作者 | JiekeXu
来源 |公众号 JiekeXu DBA之路(ID: JiekeXu_IT)
如需转载请联系授权 | (个人微信 ID:JiekeXu_DBA)
大家好,我是 JiekeXu,很高兴又和大家见面了,今天和大家一起来看看 sqluldr2 的安装与使用,欢迎点击上方蓝字“JiekeXu DBA之路”关注我的公众号,标星或置顶,更多干货第一时间到达!
sqluldr2 使用情况基本介绍
近期在做一些国产数据库的 POC 工作,在数据迁移导出时用到了数据导出工具 sqluldr2,它是一款十分不错的 oracle 数据导出工具,还支持导出时同时生成 sqlldr 的控制文件,它可以将数据以 TXT/CSV 等格式导出,能导出亿级数据为 excel 文件,包含32、64 位程序,不仅在大数据量导出方面速度超快,导入速度也是非常快速。

基本介绍
sqluldr2 是一款Oracle数据快速导出工具,包含32、64位程序,sqluldr2 在大数据量导出方面速度超快,能导出亿级数据为excel文件,另外它的导入速度也是非常快速,功能是将数据以TXT/CSV等格式导出。
软件说明
下载完sqluldr解压后,文件夹内容如下:
sqluldr2.exe 用于32位windows平台;
sqluldr264.exe 用于64位windows平台。
sqluldr2_linux32_10204.bin 适用于linux32位操作系统;
sqluldr2_linux64_10204.bin 适用于linux64位操作系统;
可在公众号后台回复关键字【sqluldr2】获取下载文件。

使用说明
1、首先将 sqluldr2_linux64_10204.bin 复制到执行目录下,给予可执行权限,即可开始使用
mkdir -m 775 /home/oracle/tmp/sqluldr22、 help 查看帮助
chmod 775 sqluldr2_linux64_10204.bin./sqluldr2_linux64_10204.binSQL*UnLoader: Fast Oracle Text Unloader (GZIP, Parallel), Release 4.0.1(@) Copyright Lou Fangxin (AnySQL.net) 2004 - 2010, all rights reserved.License: Free for non-commercial useage, else 100 USD per server.Usage: SQLULDR2 keyword=value [,keyword=value,...]Valid Keywords: user = username/password@tnsname sql = SQL file name query = select statement field = separator string between fields record = separator string between records rows = print progress for every given rows (default, 1000000) file = output file name(default: uldrdata.txt) log = log file name, prefix with + to append mode fast = auto tuning the session level parameters(YES) text = output type (MYSQL, CSV, MYSQLINS, ORACLEINS, FORM, SEARCH). charset = character set name of the target database. ncharset= national character set name of the target database. parfile = read command option from parameter file for field and record, you can use '0x' to specify hex character code, \r=0x0d \n=0x0a |=0x7c ,=0x2c, \t=0x09, :=0x3a, #=0x23, "=0x22 '=0x27

3、执行数据导出命令
3.1 sqluldr2的链接数据库
本地执行方式:users 参数可以省略不写,和 expdp username/passwd 方式一样
export ORACLE_SID=orcl
sqluldr2 testuser/testuser query=test_table1 file=test_table1.txt客户端连接:tns 方式
sqluldr2 testuser/testuser@orcl query=test_table1 file=test_table1.txt客户端连接:简易连接
sqluldr2 testuser/testuser@x.x.x.x:1521/orcl query=test_table1 file=test_table1.txt3.2 要导出的数据由 query 控制
query 参数如果整表导出,可以直接写表名,如果需要查询运算和 where 条件,query=“sql文本”,也可以把复杂 SQL 写入到文本中由 query 调用。
3.3 分隔符设置
默认是逗号分隔符,通过field参数指定分隔符
sqluldr2 testuser/testuser query=chen.tt1 field=";"3.4 大数据量操作
对于大表可以输出到多个文件中,指定行数分割或者按照文件大小分割,例如:
sqluldr2 testuser/testuser@orcl query="select * from test_table2" file=test_table2_%B.txt batch=yes rows=5000003.5 常规导出
Win:
sqluldr2 test/test@127.0.1.1/orcl query="select * from temp_001" head=yes file=d:\tmp001.csvLinux:
cd /home/oracle/tmp/sqluldr2
./sqluldr2_linux64_10204.bin sys query="select * from scott.emp" head=yes file=./emp01.csv
0 rows exported at 2023-07-26 10:45:47, size 0 MB.
14 rows exported at 2023-07-26 10:45:47, size 0 MB.
output file ./emp01.csv closed at 14 rows, size 0 MB.说明:head=yes 表示输出表头

3.6 使用 SQL 参数
./sqluldr2_linux64_10204.bin scott/scott@127.0.0.1/testogg sql=test_sql.sql head=yes file=/home/oracle/tmp/sqluldr2/test_emp01.csvtest_sql.sql 的内容为:
select * from scott.dept注意:这里仅支持一条 SQL,有无分号均可。当然 SQL也支持表关联子查询等。

3.7 使用 log 参数
当集成 sqluldr2 在脚本中时,就希望屏幕上不输出这些信息,但又希望这些信息能保留,这时可以用“LOG”选项来指定日志文件名。
sqluldr2 test/test@127.0.0.1/orcl sql=test.sql head=yes file=d:\tmp001.csv log=+d:\tmp001.log
Linux:
--连接到 PDB1
sqlplus sys/Oracle@JIEKEXUPDB1 as sysdba
--创建用户并赋权
create user test identified by test;
grant connect,resource,dba to test;
--连接到测试用户,创建表 t1
conn test/test@JIEKEXUPDB1
create table t1 as select * from dba_objects;
commit;
--导出
./sqluldr2_linux64_10204.bin test/test@JIEKEXUPDB1 query=t1 head=yes file=/home/oracle/t1.csv log=/home/oracle/test_t1.log
3.8 使用 table 参数
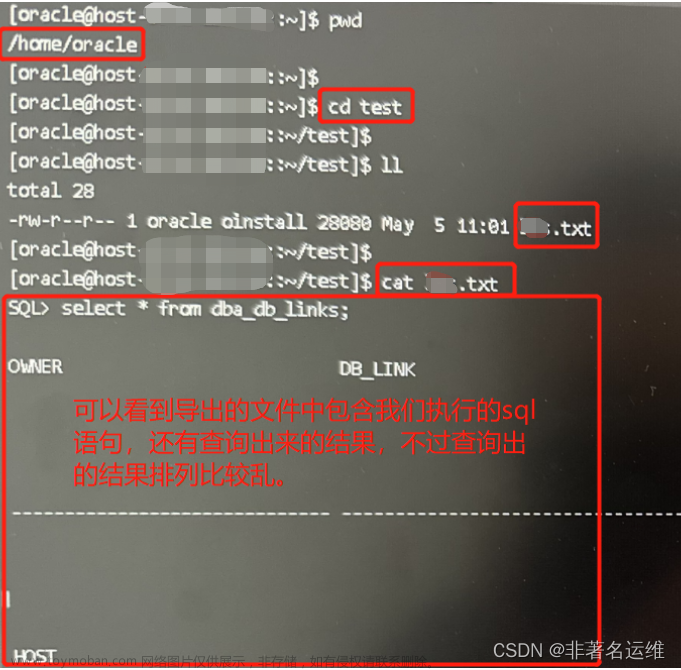
当使用 table 参数时,在目录下会生成对应的ctl控制文件,如下语句会生成temp_001_sqlldr.ctl文件。
./sqluldr2_linux64_10204.bin test/test@JIEKEXUPDB1 query="select * from t1" table=t1 head=yes file=/home/oracle/test1.csv
生成的控制文件t1_sqlldr.ctl的内容如下:
--
-- SQL*UnLoader: Fast Oracle Text Unloader (GZIP), Release 3.0.1
-- (@) Copyright Lou Fangxin (AnySQL.net) 2004 - 2010, all rights reserved.
--
-- CREATE TABLE t1 (
-- OWNER VARCHAR2(128),
-- OBJECT_NAME VARCHAR2(128),
-- SUBOBJECT_NAME VARCHAR2(128),
-- OBJECT_ID NUMBER,
-- DATA_OBJECT_ID NUMBER,
-- OBJECT_TYPE VARCHAR2(23),
-- CREATED DATE,
-- LAST_DDL_TIME DATE,
-- TIMESTAMP VARCHAR2(19),
-- STATUS VARCHAR2(7),
-- TEMPORARY VARCHAR2(1),
-- GENERATED VARCHAR2(1),
-- SECONDARY VARCHAR2(1),
-- NAMESPACE NUMBER,
-- EDITION_NAME VARCHAR2(128),
-- SHARING VARCHAR2(18),
-- EDITIONABLE VARCHAR2(1),
-- ORACLE_MAINTAINED VARCHAR2(1),
-- APPLICATION VARCHAR2(1),
-- DEFAULT_COLLATION VARCHAR2(100),
-- DUPLICATED VARCHAR2(1),
-- SHARDED VARCHAR2(1),
-- CREATED_APPID NUMBER,
-- CREATED_VSNID NUMBER,
-- MODIFIED_APPID NUMBER,
-- MODIFIED_VSNID NUMBER
-- );
--
OPTIONS(BINDSIZE=2097152,READSIZE=2097152,SKIP=1,ERRORS=-1,ROWS=50000)
LOAD DATA
INFILE '/home/oracle/test1.csv' "STR X'0a'"
INSERT INTO TABLE t1
FIELDS TERMINATED BY X'2c' TRAILING NULLCOLS
(
"OWNER" CHAR(128) NULLIF "OWNER"=BLANKS,
"OBJECT_NAME" CHAR(128) NULLIF "OBJECT_NAME"=BLANKS,
"SUBOBJECT_NAME" CHAR(128) NULLIF "SUBOBJECT_NAME"=BLANKS,
"OBJECT_ID" CHAR(46) NULLIF "OBJECT_ID"=BLANKS,
"DATA_OBJECT_ID" CHAR(46) NULLIF "DATA_OBJECT_ID"=BLANKS,
"OBJECT_TYPE" CHAR(23) NULLIF "OBJECT_TYPE"=BLANKS,
"CREATED" DATE "YYYY-MM-DD HH24:MI:SS" NULLIF "CREATED"=BLANKS,
"LAST_DDL_TIME" DATE "YYYY-MM-DD HH24:MI:SS" NULLIF "LAST_DDL_TIME"=BLANKS,
"TIMESTAMP" CHAR(19) NULLIF "TIMESTAMP"=BLANKS,
"STATUS" CHAR(7) NULLIF "STATUS"=BLANKS,
"TEMPORARY" CHAR(1) NULLIF "TEMPORARY"=BLANKS,
"GENERATED" CHAR(1) NULLIF "GENERATED"=BLANKS,
"SECONDARY" CHAR(1) NULLIF "SECONDARY"=BLANKS,
"NAMESPACE" CHAR(46) NULLIF "NAMESPACE"=BLANKS,
"EDITION_NAME" CHAR(128) NULLIF "EDITION_NAME"=BLANKS,
"SHARING" CHAR(18) NULLIF "SHARING"=BLANKS,
"EDITIONABLE" CHAR(1) NULLIF "EDITIONABLE"=BLANKS,
"ORACLE_MAINTAINED" CHAR(1) NULLIF "ORACLE_MAINTAINED"=BLANKS,
"APPLICATION" CHAR(1) NULLIF "APPLICATION"=BLANKS,
"DEFAULT_COLLATION" CHAR(100) NULLIF "DEFAULT_COLLATION"=BLANKS,
"DUPLICATED" CHAR(1) NULLIF "DUPLICATED"=BLANKS,
"SHARDED" CHAR(1) NULLIF "SHARDED"=BLANKS,
"CREATED_APPID" CHAR(46) NULLIF "CREATED_APPID"=BLANKS,
"CREATED_VSNID" CHAR(46) NULLIF "CREATED_VSNID"=BLANKS,
"MODIFIED_APPID" CHAR(46) NULLIF "MODIFIED_APPID"=BLANKS,
"MODIFIED_VSNID" CHAR(46) NULLIF "MODIFIED_VSNID"=BLANKS
)
顺便说一句,每次运行都需要 ./sqluldr2_linux64_10204.bin 有点麻烦,我们将其重命名并放到数据库服务器 $ORACLE_HOME/bin 目录下,便可以直接运行了。
mv sqluldr2_linux64_10204.bin sqluldr2
cp sqluldr2 $ORACLE_HOME/bin
which sqluldr2
4、本地 Oracle client 安装
1)如果想要访问远程数据库,导出远程数据库数据,需要在本地安装 Oracle 客户端软件,访问远端数据库,下载客户端 rpm 包或者标准的 Oracle 客户端 zip 包进行安装。
cd /home/jiekexu/soft/
oracle-instantclient-11.2.0.4.0-1.1.x86_64.rpm
oracle-instantclient11.2-sqlplus-11.2.0.4.0-1.x86_64.rpm
oracle-instantclient11.2-basic-11.2.0.4.0-1.x86_64.rpm2)这里以 prm 包为例,root用户使用rpm -ivh [包名] 进行安装:
如:rpm -ivh oracle-instantclient-11.2.0.4.0-1.1.x86_64.rpm
安装的文件默认放在两个位置:
头文件:/usr/lib/oracle/11.2/client64/下,如果在使用时报错找不到头文件,记得看路径是否是这个。
包文件:/usr/lib64/oracle/11.2.0.4.0/client/下,包含{bin、lib}两个文件夹;
3)创建oracle-instantclient.conf文件,并添加内容:
vim /etc/ld.so.conf.d/oracle-instantclient.conf
添加内容
/usr/lib64/oracle/11.2.0.4.0/client/lib/4)生效环境变量
source .ldconfig5)创建软连接
cd /usr/lib64/oracle/11.2.0.4.0/client/lib
执行
cd /usr/lib64/oracle/11.2.0.4.0/client/lib/
ln -s libclntsh.so.11.1 libclntsh.so5、主要参数说明
Field 分隔符 指定字段分隔符,默认为逗号
record 分隔符 指定记录分隔符,默认为回车换行,Windows下的换行
quote 引号符 指定非数字字段前后的引号符
例如现在要改变默认的字段分隔符,用“#”来分隔记录,导出的命令如下所示:
sqluldr2 test/test sql=tmp.sql field=#
在指定分隔符时,可以用字符的ASCII代码(0xXX,大写的XX为16进制的ASCII码值)来指定一个字符,常用的字符的ASCII代码如下:
回车=0x0d,换行=0x0a,TAB键=0x09,|=0x7c,&=0x26,井号=0x23,双引号=0x22,单引号=0x27,冒号=0x3a
注意:在选择分隔符时,一定不能选择会在字段值中出现的字符,例如TAB键,&、| 等均有可能会出现在字段值中,所以推荐在导出数据时,使用多个分隔符,如0x230x7c。
全文完,希望可以帮到正在阅读的你,如果觉得此文对你有帮助,可以分享给你身边的朋友,同事,你关心谁就分享给谁,一起学习共同进步~~~
欢迎关注我的公众号【JiekeXu DBA之路】,第一时间一起学习新知识!以下三个地址可以找到我,其他地址都属于盗版侵权爬取我的文章,而且代码格式、图片等均有错乱,不方便阅读,欢迎来我公众号或者墨天轮地址关注我,第一时间收获最新消息。
欢迎关注我的公众号【JiekeXu DBA之路】,第一时间一起学习新知识!
————————————————————————————
公众号:JiekeXu DBA之路
CSDN :https://blog.csdn.net/JiekeXu
墨天轮:https://www.modb.pro/u/4347
————————————————————————————
 文章来源:https://www.toymoban.com/news/detail-777147.html
文章来源:https://www.toymoban.com/news/detail-777147.html
分享几个数据库备份脚本
Oracle 表碎片检查及整理方案
OGG|Oracle GoldenGate 基础2022 年公众号历史文章合集整理Oracle 19c RAC 遇到的几个问题
OGG|Oracle 数据迁移后比对一致性OGG|Oracle GoldenGate 微服务架构
Oracle 查询表空间使用率超慢问题一则
Oracle 11g升级到19c需要关注的几个问题
国产数据库|TiDB 5.4 单机快速安装初体验
Oracle ADG 备库停启维护流程及增量恢复
Linux 环境搭建 MySQL8.0.28 主从同步环境
文章来源地址https://www.toymoban.com/news/detail-777147.html
从国产数据库调研报告中你都能了解哪些信息及我的总结建议
到了这里,关于Oracle 大数据量导出工具——sqluldr2 的安装与使用的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!