Llama 大模型介绍
我们介绍 LLaMA,这是一个基础语言模型的集合,参数范围从 7B 到 65B。我们在数万亿个Token上训练我们的模型,并表明可以专门使用公开可用的数据集来训练最先进的模型,而无需诉诸专有的和无法访问的数据集。特别是,LLaMA-13B 在大多数基准测试中都优于 GPT-3 (175B)。
Llama2 大模型介绍
我们开发并发布了 Llama 2,这是一组经过预训练和微调的大型语言模型 (LLM),其参数规模从 70 亿到 700 亿不等。我们经过微调的大语言模型(称为 Llama 2-Chat)针对对话用例进行了优化。我们的模型在我们测试的大多数基准上都优于开源聊天模型,并且根据我们对有用性和安全性的人工评估,可能是闭源模型的合适替代品。
相关网址
- https://ai.meta.com/llama/
- https://github.com/facebookresearch/llama
- https://huggingface.co/meta-llama/Llama-2-7b
- https://huggingface.co/docs/transformers/model_doc/llama
Llama 大语言模型提供的主要模型列表

Code Llama 模型
Code Llama 是一个基于 Llama 2 的大型代码语言模型系列,在开放模型、填充功能、对大输入上下文的支持以及编程任务的零样本指令跟踪能力中提供最先进的性能。我们提供多种风格来覆盖广泛的应用程序:基础模型 (Code Llama)、Python 专业化 (Code Llama - Python) 和指令跟随模型 (Code Llama - Instruct),每个模型都有 7B、13B 和 34B 参数。所有模型均在 16k 个标记序列上进行训练,并在最多 100k 个标记的输入上显示出改进。7B 和 13B Code Llama 和 Code Llama - 指令变体支持基于周围内容的填充。Code Llama 是通过使用更高的代码采样对 Llama2 进行微调而开发的。与 Llama 2 一样,我们对模型的微调版本应用了大量的安全缓解措施。有关模型训练、架构和参数、评估、负责任的人工智能和安全性的详细信息,请参阅我们的研究论文。Llama 材料(包括 Code Llama)的代码生成功能生成的输出可能受第三方许可的约束,包括但不限于开源许可。
Code Llama 提供的主要模型列表

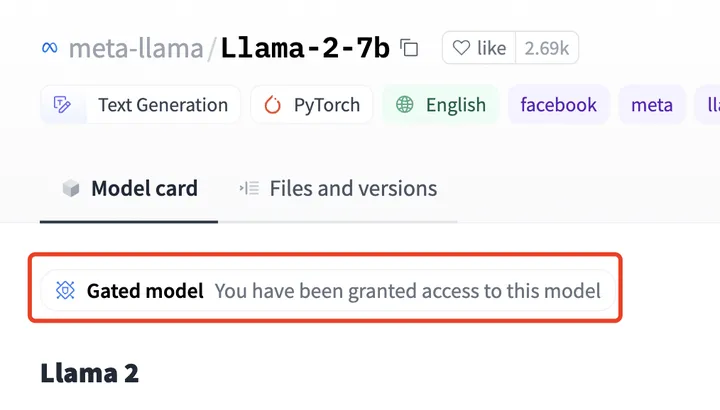
申请模型
申请地址 https://ai.meta.com/resources/models-and-libraries/llama-downloads/
申请通过后,在 hugging face 上如果邮箱一致,会提示已经授权。
使用模型
- 使用官方的 Api
- 使用第三方封装 Api llama.cpp-python ollama
- 使用 Langchain
- 使用 Hugging face 的 Transformers
Llama
https://github.com/facebookresearch/llama
torchrun--nproc_per_node1example_text_completion.py\
--ckpt_dirllama-2-7b/\
--tokenizer_pathtokenizer.model\
--max_seq_len128--max_batch_size4NCCL 错误
RuntimeError: Distributed package doesn't have NCCL built in
Windows 和 Mac 上基本跑不起来,因为 Torchrun 依赖 NCCL
https://pytorch.org/docs/stable/distributed.html
Llama.cpp
https://github.com/ggerganov/llama.cpp
Port of Facebook's LLaMA model in C/C++
因为很多同学受限于个人电脑的环境,没法运行完整的 Llama 模型。Llama.cpp 提供了一个非常好的移植版本,可以降低电脑的硬件要求,方便个人电脑运行与测试。
下载
gitclonehttps://github.com/ggerganov/llama.cpp.git
cdllama.cpp
make模型转换
通过对模型进行转化,可以降低资源消耗。
# obtain the original LLaMA model weights and place them in ./models
ls./models
65B30B13B7Btokenizer_checklist.chktokenizer.model
# [Optional] for models using BPE tokenizers
ls./models
65B30B13B7Bvocab.json
# install Python dependencies
python3-mpipinstall-rrequirements.txt
# convert the 7B model to ggml FP16 format
python3convert.pymodels/7B/
# [Optional] for models using BPE tokenizers
pythonconvert.pymodels/7B/--vocabtypebpe
# quantize the model to 4-bits (using q4_0 method)
./quantize./models/7B/ggml-model-f16.gguf./models/7B/ggml-model-q4_0.ggufq4_0
# update the gguf filetype to current if older version is unsupported by another application
./quantize./models/7B/ggml-model-q4_0.gguf./models/7B/ggml-model-q4_0-v2.ggufCOPY
# run the inference
./main-m./models/7B/ggml-model-q4_0.gguf-n128此步可以省略,直接下载别人转换好的量化模型即可。https://huggingface.co/TheBloke/Llama-2-7b-Chat-GGUF
运行
命令行交互模式
./main-m./models/llama-2-7b.Q4_0.gguf-i-n256--color开启 Server 模式,访问 http://127.0.0.1:8080/
./server-m./models/llama-2-7b.Q4_0.ggufLlama-cpp-python
https://github.com/abetlen/llama-cpp-python
pipinstallllama-cpp-pythonMac M1 上构建的时候需要加上特殊的参数
CMAKE_ARGS="-DLLAMA_METAL=on -DCMAKE_OSX_ARCHITECTURES=arm64"FORCE_CMAKE=1pipinstall-Ullama-cpp-python--no-cache-dir--force-reinstall启动 Api 模式
pipinstallllama-cpp-python[server]
python-mllama_cpp.server--modelmodels/llama-2-7b.Q4_0.gguf
python-mllama_cpp.server--modelmodels/llama-2-7b.Q4_0.gguf--n_gpu_layers1Ollama
- 官网 https://ollama.ai/
- github https://github.com/jmorganca/ollama
- docker https://ollama.ai/blog/ollama-is-now-available-as-an-official-docker-image
(base)hogwarts:~seveniruby$ollamaservecodellama:7b
2023/10/0802:31:04images.go:987:totalblobs:6
2023/10/0802:31:04images.go:994:totalunusedblobsremoved:0
2023/10/0802:31:04routes.go:535:Listeningon127.0.0.1:11434api 文档 https://github.com/jmorganca/ollama/blob/main/docs/api.md
基于Langchain使用Llama
使用Langchain调用
def test_llama_cpp_local():
"""
使用本地模型
:return:
"""
llm = Llama(model_path="/Users/seveniruby/projects/llama.cpp/models/llama-2-7b.Q4_0.gguf")
output = llm("Q: 法国的首都在哪里\n A: ", echo=True, max_tokens=6, temperature=0)
debug(json.dumps(output, indent=2, ensure_ascii=False))输出
{
"id":"cmpl-6d3e491e-716f-4e6c-b167-4f52e3f9786f",
"object":"text_completion",
"created":1696709780,
"model":"/Users/seveniruby/projects/llama.cpp/models/llama-2-7b.Q4_0.gguf",
"choices":[
{
"text":"Q: 法国的首都在哪里\n A: 巴黎。\n",
"index":0,
"logprobs":null,
"finish_reason":"length"
}
],
"usage":{
"prompt_tokens":18,
"completion_tokens":6,
"total_tokens":24
}
}使用Langchain结合Api服务
def test_langchain_llm():
llm = OpenAI(
openai_api_key=None,
openai_api_base='http://127.0.0.1:8000/v1',
stop=["Q:", "\n"]
)
debug(llm)
prompt = "Q: 中国的首都在哪里?A: "
output = llm(prompt)
debug(output)基于Langchain与Hugging face
def test_pipeline():
pipe = pipeline(
"text-generation",
model="meta-llama/Llama-2-7b-hf",
torch_dtype=torch.float16,
device='mps', # 按需改成你的cuda或者cpu
revision='main',
)
debug(pipe)
debug(pipe('法国的首都在哪里'))更多Python基础语法趣味学习视频,请点击!文章来源:https://www.toymoban.com/news/detail-777162.html
 文章来源地址https://www.toymoban.com/news/detail-777162.html
文章来源地址https://www.toymoban.com/news/detail-777162.html
到了这里,关于人工智能 | Llama大模型:与AI伙伴合二为一,共创趣味交流体验的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!