 目标检测的先驱。 将逐点特征和图像特征连接起来,以最大限度地保留每个模态的信息。
D. Xu, D. Anguelov, and A. Jain, “Pointfusion: Deep sensor fusion for 3d bounding box estimation,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 244–253.
VoxelNet 将单模态输入扩展到多模态输入,进一步提高了性能。
Y. Zhou and O. Tuzel, “Voxelnet: End-to-end learning for point cloud based 3d object detection,” in Proceedings of the IEEE conference on computer vision and pattern recognition, 2018, pp. 4490–4499.
MVX-NET 和 SegvoxelNET 使用串联操作将相应的图像特征补充到 3D 点的坐标。 与元素操作不同,级联操作可以更大程度地保留模态信息,且信息损失较小。
V. A. Sindagi, Y. Zhou, and O. Tuzel, “Mvx-net: Multimodal voxelnet for 3d object detection,” in 2019 International Conference on Robotics and Automation (ICRA). IEEE, 2019, pp. 7276–7282.
“Seg-voxelnet for 3d vehicle detection from rgb and lidar data,” in 2019 International Conference on Robotics and Automation (ICRA). IEEE, 2019, pp. 4362–4368.
PointPainting 方法通过语义分割网络获得像素分割得分。该方法通过一个级联操作对分割后的分数进行融合来补全点云,以保留点云信息和分割后的分数。
S. Vora, A. H. Lang, B. Helou, and O. Beijbom, “Pointpainting: Sequential fusion for 3d object detection,” in Proceedings of the IEEE/CVF conference on computer vision and pattern recognition, 2020, pp. 4604–4612.
learning-based 融合
DETR使整个网络能够实现端到端的对象检测,显著简化了目标检测 pipeline。后来的 DETR3D 将注意力应用于 3D 目标检测。
Y. Wang, V. C. Guizilini, T. Zhang, Y. Wang, H. Zhao, and J. Solomon, “Detr3d: 3d object detection from multi-view images via 3d-to-2d queries,” in Conference on Robot Learning. PMLR, 2022, pp. 180– 191.
Y. Wang, T. Ye, L. Cao, W. Huang, F. Sun, F. He, and D. Tao, “Bridged transformer for vision and point cloud 3d object detection,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2022, pp. 12 114–12 123.
随着注意力的发展,跨模态注意力可以为多模态方法提供一种新的融合途径。 基于学习的方法学习权重分布,即输入数据或特征图的不同部分具有不同的权重。 根据权重的不同,高权重用于保留重要信息,低权重忽略无关信息。 基于学习的融合方法具有较好的鲁棒性。
将注意力应用于多模态 3D 目标检测,3D-CVF,MVAF-NET,MAFF-NET,EPNET。
3D-CVF 提出了一种自适应门控融合网络,极大地简化了 3×3 卷积层和 Sigmoid 函数。 注意力映射将投影图像特征补充到点云特征中。 这种类型的融合允许更好地聚焦有用的信息进行融合,使融合方法具有可学习性。
J. H. Yoo, Y. Kim, J. Kim, and J. W. Choi, “3d-cvf: Generating joint camera and lidar features using cross-view spatial feature fusion for 3d object detection,” in European Conference on Computer Vision. Springer, 2020, pp. 720–736.
MVAF-Net 中的 MVFF 部分提出与 APF 模块相结合,利用注意力机制自适应地融合多任务特征。
G. Wang, B. Tian, Y. Zhang, L. Chen, D. Cao, and J. Wu, “Multiview adaptive fusion network for 3d object detection,” arXiv preprint arXiv:2011.00652, 2020.
MAFF-NET 模型提出了 PointAttentionFusion(PAF) 模块。 PAF通过融合一个图像特征和两个注意力特征对每个三维点进行融合,实现自适应融合特征。
Z. Zhang, Y. Shen, H. Li, X. Zhao, M. Yang, W. Tan, S. Pu, and H. Mao, “Maff-net: Filter false positive for 3d vehicle detection with multi-modal adaptive feature fusion,” in 2022 IEEE 25th International Conference on Intelligent Transportation Systems (ITSC). IEEE, 2022, pp. 369–376.
由于摄像机传感器容易受到光照、遮挡等因素的影响,在对点云特征进行补充的过程中引入了干扰信息。 为解决这一问题, EPNET 采用 attention 方法自适应地估计图像的重要性以进行融合。
T. Huang, Z. Liu, X. Chen, and X. Bai, “Epnet: Enhancing point features with image semantics for 3d object detection,” in European Conference on Computer Vision. Springer, 2020, pp. 35–52.
利用注意力融合可以融合高权重的关键信息和低权重的冗余信息。 这极大地提高了融合效率,并防止了干扰信息影响检测效率。
多模态融合仍面临以下挑战:
1.数据信息在特征变换中存在不同程度的信息丢失。
2.目前的融合方法都是用图像特征来补充点特征,而图像特征在使用点云基线时会出现域间隙等问题。
3.Learning-Agnostic 需要根据信息的重要性考虑融合问题。
4.Learning-based 方法参数多,需要考虑参数数优化问题。
挑战和趋势
1. 数据噪声
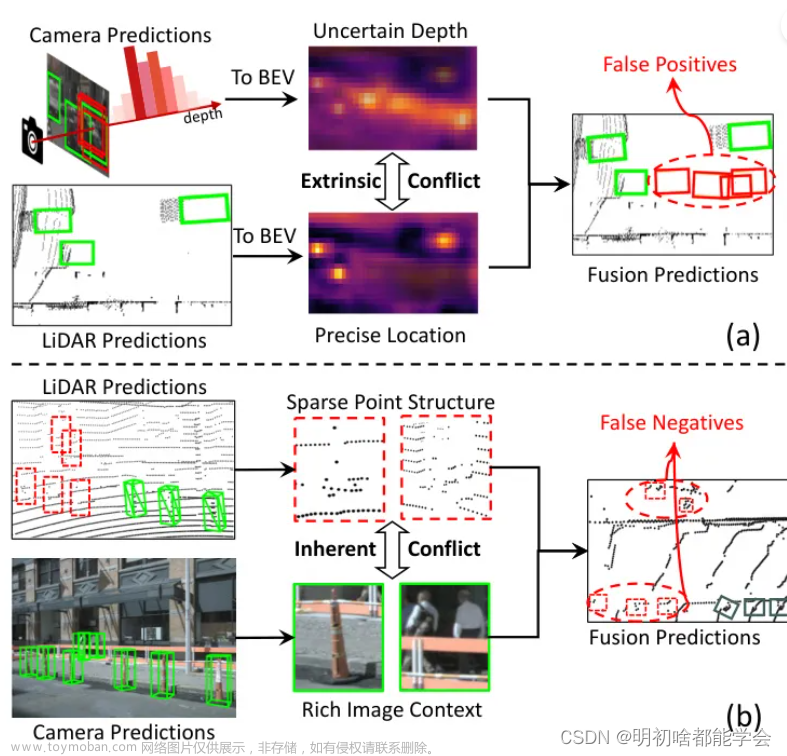
由于传感器种类繁多,来自不同模态的数据之间存在 information gap,导致信息不同步。该问题在特征融合中引入了显著的噪声,从而损害了信息表示学习。
例如,two-stage 检测器在融合过程中,由于不同维度的 ROI 区域的存在,导致背景特征在图像中的融合。 利用BEV表示来统一不同的异构模态,为解决这一问题提供了一个新的视角。
2.开源数据集的 Limited Reception Field
传感器覆盖 coverage 不足不利于多模态检测的性能。
Nuscenes 具有良好的感知范围(点云和摄像机都可以360度)和 Waymo 提高多模态检测系统的复盖率,增强其在复杂环境下的性能,为解决开源数据集中接收域有限的问题提供了一种可能的思路。
3.紧凑表示
紧凑表示以较少的数据规模包含更多的信息。 现有的工作将稀疏的三维表示编码为二维表示,但在编码过程中存在大量的信息损失。 一幅 range image 的投影会导致多个点落在同一像素中,从而导致信息丢失。
4.信息丢失
如何最大限度地保留多模态信息一直是多模态 3D 目标检测的关键问题之一 。例如,在融合阶段,当图像与点云特征互补时,图像语义信息丢失。这就导致融合过程不能更好地利用图像的特征信息,导致模型性能次优。
4.未标注数据
无标注数据在自动驾驶场景中普遍存在,无监督学习可以提供更鲁棒的表征学习,这在类似任务中得到了一定程度的研究,比如2D 目标检测。然而,在当前的多模态三维目标检测中,对无监督表示还没有 convincing 的研究。 在多模态研究领域,如何更好地进行多模态表征的无监督学习是一个具有挑战性的研究课题。
5.计算复杂度高
多模态三维物体检测的一个重要挑战是在自动驾驶场景下快速、实时地检测出物体。 由于多模态方法需要处理多种信息,导致参数和计算量增加,训练时间长,推理时间长,不能满足应用的实时性。
最近的多模态方法也考虑实时性,例如 MVP,BEVFusion 在 Nuscenes 数据集上的实验使用 FPS 作为模型评估度量 。
未来的工作将鼓励探索模型剪枝和量化技术,旨在简化模型结构,减少模型参数,以实现高效的模型部署。
6.Long Tail Effect
自动驾驶场景有很多品类。 在检测汽车方面有效的模型在检测行人方面可能是无效的,这导致类别检测不均匀。 在今后的工作中,可能会探索使用损失函数和抽样策略作为解决上述问题的潜在解决方案。
7.跨模态数据增强
数据增强是实现三维目标检测的关键环节,但数据增强大多应用于单模态方法,在多模态场景中很少考虑。由于点云和图像是两种异构数据,很难实现跨模态同步增强,会导致严重的跨模态失调。
8.时间同步
时间同步是多模态 3D 目标检测中的一个关键问题。由于不同传感器的采样率、工作方式、采集速度等方面的差异,传感器采集的数据之间存在时间偏差,导致多模态数据不对齐,进而影响多模态三维物体检测的精度和效率。 首先,不同传感器的时间戳可能存在误差。 即使采用硬件进行定时同步,也很难完全保证传感器时间戳的一致性。 其次,传感器数据存在丢帧或延迟,也影响了多模态 3D 目标检测的精度。文章来源:https://www.toymoban.com/news/detail-776719.html
主要参考文献
1.Multi-modal 3D Object Detection in Autonomous Driving: A Survey and Taxonomy
2.李熙莹,叶芝桧,韦世奎等.基于图像的自动驾驶3D目标检测综述——基准、制约因素和误差分析[J].中国图象图形学报,2023,28(06):1709-1740.文章来源地址https://www.toymoban.com/news/detail-776719.html
到了这里,关于综述:自动驾驶中的多模态 3D 目标检测的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!