一、实验目的
熟练掌握常用的hadoop shell命令
二、实验内容
1.学习在开启、关闭Hadoop
2.学习在Hadoop中创建、修改、查看、删除文件夹及文件
3.学习改变文件的权限及文件的拥有者
4.学习使用shell命令提交job任务
5.Hadoop安全模式的进入与退出
三、实验原理或流程
调用文件系统(FS)Shell命令应使用 hadoop fs <args>的形式。 所有的的FS shell命令使用URI路径作为参数。URI格式是scheme://authority/path。对HDFS文件系统,scheme是hdfs,对本地文件系统,scheme是file。其中scheme和authority参数都是可选的,如果未加指定,就会使用配置中指定的默认scheme。一个HDFS文件或目录比如/parent/child可以表示成hdfs://namenode:namenodeport/parent/child,或者更简单的/parent/child(假设你配置文件中的默认值是namenode:namenodeport)。大多数FS Shell命令的行为和对应的Unix Shell命令类似,出错信息会输出到stderr,其他信息输出到stdout。
四、实验过程及源代码
1.打开终端模拟器,切换到/apps/hadoop/sbin目录下,启动Hadoop
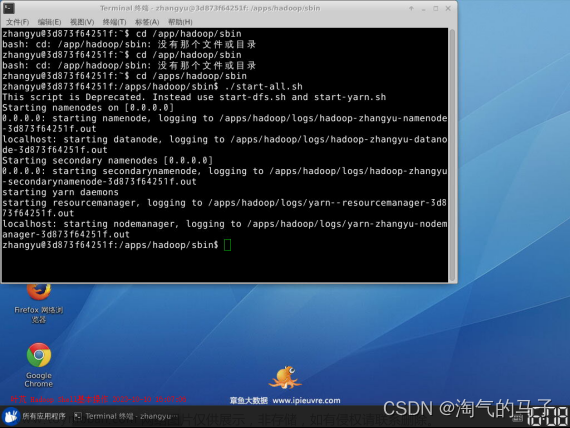
2.执行jps,检查一下Hadoop相关进程是否启动

3.在/目录下创建一个test1文件夹
hadoop fs -mkdir /test1
- 在Hadoop中的test1文件夹中创建一个file.txt文件
hadoop fs -touchz /test1/file.txt
- 查看根目录下所有文件
hadoop fs -ls /

- 还可以使用ls -R的方式递归查看根下所有文件
hadoop fs -ls -R /

- 将Hadoop根下test1目录中的file.txt文件,移动到根下并重命名为file2.txt
hadoop fs -mv /test1/file.txt /file2.txt

Hadoop中的mv用法同Linux中的一样,都可以起到移动文件和重命名的作用。
- 将Hadoop根下的file2.txt文件复制到test1目录下
hadoop fs -cp /file2.txt /test1

- 在Linux本地/data目录下,创建一个data.txt文件,并向其中写入hello hadoop
cd /data
touch data.txt
echo hello hadoop! >> data.txt

- 将Linux本地/data目录下的data.txt文件,上传到HDFS中的/test1目录下hadoop fs -put /data/data.txt /test1
- 查看Hadoop中/test1目录下的data.txt文件
hadoop fs -cat /test1/data.txt

- 除此之外还可以使用tail方法
hadoop fs -tail /test1/data.txt

tail方法是将文件尾部1K字节的内容输出。支持-f选项,行为和Unix中一致。
- 查看Hadoop中/test1目录下的data.txt文件大小
hadoop fs -du -s /test1/data.txt

-du 后面可以不加-s,直接写目录表示查看该目录下所有文件大小
- text方法可以将源文件输出为文本格式。允许的格式是zip和TextRecordInputStream。
hadoop fs -text /test1/data.txt

- stat方法可以返回指定路径的统计信息,有多个参数可选,当使用-stat选项但不指定format时候,只打印文件创建日期,相当于%y
hadoop fs -stat /test1/data.txt

下面列出了format的形式:
%b:打印文件大小(目录为0)
%n:打印文件名
%o:打印block size (我们要的值)
%r:打印备份数
%y:打印UTC日期 yyyy-MM-dd HH:mm:ss
%Y:打印自1970年1月1日以来的UTC微秒数
%F:目录打印directory, 文件打印regular file
- 将Hadoop中/test1目录下的data.txt文件,下载到Linux本地/apps目录中hadoop fs -get /test1/data.txt /apps
- 查看一下/apps目录下是否存在data.txt文件
ls /apps

18.使用chown方法,改变Hadoop中/test1目录中的data.txt文件拥有者为root,使用-R将使改变在目录结构下递归进行。
hadoop fs -chown root /test1/data.txt

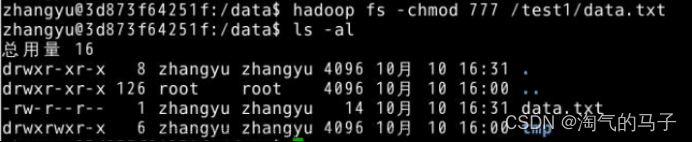
19.使用chmod方法,赋予Hadoop中/test1目录中的data.txt文件777权限
hadoop fs -chmod 777 /test1/data.txt
- 删除Hadoop根下的file2.txt文件
hadoop fs -rm /file2.txt

- 删除Hadoop根下的test1目录
hadoop fs -rm -r /test1

- 当在Hadoop中设置了回收站功能时,删除的文件会保留在回收站中,可以使用expunge方法清空回收站。
hadoop fs -expunge

在分布式文件系统启动的时候,开始的时候会有安全模式,当分布式文件系统处于安全模式的情况下,文件系统中的内容不允许修改也不允许删除,直到安全模式结束。安全模式主要是为了系统启动的时候检查各个DataNode上数据块的有效性,同时根据策略必要的复制或者删除部分数据块。运行期通过命令也可以进入安全模式。在实践过程中,系统启动的时候去修改和删除文件也会有安全模式不允许修改的出错提示,只需要等待一会儿即可。
- 使用Shell命令执行Hadoop自带的WordCount
首先切换到/data目录下,使用vim编辑一个data.txt文件,内容为:hello world hello hadoop hello ipieuvre
cd /data
vim data.txt
在HDFS的根下创建in目录,并将/data下的data.txt文件上传到HDFS中的in目录
hadoop fs -put /data/data.txt /in
执行hadoop jar命令,在hadoop的/apps/hadoop/share/hadoop/mapreduce路径下存在hadoop-mapreduce-examples-2.6.0-cdh5.4.5.jar包,我们执行其中的worldcount类,数据来源为HDFS的/in目录,数据输出到HDFS的/out目录hadoop jar /apps/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0-cdh5.4.5.jar wordcount /in /out
查看HDFS中的/out目录
hadoop fs -ls /out
hadoop fs -cat /out/*
- 进入Hadoop安全模式
hdfs dfsadmin -safemode enter

- 退出Hadoop安全模式
hdfs dfsadmin -safemode leave

- 切换到/apps/hadoop/sbin目录下,关闭Hadoop
cd /apps/hadoop/sbin ./stop-all.sh
五、实验结论及心得
通过完成本次实验,我熟练掌握了常用的Hadoop Shell命令,并对Hadoop的基本操作有了更深入的了解。
在本次实验中,我学习了如何开启和关闭Hadoop集群。通过使用适当的命令,我能够启动和停止Hadoop服务,确保集群正常运行。
我还学习了如何在Hadoop中创建、修改、查看和删除文件夹及文件。使用命令行界面,我可以轻松地创建新的文件夹和文件,并对它们进行必要的修改和删除操作。
另外,我了解了如何改变文件的权限和文件的拥有者。通过使用适当的命令,我可以为文件设置不同的权限,以控制对文件的访问级别。我还学会了如何更改文件的所有者,以确保适当的文件管理和访问控制。
在本次实验的过程中,我还学习了如何使用Shell命令提交Hadoop作业任务。这使我能够将作业提交到Hadoop集群,并跟踪作业的执行情况。通过这种方式,我可以有效地管理和监控我的作业。
最后,我了解了Hadoop的安全模式,并学会了如何进入和退出安全模式。这对于确保集群的安全性和稳定性非常重要,因为安全模式可以防止对文件系统的意外修改。文章来源:https://www.toymoban.com/news/detail-777542.html
总的来说,通过本次实验,我不仅熟悉了常用的Hadoop Shell命令,还获得了对Hadoop集群管理的实际经验。这将对我的日后工作和学习中的大数据处理任务非常有帮助。文章来源地址https://www.toymoban.com/news/detail-777542.html
到了这里,关于hadoop的基础操作——Hadoop中创建、修改、查看、删除文件夹及文件的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!