title:Graph date:2023-12-07 21:24:49 tags:Computer science
图
图(Graph)是一种包含节点与节点的边的集合,记作G=(V,E),V是节点的集合,E是边的集合。
图的基本概念
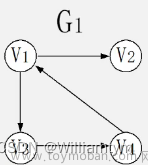
有向图
一个有向图G=(V,E),E中每个元素是V上的一个二值关系:一条从a出发的连向b的边e可以记作一个有序对e = (a,b)。
无向图
一个无向图G=(V,E),E的每个元素e可以表示V上的一个无序对,记作**{a,b}**。

度(degree)
节点的度(degree)指该节点连接的边的条数。对于有向图,节点有出度(outdegree)和入度(indgree),出度表示连向,入度表示被连向。
简单图
简单图指没有多重边和自环的图。
如果G是一个无向图,那么:
∑
v
∈
V
d
e
g
r
e
e
(
v
)
=
2
∣
E
∣
\sum_{v\in V}degree(v) = 2|E|
v∈V∑degree(v)=2∣E∣
如果G是一个有向图,那么:
∑
v
∈
V
i
n
d
e
g
r
e
e
(
v
)
=
∑
v
∈
V
o
u
t
d
e
g
r
e
e
(
v
)
=
∣
E
∣
\sum _{v \in V}indegree(v) = \sum _{v\in V}outdegree(v) = |E|
v∈V∑indegree(v)=v∈V∑outdegree(v)=∣E∣
加权图
加权图指每个边都有一个权值的图。
加权函数:w:E->R

路径(path)
一条路径包含若干个节点,节点之间都有一条边相连,如果路径包含的节点没有重复,则称这条路径为简单路径,如果路径的起点和终点是同一个节点,那么称之为环(circle),包含环的图称为有环图,反之为无环图。
连通性
-
对于一个无向图,如果任意两个节点之间都存在一条路径连接,则称这个无向图为连通图。
-
对于一个有向图,如果任意两个节点之间都存在一条有向路径连接,则这个有向图为强连通图。
-
对于一个图G(E,V),如果
∣ E ∣ ≈ ∣ V ∣ |E| \approx |V| ∣E∣≈∣V∣
则称之为稀疏图。
- 对于一个图G(E,V),如果
∣ E ∣ ≈ ∣ V ∣ 2 |E| \approx |V|^2 ∣E∣≈∣V∣2
则称之为稠密图。
无向完全无环图有:
∣
E
∣
=
∣
V
∣
∗
(
∣
V
∣
−
1
)
2
|E| = \frac{|V|*(|V|-1)}{2}
∣E∣=2∣V∣∗(∣V∣−1)
有向完全无环图有:
∣
E
∣
=
∣
V
∣
∗
(
∣
V
∣
−
1
)
|E| = {|V|*(|V|-1)}
∣E∣=∣V∣∗(∣V∣−1)
连通分支
连通分支为一个图中最大的连通子图。

完全图
对于一个图,如果任意两个节点都有边邻接(有向图中需要两个方向的边),则称之为完全图。如果(u,v)是G的一条边,则称节点u和节点v邻接。
二分图
对于一个无向图G(V,E),V可以划分成两个集合V1,V2,对于任意边e(u,v),都有:
u
∈
V
1
且
v
∈
V
2
u\in V_1且v\in V_2
u∈V1且v∈V2
树(Tree)
- 一个自由树是一个无环连通的无向图。
- 一个森林是一个无环无向图。
- 一个有根树是指树中有一个节点被设置为根节点。
树具有以下性质:
- 无环连通;
- 任意两个节点都有唯一的连通路径连通;
- 删除一条边之后G不再连通;
- 增加一条边后G变为有环;
- |E| = |V| - 1;
邻接表

优点:找出一个节点的邻接节点效率高;
缺点:找出一条边是否存在效率低。
邻接矩阵


优点:快速找到一条边是否存在。
图遍历
与图遍历有关的问题
- G是否连通
- G是否包含一个环
- G是否是一个树
- G的一个连通分支
- 拓扑排序
- 有向图G是否有强连通性
图的遍历的方法
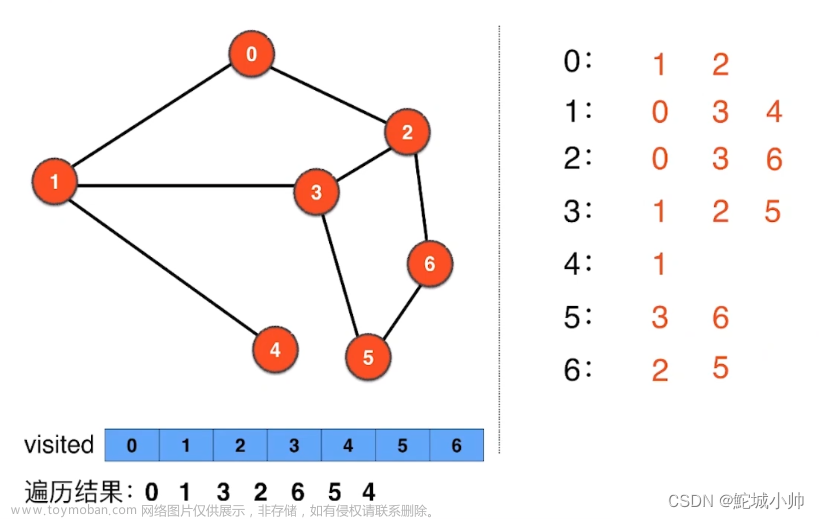
广度优先搜索(BFS)
关键字:队列,颜色表示访问状态,逐层访问
BFS(G,s)
- 初始化所有节点为white;
- 初始化当前访问节点s到各个节点的距离为无穷大;
- 设置s为gray,表示s已访问但s的邻接节点未访问;
- 设置s到s距离为0;
- 设置s的前驱节点为NIL;
- 将s加入队列;
以上是初始化
- 队列不为空重复操作:
-
- 剔除队尾元素u;
- 遍历与u邻接的所有结点;
-
- 如果该节点v为white:
-
- 则将v变为gray;
- 设置s到v的距离 = u到s距离 + 1(未加权);
- 设置u为v的前驱节点;
- 使v加入队列;
- 设置u为black,表示u和u的所有邻接结点已经全部访问;
BFS的输出:
- s到其他所有结点的最短路径;
- 一个以s为根节点的BFS树,包含了所有s的可达节点。
深度优先搜索(DFS)
关键字:栈,颜色表示状态
DFS(G)
- 初始化所有节点的颜色为white,前驱节点为NIL;
- 对所有为白色的节点进行DFS访问;
DFS-Visit(G,u)
- time++,记录开始时间time;
- 设置u颜色为gray表示u被访问但u的邻接节点未被访问;
- 遍历u的邻接结点,如果u的邻接节点为白色(未被访问),则设置u为v的前驱节点,并对v递归调用DFS-Visit;
- u的所有邻接节点被访问,设置u为black
- time++,记录结束时间
DFS的输出:
- 一系列DFS树:DFS森林;
- 第一次发现u的时间,完成对u搜索的时间(用来找到前向边,反向边)
强连通分支
DFS输出的DFS森林中的每一棵DFS都是一个强连通分支。
最小生成树问题(MST)
Prim算法
Prim算法提供的贪心策略是将图的节点分为在树中和不在树中两个集合,
按在树中的节点和未加入树中的节点的权值最小的边依次加入树的集合,直到所有节点被加入。
def Prim(G,COST):
T = []
mincost = 0
NEAR = [0]*n
mincost = COST[0][1]
T.append([0,1])
for i in range(n):
if COST[i][0] > COST[i][1]:
NEAR[i] = 1
else:
NEAR[i] = 0
for _ in range(2,n):
minedge = float('inf')
for i in range(1,n):
if NEAR[i] != 0 and COST[i][NEAR[i]] < minedge:
minedge = COST[i][NEAR[i]]
j = i
T.append([j,NEAR[j]])
mincost += minedge
NEAR[j] = 0
for k in range(n):
if NEAR[k] != 0 and COST[k][j] < COST[k][NEAR[k]]:
NEAR[k] = j
if mincost >= float('inf'):
print('no spanning tree')
else:
return T,mincost
# 示例用法
COST = [
[0, 2, 4, 0],
[2, 0, 1, 3],
[4, 1, 0, 0],
[0, 3, 0, 0]
]
n = 4
T, mincost = prim(COST, n)
print('最小生成树的边:', T)
print('最小生成树的总成本:', mincost)
Kruskal算法
Kruskal的贪心策略在于将所有边按权值的非降次序排序,依次取出边直到取到(节点数-1)条边为止,其中取的边不能构成环(circle),我们一般用并查集(Union-FInd Set)来判断是否构成环,也可以用DFS先搜索一遍图,利用进入DFS-VISIT的结束时间来判断是否是反向边来判断是否成环,这里利用并查集。文章来源:https://www.toymoban.com/news/detail-776766.html
def kruskal(E,cost,n,T.mincost):
parent = [-1]*n
T = []
mincost = 0
def find(u):
if u == -1:
return u;
else:
return find(parent[u])
def union(j,k):
parent[j] = k
edge = [];
for u in range(n):
for v in range(n):
if cost[u][v] != float('inf'):
edge.append(cost[u][v])
edge.sort();
for cost,u,v in edge:
if len(T) - 1 == n-1:
break
j = find(u)
k = find(v)
if j != k:
T.append(cost[u][v])
mincost += cost[u][v]
union(u,v)
if len(T) != n-1:
print('no spanning tree')
return T,mincost
f len(T) - 1 == n-1:
break
j = find(u)
k = find(v)
if j != k:
T.append(cost[u][v])
mincost += cost[u][v]
union(u,v)文章来源地址https://www.toymoban.com/news/detail-776766.html
if len(T) != n-1:
print('no spanning tree')
return T,mincost
将每个节点表示为一棵独立的树,设置为-1,如果两个节点的边不构成环,意味着两节点不在同一棵树中,并将两节点加入同一棵树中,这里规定前者成为后者的子树。在进行加入边的操作之前,我们需要判断两节点是否在同一棵树中。
到了这里,关于【算法导论】图论(图的基本概念,图上的深度优先搜索(DFS),广度优先搜索(BFS),最小生成树(MST)及Prim,Kruskal算法)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!

![【算法每日一练]-图论(保姆级教程 篇6(图上dp))#最大食物链 #游走](https://imgs.yssmx.com/Uploads/2024/02/769730-1.png)








