实时统计,也可以理解为流式计算,一个输入流,一个输出流,源源不断。
Kafka Stream
Kafka Stream是Apache Kafka从0.10版本引入的一个新Feature。它是提供了对存储于Kafka内的数据进行流式处理和分析的功能。
Kafka Stream的特点
- Kafka Stream提供了一个非常简单而轻量的Library,它可以非常方便地嵌入任意Java应用中,也可以任意方式打包和部署
- 除了Kafka外,无任何外部依赖
- 充分利用Kafka分区机制实现水平扩展和顺序性保证
- 通过可容错的state store实现高效的状态操作(如windowed join和aggregation)
- 支持正好一次处理语义
- 提供记录级的处理能力,从而实现毫秒级的低延迟
- 支持基于事件时间的窗口操作,并且可处理晚到的数据(late arrival of records)
- 同时提供底层的处理原语Processor(类似于Storm的spout和bolt),以及高层抽象的DSL(类似于Spark的map/group/reduce)
相关术语
源处理器和Sink处理器是Kafka Streams中的两个重要组件,它们分别用于从输入流获取数据并将处理后的数据发送到输出流。以下是它们的工作流程的文字图示表达:
[Source Processor] -> [Processor Topology] -> [Sink Processor]
-
源处理器(Source Processor):
- 源处理器负责从一个或多个输入主题(topics)中提取数据,并将数据转换为KStream或KTable对象。
- 它通常是处理拓扑结构的起点,从一个或多个输入主题中读取数据,并将其发送到处理拓扑中的下一个处理器。
-
Sink 处理器(Sink Processor):
- Sink处理器负责将经过处理的数据发送到一个或多个输出主题,或者执行其他终端操作。
- 它通常是处理拓扑结构的终点,在处理拓扑的最后阶段接收处理后的数据,并将其发送到输出主题,或者执行其他终端操作,如存储到数据库、发送到外部系统等。
-
Processor Topology:
- 处理拓扑包含了源处理器、中间处理器和Sink处理器,它定义了数据流的处理逻辑。
- 在处理拓扑中,数据流会通过一系列的处理器进行转换、聚合和处理,最终到达Sink处理器,完成整个处理流程。
通过这种处理流程,Kafka Streams可以实现对数据流的灵活处理和转换,使得你能够方便地构建实时流处理应用程序。
kafka stream demo
依赖
<!-- kafka -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<version>2.5.5.RELEASE</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.5.1</version>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<version>2.5.1</version>
</dependency>
环境准备
- 安装kafka
- 建立topic,我以keycloak为例,它有login_in这个主题,用来记录登录信息
- 建立topic,如total_record,用来存储login_in的实时统计的结果
- 可使用springboot继承的消费者,去消费total_record,如写入数据库进行持久化
业务代码
- 配置类
@Configuration
@EnableKafkaStreams
public class KafkaStreamConfig {
private static final int MAX_MESSAGE_SIZE = 16 * 1024 * 1024;
@Value("${spring.kafka.bootstrap-servers}")
private String hosts;
@Value("${spring.kafka.consumer.group-id}")
private String group;
@Bean(name = KafkaStreamsDefaultConfiguration.DEFAULT_STREAMS_CONFIG_BEAN_NAME)
public KafkaStreamsConfiguration defaultKafkaStreamsConfig() {
Map<String, Object> props = new HashMap<>();
props.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG, hosts);
props.put(StreamsConfig.APPLICATION_ID_CONFIG, group + "_stream_aid");
props.put(StreamsConfig.CLIENT_ID_CONFIG, group + "_stream_cid");
props.put(StreamsConfig.RETRIES_CONFIG, 3);
props.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "latest");//从最近的消息开始消费
props.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
props.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
return new KafkaStreamsConfiguration(props);
}
}
- 消费类
@Configuration
@Slf4j
public class KafkaStreamListener {
@Autowired
ReportLoginTypeMapper reportLoginTypeMapper;
@KafkaListener(topics = "total_record")
public void listen(ConsumerRecord<String, String> record) {
// 将时间戳转换为本地日期时间
LocalDateTime dateTime = LocalDateTime.ofInstant(Instant.ofEpochMilli(record.timestamp()), ZoneId.systemDefault());
ReportLoginType reportLoginType=new ReportLoginType();
reportLoginType.setLoginType(record.key());
reportLoginType.setCreateAt(dateTime);
reportLoginType.setCount(Integer.parseInt(record.value()));
reportLoginTypeMapper.insert(reportLoginType);
}
@Bean
public KStream<String, String> kStream(StreamsBuilder streamsBuilder) {
KStream<String, String> stream = streamsBuilder.stream("KC_LOGIN");
KStream<String, String> serializedStream = stream.mapValues(jsonString -> {
// 分组依据
if (JSONUtil.parseObj(jsonString).containsKey("details")) {
JSONObject details = JSONUtil.parseObj(jsonString).getJSONObject("details");
if (details.containsKey("loginType")) {
String loginType = details.getStr("loginType");
return loginType;
}
return "";
}
else {
return "";
}
});
/**
* 处理消息的value
*/
serializedStream.flatMapValues(new ValueMapper<String, Iterable<String>>() {
@Override
public Iterable<String> apply(String value) {
return Arrays.asList(value.split(" "));
}
}).filter((key, value) -> !value.equals(""))
// 按照value进行聚合处理
.groupBy((key, value) -> value)// 这进而的value是kafka的消息内容
// 时间窗口
.windowedBy(TimeWindows.of(Duration.ofSeconds(60)))
// 统计单词的个数
.count()
// 转换为kStream
.toStream().map((key, value) -> {
// key是分组的key,它是一个window对象,它里面有分组key和时间窗口的开始时间和结束时间,方便后期我们统计,value是分组count的结果
return new KeyValue<>(key.toString(), value.toString());
})
// 发送消息
.to("topic-out");
return stream;
}
}
上面代码在分组统计之后,给把数据发到topic-out的kafka主题里,需要注意kafka主题的key是一个代码分组key和窗口期的字符串,方便我们后期做数据统计,一般这些窗口期的数据和key一样,会写到数据表里,像我们查询数据表时,会根据它们选择最大的value值,因为同一窗口里的计数,我们取最大就可以,它已经包含了相同窗口期的其它值。文章来源:https://www.toymoban.com/news/detail-776943.html
select login_type,window_start,window_end,max(count) FROM report_login_type
where login_type='password' and create_at>='2024-01-10 14:00:00'
group by login_type,window_start,window_end
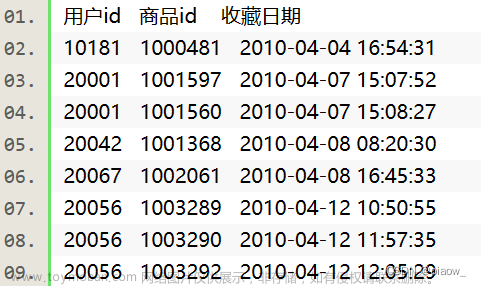
最后看一下total_record的内容
 文章来源地址https://www.toymoban.com/news/detail-776943.html
文章来源地址https://www.toymoban.com/news/detail-776943.html
到了这里,关于springboot~kafka-stream实现实时统计的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!