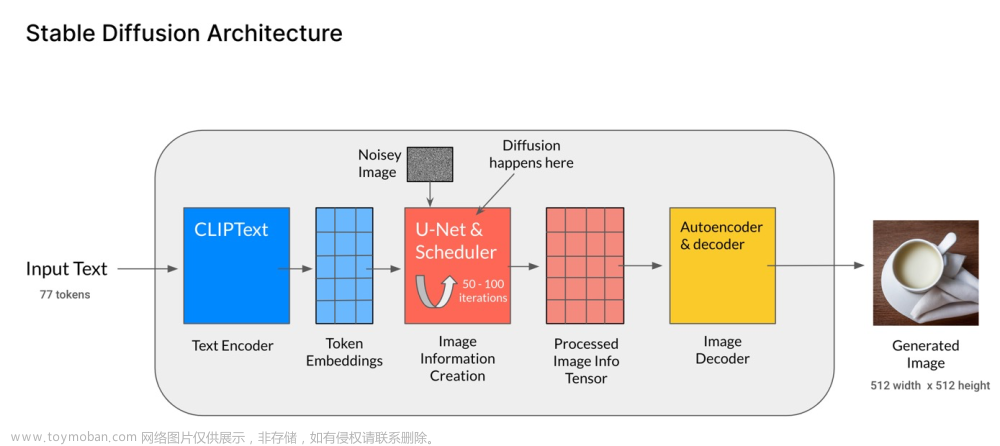
编者按:欢迎阅读“科研上新”栏目!“科研上新”汇聚了微软亚洲研究院最新的创新成果与科研动态。在这里,你可以快速浏览研究院的亮点资讯,保持对前沿领域的敏锐嗅觉,同时也能找到先进实用的开源工具。
本期“科研上新”将为大家带来多篇微软亚洲研究院在 NeurIPS 2023 上的精选论文解读,涉及领域涵盖文本属性图、语音编辑、分子建模、脑电信号处理、文档索引、扩散模型泛化、文本渲染等。
本期内容速览
01. 文本图上综合性研究:基准测试与深度思考
02. AUDIT:遵循人类自然语言指令的音频编辑模型
03. Geoformer:采用原子间相对几何位置编码的分子建模Transformer
04. 通过建模空间信息学习拓扑不变的脑电表征
05. 用生成式语言模型增强基于嵌入的文档索引
06. 关于扩散模型的泛化性质
07. TextDiffuser:让文本渲染不再成为扩散模型的难题
文本图上综合性研究:基准测试与深度思考

论文链接:https://openreview.net/pdf?id=m2mbfoSuJ1
项目链接:https://github.com/sktsherlock/TAG-Benchmark
在现实世界的图中,节点与文本属性是相互关联的,文本属性图则由此形成。其实,文本图普遍存在于各种场景,例如社交网络中每个用户都有相应的文本描述,引文网络中每篇论文也有其对应的文本内容。文本图上学习方法的探索已成为图学习、信息检索和自然语言处理等多个领域的重点研究方向。
微软亚洲研究院的研究员们发现传统文本图上的表示学习方法,如基于预训练语言模型和基于图神经网络的方法,无法很好地整合文本语义与图拓扑知识。后续的协同训练方法也存在着可扩展性较差的问题。基于这些观察,研究员们从预训练角度出发,设计了多种拓扑结构预训练任务来增强语言模型,并最终提出了一个基准测试,以全面地在多种数据上评估文本图上的各种学习方法。

图1:文本图数据集及相关表示学习方法概览
具体来说,研究员们调研并分析了现有的文本图数据集,发现其中大多都缺乏原始文本属性或尺寸较小。因此,研究员们首先为文本图领域设计并构造了多样且具有挑战的八个基准数据集。它们涉及引文网络、电商网络等领域,并拥有不同的文本属性构造方式,从而可以更全面地评测不同学习方法。
对于拓扑结构预训练任务,研究员们则从不同层次设计了三种预训练任务:一、从令牌级别捕捉低阶拓扑知识的方法 TMLM;二、以对比学习方式,从节点级别捕捉低阶拓扑知识的方法 TCL;三、以图嵌入学习算法增强捕捉高阶拓扑知识的方法 TDK。同时,研究员们也采取了结合以上三种预训练任务的多任务训练方式 TMDC。
最终,研究员们在基准测试中选取了九种主流图神经网络与五种不同规模的预训练语言模型,实现了三种传统文本图上学习方法的代码框架,以及拓扑增强语言模型的代码流程。实验表明,优质的文本属性建模可提高各种下游图神经网络的性能,而拓扑增强语言模型在各种数据集上均能提升模型性能,在一些数据集上甚至全面超过了图神经网络的性能。
AUDIT:遵循人类自然语言指令的音频编辑模型

论文链接:https://arxiv.org/abs/2304.00830
在电影和短视频中,音频编辑是一项至关重要的任务,也是一项耗时、耗力、成本较高的工作。音频编辑包括替换背景音乐、修复损坏的音频和添加音效等。近期,基于扩散模型的方法在音频生成任务方面取得了显著的进展。因此,微软亚洲研究院的研究员们就以扩散模型为基础,针对音频编辑的添加音效、删除音效、替换音效、修复音频和高保真音质等问题,开发了能够通过自然语言控制的音频编辑模型。
目前,一些基于深度扩散模型的方法通过采用以输出音频的文本描述为条件的扩散和去噪过程,来成功实现零样本音频编辑的。然而,这些方法仍然存在一些问题:1. 它们没有经过编辑任务的训练,无法保证良好的编辑效果;2. 它们可能会错误地修改不需要编辑的音频片段;3. 它们需要输出音频的完整描述,但在实际应用场景中,这并非始终可获得或必需的。
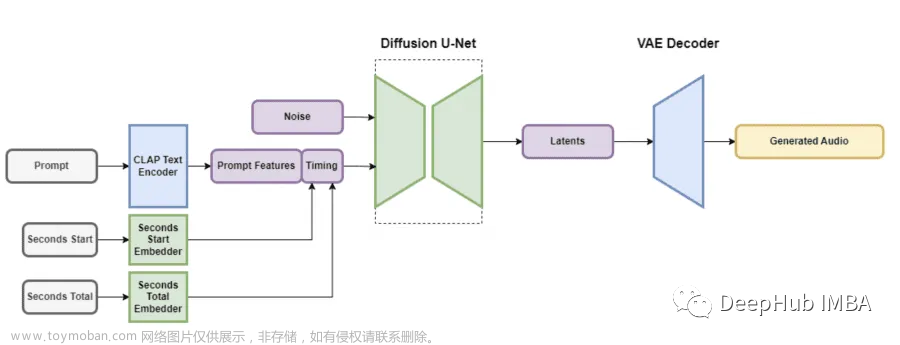
针对以上缺陷,研究员们推出了 AUDIT,一种基于潜在扩散模型的指令引导音频编辑模型。具体来说,AUDIT 具有三个主要的设计特点:1. 研究员们为不同的音频编辑任务构建了三元组训练数据(指令、输入音频、输出音频),并使用指令和输入(待编辑)音频作为条件训练扩散模型并生成输出 (编辑)音频;2. 通过比较输入和输出音频的差异,自动学习只修改需要编辑的片段;3. 只需要编辑指令,而不需要完整的目标音频描述作为文本输入。

图2:AUDIT 架构图
AUDIT 在多个音频编辑任务(例如添加、删除、替换、修复、超分辨率)的客观和主观指标方面均取得了最先进的成果。如图2所示,该模型包括了文本编码模块、音频编码模块、音频解码模块以及扩散模块。AUDIT 在相关任务上均取得了 SOTA 的结果。
Geoformer:采用原子间相对几何位置编码的分子建模Transformer

论文链接:https://openreview.net/pdf?id=9o6KQrklrE
GitHub链接:https://github.com/microsoft/AI2BMD/tree/Geoformer
Transformer 架构已经深度应用于自然语言处理、图像和视频的建模领域。研究者们希望可以将 Transformer 的强大建模能力扩展到分子建模的领域。目前已有的一些 Transformer 方法,主要是采用原子间的距离作为相对位置编码来捕获分子中的位置信息。然而,这些方法只依赖于距离信息,对于复杂的分子结构,其描述和建模的精确度往往是有限的。
最近,微软研究院科学智能中心的研究团队推出了一种基于 Transformer 的分子建模方法 Geoformer。Geoformer 模型的设计目标是在分子建模中更精确地捕获复杂的几何信息。其设计理念源于原子簇扩展(ACE)理论,并通过创新地设计一种名为 Interatomic Positional Encoding(IPE)的位置编码方式(图3),将分子中原子环境的参数信息精准地融入到模型中,从而更有效地对分子结构进行建模,进一步预测各种分子特性。

图3:Interatomic Positional Encoding(IPE)示意图
Geoformer 模型在 QM9 数据集和新近发布的 Molecule3D 数据集上进行了评估。评估结果显示,无论是在 QM9 数据集还是在 Molecule3D 数据集上,Geoformer 模型都超越了当前最先进的算法,实现了与 Equivariant GNN 相当的性能。这表明,Geoformer 模型为基于 Transformer 架构的分子几何建模开创了新的可能。
同时,通过对不同分子的位置编码进行可视化,研究团队发现,与只使用原子间距离的其他位置编码相比,IPE能够捕获更丰富的位置信息(图4),从而可以更全面地描绘出分子结构中的几何信息。

图4:Interatomic Positional Encoding(IPE)在QM9分子上的可视化
通过建模空间信息学习拓扑不变的脑电表征

论文链接:https://openreview.net/forum?id=hiOUySN0ub
项目链接:https://seqml.github.io/MMM/
在医学监测、疾病诊断、康复治疗以及脑机接口系统等领域,头皮脑电图(Scalp EEG)因其非侵入性和低成本的优势而得到广泛应用。然而,虽然 EEG 信号的采集相对容易,但其解释和标记往往需要大量的专业人力成本。另一方面,不同 EEG 记录在电极布置(montage)和采样率方面存在差异,这使得跨数据集的联合学习与模型迁移变得异常困难。
为了解决这一问题,研究员们提出了一种创新的自监督学习框架 MMM,旨在有效利用大量来自不同数据集的无标注数据。基于 MMM 框架,研究员们建立了脑电信号处理领域第一个可以跨数据集训练并可应用于下游不同任务的基础模型。

图5:(a) MMM 总体框架;(b) 构建基于脑区的区域级别节点;(c) 多维位置编码;(d) 区域节点与电极节点之间的注意力掩码矩阵
基于掩码自编码器,MMM 框架能够将具有不同传感器配置的EEG数据映射到统一的表示中。研究员们根据神经科学中的发现,为不同脑区引入了总共17个区域级别的节点来从 EEG 通道中提取局部信息。这些经过良好学习的区域级别节点构成了统一的隐表示,可以处理不同的上游数据格式并应用在下游任务中。此外,MMM 还引入多维位置编码以编码传感器的空间位置信息,并通过多阶段掩码策略来增强隐藏表示的鲁棒性。
为了评估 MMM 的有效性,研究员们在情感识别任务上验证了该方法并取得了最先进的性能。进一步的实验表明,通过在大量的非情感检测任务下的无标注脑电数据集上进行预训练,MMM 可以在下游任务上取得更好的效果。这也证明了基础模型在不同类型的脑电数据集之间具有强大的迁移泛化能力。
EEG 的基础模型提高了 EEG 信号处理的效率、通用性、准确性。研究员们期待它在更多 EEG 相关应用,特别是在个性化医疗、神经科学研究以及脑机接口技术等领域中发挥重要作用。
用生成式语言模型增强基于嵌入的文档索引

论文链接:https://arxiv.org/abs/2309.13335
目前文档检索有三类方法,分别是基于词语、嵌入、生成。基于词语的方法能够构建单词或短语的倒排索引,但无法利用语义信息。基于嵌入的方法可用双塔架构将查询和文档编码为嵌入向量,然后应用近似最近邻(ANN)搜索,但优化目标会被分成两个阶段,且 ANN 和最近邻的召回性能存在一定差距。基于生成的方法采用序列到序列的模型直接输入查询、输出文档标识符,在小语料库上表现优异,但由于高延迟很难扩展到大语料库,且语料库不可变。为了解决这些问题,微软亚洲研究院的研究员们提出了模型增强向量索引 MEVI,兼具高召回率和较快检索速度。
研究员们构建了残差量化(RQ)码本对文档进行聚类,RQ码本保留了文档簇的层次结构,适合自回归生成。此外,研究员们还构建了序列到序列模型。输入查询后,序列到序列模型可以根据RQ码本直接生成虚拟集群标识符,然后用 ANN 在虚拟集群中搜索相关文档。训练过程中,研究员们使用经过数据增强的查询-文档对进行模型训练;推理过程中,则使用波束搜索根据 RQ 码本检索 top-K 个集群,并在集群中用 ANN 搜索查询嵌入。
MEVI 的设计解决了传统方法的局限性:RQ 码本大小适中,使自回归解码器延迟较低;同时,新文档也可以插入到对应集群中。为了进一步增强召回性能,研究员们还将生成的文档集群和基于嵌入方法得到的文档进行了集成,同时发挥二者的优势。

图6:MEVI 框架图
在实验中,研究员们选取了 AR2 和 T5-ANCE 模型作为基于嵌入的方法。实验结果表明,MEVI 显著提高了召回率,在 MSMARCO Passage 数据集上实现了+3.62%的 MRR@10、+7.32%的R@50、+10.54%的R@1000,在 Natural Questions 数据集上实现了+5.04%的R@5、+5.46%的R@20,+5.96%的R@100。MEVI 还具有较低延迟,且能够支持动态语料库的能力。
关于扩散模型的泛化性质

论文链接:https://openreview.net/pdf?id=hCUG1MCFk5
扩散模型在许多实际应用中都取得了空前的成功,包括计算机视觉、自然语言处理、多模态学习、AI4Science 等方面,并带来了新的巨大的商业应用场景。与其他生成模型类似,扩散模型在数学上亦是通过建立未知目标分布与已知先验分布之间的(随机)传输映射,来达到生成符合目标分布的样本的目的。然而,扩散模型仅通过模拟简单的加噪去噪过程,便可实现样本的高质量生成。这背后的数学原理,包括扩散模型的泛化性能究竟是怎样的,目前还没有得到很好的解释。
对此,微软亚洲研究院的研究员们从理论和实验两个方面分析了扩散模型的泛化性质。一方面,当未知目标分布具有紧支集(即数据的分布范围有限)时,可以建立扩散模型的泛化误差在训练过程中的理论上界。当训练提前终止时,这一估计对于数据量和模型容量的依赖是多项式的,且不会出现所谓的维度灾难现象。另一方面,当未知目标分布具有多聚类中心且距离相对远时,利用扩散模型做密度估计将变得更困难:聚类中心之间的距离越远,扩散模型的训练和生成效果也越差。这些理论发现均在实际数据集上得到了验证。

图7:目标分布的聚类中心之间的距离越远,扩散模型学习和生成的效果越差
TextDiffuser:让文本渲染不再成为扩散模型的难题

TextDiffuser 论文链接:https://openreview.net/pdf?id=ke3RgcDmfO
TextDiffuser-2 论文链接:https://arxiv.org/pdf/2311.16465v1.pdf
代码链接:https://github.com/microsoft/unilm/tree/master/textdiffuser
Demo 链接:https://huggingface.co/spaces/JingyeChen22/TextDiffuser
近年来,文本生成图像领域取得了显著进展。然而,即便是最先进的技术,也面临着一个共同的挑战:如何稳定且清晰地在图像中渲染文本。这个问题尤其影响了图像的美观和实用性。文本在我们生活中无处不在,从广告海报到书籍封面,再到路牌指示,它们都蕴含着重要的信息。如果人工智能模型能够高效且准确地生成包含文本的图像,这将极大地推动设计和视觉艺术领域的发展。
为了应对这一挑战,微软亚洲研究院自然语言计算组提出了 TextDiffuser 模型。该模型包含两个阶段的工作:首先,通过用户的提示(prompt)确定文本的布局;其次,结合这一布局和提示生成图像。TextDiffuser 利用 Layout Transformer 技术,自回归地生成了每个关键词的坐标框,为每个字符提供了精确的控制。在第二阶段中,通过对 Stable Diffusion 架构的改进,模型能够在指定位置生成清晰的字符。TextDiffuser 还引入了图像补全任务,允许用户在已有图像中修改文本区域,为创意设计提供了灵活性。

图8:TextDiffuser 框架图,包含两个阶段:布局生成与图像生成
为了支持这一技术,团队构建了包含1000万张文本图像的 MARIO-10M 数据集,并设计了 MARIO-Eval 文本渲染任务的大规模基准。实验分析,TextDiffuser 在文本渲染任务上的表现优于现有的文本生成图像方法。用户调研也表明用户对 TextDiffuser 的生成结果高度满意。
此外,近日 TextDiffuser-2 的发布进一步提升了图像渲染的多样性和灵活性。TextDiffuser 的推出和持续发展在“图像中准确渲染文本”这一任务上取得了进步。未来,研究团队将继续在这一领域深入研究和探索,解决更多复杂的视觉和文本结合问题。
 文章来源:https://www.toymoban.com/news/detail-776903.html
文章来源:https://www.toymoban.com/news/detail-776903.html
图9:与现有文本生成图像方法相比,TextDiffuser 可以生成正确的文本,并且文本与背景融合度较高文章来源地址https://www.toymoban.com/news/detail-776903.html
到了这里,关于NeurIPS上新 | 从扩散模型、脑电表征,到AI for Science,微软亚洲研究院精选论文的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!