初识Spark
Spark和Hadoop
| Hadoop | Spark | |
|---|---|---|
| 起源时间 | 2005 | 2009 |
| 起源地 | MapReduce | University of California Berkeley |
| 数据处理引擎 | Batch | Batch |
| 编程模型 | MapReduce | Resilient distributed Datesets |
| 内存管理 | Disk Based | JVM Managed |
| 延迟 | 高 | 中 |
| 吞吐量 | 中 | 高 |
| 优化机制 | 手动 | 手动 |
| API | Low level | high level |
| 流处理 | NA | Spark Streaming |
| SQL支持 | Hive, Impala | SparkSQL |
| Graph支持 | NA | GraphX |
| 机器学习支持 | NA | SparkML |
Spark对比Hadoop特点
Spark优缺点
-
Spark将运算的中间数据存放在内存, 迭代计算效率更高; 而MapReduce的中间结果需要保存到磁盘 -
Spark容错性更高, 通过弹性分布式数据集RDD来实现高容错; 一部分数据丢失或戳错可以通过数据集的计算过程的血缘关系来实现重建;MapReduce发生错误只能重新计算 -
Spark相比于Hadoop提供了transformation和action这两大类的多功能api, 以及流式处理Spark Streaming模块, 图计算GraphX等等;MapReduce只提供了map和reduce两种操作 -
Spark框架和生态更加复杂, 首先有RDD, 血缘lineage, 执行时的有向无环图DAG/stage划分等, 很多时候都需要根据不同场景分别调优以达到性能要求; 而MapReduce框架及应用较为简单, 但运行较为稳定, 更适合长期稳定运行
Hadoop优缺点
优点:
- 高可靠性:
hadoop可以按位存储和处理数据 - 高扩展性
- 高效性:
Hadoop能够在节点之间动态的移动数据, 并保证各个节点的动态平衡 - 高容错性:
Hadoop能够保存数据的多个副本, 并且能够自动将失败的任务重新分配
缺点:
- 不适合低延迟的数据访问
- 无法高效存储大量小文件
- 不支持多用户写入及任意文件的修改
基本概念

-
Application: 用户编写的Spark应用程序, 包含了driver程序以及集群上运行的程序代码, 物理机器上涉及了driver,master,worker三个节点 -
RDD(Resilient Distributed Dataset): 弹性分布式数据集是Spark中最基本的数据抽象, 代表了一个不可变, 可分区, 可并行计算的集合.RDD具有数据流模型的特点: 自动容错/位置感知性调度/和可伸缩性.RDD允许用户在执行多个查询时显示地将工作集缓存在内存中, 后续的查询能够重用工作机, 这极大地提升了查询速度.RDD包含:- 分片(Partition): 即苏聚集的基本组成功单位, 对于RDD来说, 每个分片都会被一个计算任务吹了, 并决定并行计算的粒度. 用户可以在创建RDD时指定RDD的分片个数, 如果没有指定, 则会采取默认值即分配到的
CPUCore个数 - 分区计算函数:
Spark中RDD的计算是以分片为单位的, 每个RDD都会实现compute函数以达到这个目的. compute函数会对迭代器进行复合, 不需要保存每次计算结果 - 重建: 在部分分区数据丢失时, Spark可以通过这个以来关系重新计算丢失的分区数据, 而不是对RDD的所有分区进行计算
-
Partitioner即RDD的分片函数: 当前Spark中实现了两种类型的分片函数, 一个是基于哈希的HashPartitioner, 另一个是基于范围的RangePartitioner. 只有对于key-value的RDD, 才会有Partitioner - 优先位置(preferedlocation): 对于一个HDFS文件来说, 这个列表保存的就是每个
Partition所在的块的位置, 按住奥"移数据不如移动计算"的理念, Spark在记性任务调度的时候, 会尽可能地讲计算任务分配到其所要处理的块的位置
- 分片(Partition): 即苏聚集的基本组成功单位, 对于RDD来说, 每个分片都会被一个计算任务吹了, 并决定并行计算的粒度. 用户可以在创建RDD时指定RDD的分片个数, 如果没有指定, 则会采取默认值即分配到的
- DAG: 有向无环图
- Task: 被发送到
executor上的工作单元, 每个Task负责一个分区的数据 -
ShuffleMapTask: 输出是shuffle所需的数据, stage的划分也以此为依据, shuffle之前的所有变换是一个stage, shuffle之后的操作是另个一个stage - resultTask: 输出是计算结果
- Job: 一个Job包含多个RDD及作用于RDD上面的各种操作; 他包含多个
task的并行计算, 可以理解为SparkRDD里面的action, 每个action的出发会生成一个job. 用户提交的job会提交给DAGSCheduler; job会被分解为Stage,Stage会被细化乘Task,Task就是每个Partition上的单个数据处理流程 -
Stage: 是job的基本调度单位, 一个Job会分为多组Task, 每组Task被称为一个Stage就行MapStage,ReduceStage,或者也被称为TaskSet, 代表一组关联的, 相互之间没有Shuffle依赖关系的组成的任务集 - Partition: Partition类似hadoop的Split,计算是以partition为单位进行的
- Cluster Manager: 指的是在集群上获取资源的外部服务。主要有三种类型:
- Standalon : spark原生的资源管理,由Master负责资源的分配。
- Apache Mesos:与hadoop MR兼容性良好的一种资源调度框架。
- Hadoop Yarn: 主要是指Yarn中的Resource Manager。
Spark 组成
- Spark Core: Spark核心, 所有核心功能均为Spark提供, Spark Core以RDD为数据抽象, 提供Api, 可以支持海量离线数据批处理计算
- SparkSQL: 基于Spark Core之上, 提供结构化数据的处理模块, 支持以SQL语言对数据的处理, 本身针对离线的计算场景, 同时基于SparkSQL, Spark提供了StructuredStreaming模块, 可以进行数据的流式计算
- SparkStream: 以SparkCore为基础, 提供数据的流式计算功能
- MLLib: 以SparkCore为基础, 进行机器学习计算
- GraphX: 以SparkCore为基础, 进行图计算, 提供了大量图计算相关的Api
Spark运行模式
- 本地模式(单机): 本地模式是以一个独立的进程, 通过多个线程来模拟整个Spark运行的环境
- Standalone模式(集群): Spark中各个角色以独立进程的形式存在, 并组成Spark集群环境
- Hadoop YARN模式(集群): Spark中的各个角色运行在YARN容器内部, 并组成Spark集群环境
- Kubernetes模式(容器集群): Spark中的各个角色运行在Kubernetes容器内部, 并组成Spark环境
Spark架构

- Yarn角色分配:
- 以资源管理层面: ResoureManger, ResoureManager
- 任务计算层面: ApplicationMaster, Task(容器内计算框架的工作角色)
- Spark角色分配:
- Master: 管理集群的资源
-
Worker: 集群中任何一个可以运行spark应用代码的节点.Worker是物理节点, 可以在上面启动Executor进程 分配节点资源 -
Driver:Spark中的Driveer是运行Application的main函数, 并且创建了SparkContext; 创建SparkContext的目的是为了准备Spark应用程序的运行环境. 在Spark中SparkContext负责与Cluster Manager通信, 进行资源申请/任务分配和监控等. 当Excutor部分运行完毕后,Driver同时负责将SparkContext关闭 单个任务的管理 -
Executor: 在每个Worker上为某应用启动的一个进程, 该进程负责运行Task, 并且负责将数据存在内存或磁盘上, 每个任务都有各独立的Executor.Executor是一个执行Task的容器 单个任务的执行
Standalone架构
Standalone模式Spark自带的一种集群模式, 集群由Master和Spark组成. 除了Master和Worker以外, 还可能由HistoryServer, 该进程会在Spark Application运行完成之后, 保存事件日志到HDFS, 启动HistoryServer可以查看应用相关的信息
基本使用
安装 Spark1
wget https://dlcdn.apache.org/spark/spark-3.4.1/spark-3.4.1-bin-hadoop3.tgz
tar -xvf spark-3.4.1-bin-hadoop3.tgz
sudo mv spark-3.4.1-bin-hadoop3 /usr/local/spark
vim ~/.bashrc
export SPARK_HOME="/usr/local/spark"
/usr/local/spark/bin/spark-shell
Spark shell - Spark Jobs (passnight.local)包含Spark访问界面
使用Spark实现WordCount
package com.passnight.bigdata.spark;
import lombok.Cleanup;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import scala.Tuple2;
import java.util.Arrays;
public class WordCount {
public static void main(String[] args) {
SparkConf conf = new SparkConf()
.setAppName("WordCount")
.setMaster("local");
@Cleanup JavaSparkContext context = new JavaSparkContext(conf);
JavaRDD<String> data = context.textFile("hdfs://server.passnight.local/test/word list.txt", 10);
JavaPairRDD<String, Integer> result = data.flatMap(line -> Arrays.stream(line.split(" ")).iterator())
.mapToPair(word -> new Tuple2<>(word, 1)) // 映射成词频
.reduceByKey(Integer::sum) // 聚合词频
// 排序
.mapToPair(Tuple2::swap)
.sortByKey(false)
.mapToPair(Tuple2::swap);
System.out.println("-".repeat(100));
System.out.println(result.collect());
System.out.println("-".repeat(100));
}
}
输出如下(省略了日志)
[(I,4), (like,2), (passnight,2), (love,2), (hadoop,2)]
RDD
RDD基本概念
- 分布式计算需要的机制, RDD是提供这些机制的一个抽象
- 分区控制
- Shuffle控制
- 数据存储/序列化/发送
- 数据计算
- RDD定义:
- Resilient Distributed Dataset(弹性分布式数据集): 是Spark中最基本的数据抽象, 表示一个不可变/可分区/可并行计算的集合, 三个单词分别有以下含义:
- Dataset: 一个数据集合, 用于存放数据
- Distributed: RDD中的数据是分布式存储的, 可用于分布式计算
- Resilient: RDD中的数据可以存储在内存中或者磁盘中
- RDD的数据具有以下特性:
- 不可变: RDD是不可变集合
- 分区性: 数据集合被划分为多个部分, 每个部分被称为分区 对于KV型数据可以有分区器; 且数据读取会尽量靠近数据所在地(移动计算而非数据); 分区是RDD的最小存储单位
- 并行性: 计算方法是并行的, 计算方法会作用在每个分区上
- 依赖性: RDD之间具有相互依赖的关系 RDD有血缘关系
- RDD在WordCount中的数据流:

RDD创建
RDD可以通过读取文件或集合创建rdd
package com.passnight.bigdata.spark;
import lombok.Cleanup;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import java.util.Arrays;
public class RDDCreation {
public static void main(String[] args) {
SparkConf conf = new SparkConf()
.setAppName("WordCount")
.setMaster("local[*]");
@Cleanup JavaSparkContext context = new JavaSparkContext(conf);
// 通过并行化的方式创建RDD, 默认分区数为核心数
JavaRDD<Integer> rdd = context.parallelize(Arrays.asList(1, 2, 3, 4, 5, 6, 7, 8, 9), 3);
System.out.println("-".repeat(100));
System.out.println(rdd.collect());
System.out.println("-".repeat(100));
// 也可以通过本地文件创建; 这里的最小分区数是参考值, 而非强制值
JavaRDD<String> rdd1 = context.textFile("bigdata/src/main/resources/word list.txt", 100);
System.out.println("-".repeat(100));
System.out.println(rdd1.getNumPartitions());
System.out.println("-".repeat(100));
System.out.println(rdd1.collect());
System.out.println("-".repeat(100));
// 从hdfs读取文件
JavaRDD<String> rdd2 = context.textFile("hdfs://server.passnight.local/test/word list.txt");
System.out.println("-".repeat(100));
System.out.println(rdd2.getNumPartitions());
System.out.println("-".repeat(100));
System.out.println(rdd2.collect());
System.out.println("-".repeat(100));
}
// 读取多个小文件
JavaPairRDD<String, String> rdd3 = context.wholeTextFiles("bigdata/src/main/resources");
System.out.println("-".repeat(100));
System.out.println(rdd3.getNumPartitions());
System.out.println("-".repeat(100));
System.out.println(rdd3.collect());
System.out.println("-".repeat(100));
}
输出为:
# 这里省略了日志和分隔符
[1, 2, 3, 4, 5, 6, 7, 8, 9]
61
[I love passnight, I like passnight, I love hadoop, I like hadoop]
2
[I love passnight, I like passnight, I love hadoop, I like hadoop]
[(file:/************/bigdata/src/main/resources/word list.txt,I love passnight
I like passnight #......................
Transformation算子
- Transformation算子: 返回值仍是一个RDD的算子 这类算子是lazy加载的, 如果没有action算子, 这类算子是不工作的; 如
flatMap是一类典型的Transformation算子 - Action算子: 返回值不是RDD的算子 例如
collect
map算子
功能: map算子, 是将RDD中的数字逐条处理, 返回新的RDD
class Map {
public static void main(String[] args) {
@Cleanup JavaSparkContext context = new JavaSparkContext(new SparkConf()
.setAppName("Map")
.setMaster("local[*]"));
List<Integer> rdd = context.parallelize(IntStream.range(0, 10).boxed().collect(Collectors.toList()), 3)
.map(i -> i * 10)
.collect();
System.out.printf("计算结果:%n %s%n", rdd);
}
}
输出为:
计算结果:
[0, 10, 20, 30, 40, 50, 60, 70, 80, 90]
flatMap算子
功能: 先对rdd进行map操作, 再摊平嵌套
class FlatMap {
public static void main(String[] args) {
@Cleanup JavaSparkContext context = new JavaSparkContext(new SparkConf()
.setAppName("FlatMap")
.setMaster("local[*]"));
List<String> rdd = context.parallelize(Arrays.asList("1 2 3", "4 5 6", "7 8 9"), 3)
.flatMap(line -> Arrays.stream(line.split(" ")).iterator())
.collect();
System.out.printf("计算结果:%n %s%n", rdd);
}
}
输出为:
计算结果:
[1, 2, 3, 4, 5, 6, 7, 8, 9]
可以看到多个数组被摊平为一个数组
reduceByKey算子
功能: 针对KV型RDD, 先对key进行分组, 然后根据提供的聚合逻辑, 完成组内数据的聚合操作
class ReduceByKey {
public static void main(String[] args) {
@Cleanup
JavaSparkContext context = new JavaSparkContext(new SparkConf()
.setAppName("ReduceByKey")
.setMaster("local[*]"));
List<Tuple2<String, Integer>> rdd = context.parallelizePairs(Stream.of(1, 1, 1, 2, 2, 2, 3, 4, 4, 3, 10)
.map(i -> new Tuple2<>(String.format("值: %d", i), i))
.collect(Collectors.toList()), 3)
.reduceByKey(Integer::sum)
.collect();
System.out.printf("计算结果:%n %s%n", rdd);
}
}
输出结果为:
计算结果:
[(值: 4,8), (值: 1,3), (值: 2,6), (值: 10,10), (值: 3,6)]
可以看到不同值被分组, 然后进行求和
mapToValues算子
功能: 针对二元元组RDD, 对其内部的Value进行map操作
class MapToValues {
public static void main(String[] args) {
@Cleanup
JavaSparkContext context = new JavaSparkContext(new SparkConf()
.setAppName("MapToValues")
.setMaster("local[*]"));
List<Tuple2<String, Integer>> rdd = context.parallelizePairs(Stream.of(1, 1, 1, 2, 2, 2, 3, 4, 4, 3, 10)
.map(i -> new Tuple2<>(String.format("值: %d", i), i))
.collect(Collectors.toList()), 3)
.mapValues(i -> i * 10)
.collect();
System.out.printf("计算结果:%n %s%n", rdd);
}
}
输出结果为:
计算结果:
[(值: 1,10), (值: 1,10), (值: 1,10), (值: 2,20), (值: 2,20), (值: 2,20), (值: 3,30), (值: 4,40), (值: 4,40), (值: 3,30), (值: 10,100)]
可以看到只有值发生了变化, 且变为了原来的10倍
groupBy算子
功能: 将RDD的数据进行分组
class GroupBy {
public static void main(String[] args) {
@Cleanup JavaSparkContext context = new JavaSparkContext(new SparkConf()
.setAppName("GroupBy")
.setMaster("local[*]"));
List<Tuple2<String, Iterable<Tuple2<String, Integer>>>> rdd = context.parallelizePairs(Arrays.asList(
Tuple2.apply("a", 1), Tuple2.apply("b", 2), Tuple2.apply("b", 1), Tuple2.apply("a", 3), Tuple2.apply("c", 1)
), 3)
.groupBy(Tuple2::_1)
.collect();
System.out.printf("计算结果:%n %s%n", rdd);
}
}
输出结果为:
计算结果:
[(c,[(c,1)]), (a,[(a,1), (a,3)]), (b,[(b,2), (b,1)])]
可以看到已经根据key分组了
ffilter算子
功能: 过滤符合条件的数据
class Filter {
public static void main(String[] args) {
@Cleanup JavaSparkContext context = new JavaSparkContext(new SparkConf()
.setAppName("Filter")
.setMaster("local[*]"));
List<Integer> rdd = context.parallelize(IntStream.range(0, 10).boxed().collect(Collectors.toList()), 3)
.filter(i -> i % 2 == 0)
.collect();
System.out.printf("计算结果:%n %s%n", rdd);
}
}
输出结果为:
计算结果:
[0, 2, 4, 6, 8]
可以看到已将偶数都过滤出来了
distinct算子
功能: 将rdd数据去重
class Distinct {
public static void main(String[] args) {
@Cleanup JavaSparkContext context = new JavaSparkContext(new SparkConf()
.setAppName("Distinct")
.setMaster("local[*]"));
List<Integer> rdd = context.parallelize(Arrays.asList(1, 1, 1, 2, 2, 2, 3, 3, 3), 3)
.distinct(2)
.collect();
System.out.printf("计算结果:%n %s%n", rdd);
List<Tuple2<String, Integer>> rdd2 = context.parallelizePairs(Arrays.asList(Tuple2.apply("a", 1),
Tuple2.apply("b", 1), Tuple2.apply("b", 1),
Tuple2.apply("a", 3), Tuple2.apply("a", 1)), 3)
.distinct(2)
.collect();
System.out.printf("计算结果:%n %s%n", rdd2);
}
}
输出结果为:
计算结果:
[2, 1, 3]
计算结果:
[(a,1), (a,3), (b,1)]
可以看到无论是KV型数据还是普通的数据, 都已经去重了
union算子
功能: 将两个rdd合并成一个rdd
class Union {
public static void main(String[] args) {
@Cleanup JavaSparkContext context = new JavaSparkContext(new SparkConf()
.setAppName("Union")
.setMaster("local[*]"));
JavaRDD<Object> rdd1 = context.parallelize(IntStream.range(0, 4).boxed().collect(Collectors.toList()), 3);
JavaRDD<Object> rdd2 = context.parallelize(IntStream.range(2, 7).boxed().collect(Collectors.toList()), 3);
JavaRDD<Object> rdd3 = context.parallelize(IntStream.range(7, 10).boxed().map(String::valueOf).collect(Collectors.toList()), 3);
List<Object> rdd = rdd1.union(rdd2)
.union(rdd2)
.union(rdd3)
.collect();
System.out.printf("计算结果:%n %s%n", rdd);
}
}
输出结果为:
计算结果:
[0, 1, 2, 3, 2, 3, 4, 5, 6, 2, 3, 4, 5, 6, 7, 8, 9]
可以看到可以合并数据类型, 合并也不会进行去重操作
join算子
功能: 对两个RDD执行join操作, 可以实现SQL的内连接/外连接
class Join {
public static void main(String[] args) {
@Cleanup JavaSparkContext context = new JavaSparkContext(new SparkConf()
.setAppName("Join")
.setMaster("local[*]"));
JavaPairRDD<Integer, String> rdd1 = context.parallelizePairs(Arrays.asList(
Tuple2.apply(1, "张三"), Tuple2.apply(2, "李四"),
Tuple2.apply(3, "王五"), Tuple2.apply(4, "赵六")
), 3);
JavaPairRDD<Integer, String> rdd2 = context.parallelizePairs(Arrays.asList(
Tuple2.apply(1, "生产部"), Tuple2.apply(2, "销售部")
), 3);
// 默认按照两个rdd的key进行关联, 不像sql无需用on添加条件
List<Tuple2<Integer, Tuple2<String, String>>> join = rdd1.join(rdd2)
.collect();
List<Tuple2<Integer, Tuple2<String, Optional<String>>>> leftOuterJoin = rdd1.leftOuterJoin(rdd2)
.collect();
System.out.printf("计算结果(join):%n %s%n", join);
System.out.printf("计算结果(leftOuterJoin):%n %s%n", leftOuterJoin);
}
}
输出结果为:
计算结果(join):
[(1,(张三,生产部)), (2,(李四,销售部))]
计算结果(leftOuterJoin):
[(3,(王五,Optional.empty)), (4,(赵六,Optional.empty)), (1,(张三,Optional[生产部])), (2,(李四,Optional[销售部]))]
可以看到两个元组集合根据key关联在一起了, 左外连接保留了在右侧没有对应key的元组
intersection算子
功能: 求两个rdd的交集, 并返回一个rdd
class Intersection {
public static void main(String[] args) {
@Cleanup JavaSparkContext context = new JavaSparkContext(new SparkConf()
.setAppName("Intersection")
.setMaster("local[*]"));
JavaRDD<Integer> rdd1 = context.parallelize(IntStream.range(0, 8).boxed().collect(Collectors.toList()), 3);
JavaRDD<Integer> rdd2 = context.parallelize(IntStream.range(5, 7).boxed().collect(Collectors.toList()), 3);
List<Integer> rdd = rdd1.intersection(rdd2)
.collect();
System.out.printf("计算结果:%n %s%n", rdd);
}
}
输出结果为
计算结果:
[6, 5]
可以看到只有在两个集合中都存在的才被输出
glom算子
功能: 将RDD的数据按照分区加上嵌套
class Glom {
public static void main(String[] args) {
@Cleanup JavaSparkContext context = new JavaSparkContext(new SparkConf()
.setAppName("Glom")
.setMaster("local[*]"));
List<List<Integer>> rdd1 = context.parallelize(IntStream.range(0, 10)
.boxed()
.collect(Collectors.toList()), 3)
.glom()
.collect();
System.out.printf("计算结果:%n %s%n", rdd1);
List<List<Integer>> rdd2 = context.parallelize(IntStream.range(0, 10)
.boxed()
.collect(Collectors.toList()), 2)
.glom()
.collect();
System.out.printf("计算结果:%n %s%n", rdd2);
}
}
输出结果为:
计算结果:
[[0, 1, 2], [3, 4, 5], [6, 7, 8, 9]]
计算结果:
[[0, 1, 2, 3, 4], [5, 6, 7, 8, 9]]
可以看到分区数和numSlices参数相对应
groupByKey算子
功能: 针对KV型RDD, 自动按照Key分组
class GroupByKey {
public static void main(String[] args) {
@Cleanup
JavaSparkContext context = new JavaSparkContext(new SparkConf()
.setAppName("GroupByKey")
.setMaster("local[*]"));
List<Tuple2<String, Iterable<Integer>>> rdd = context.parallelizePairs(Stream.of(1, 1, 1, 2, 2, 2, 3, 4, 4, 3, 10)
.map(i -> new Tuple2<>(String.format("值: %d", i), i))
.collect(Collectors.toList()), 3)
.groupByKey()
.collect();
System.out.printf("计算结果:%n %s%n", rdd);
}
}
输出结果为
计算结果:
[(值: 4,[4, 4]), (值: 1,[1, 1, 1]), (值: 2,[2, 2, 2]), (值: 10,[10]), (值: 3,[3, 3])]
可以看到已经根据key进行分组了
sortBy算子
功能: 根据输入的函数, 对RDD进行排序
class SortBy {
public static void main(String[] args) {
@Cleanup
JavaSparkContext context = new JavaSparkContext(new SparkConf()
.setAppName("SortBy")
.setMaster("local[*]"));
List<Tuple2<String, Integer>> rdd = context.parallelize(new Random().ints(1, 100)
.boxed()
.map(integer -> Tuple2.apply(String.format("值(%d)",integer), integer))
.limit(10)
.collect(Collectors.toList()), 3)
// 若要全局有序, Partition只能设置为1, 否则只能保证分区内局部有序
.sortBy(Tuple2::_2, true, 1)
.collect();
System.out.printf("计算结果:%n %s%n", rdd);
}
}
输出结果为:
计算结果:
[(值(13),13), (值(15),15), (值(21),21), (值(46),46), (值(52),52), (值(55),55), (值(55),55), (值(66),66), (值(87),87), (值(90),90)]
可以看到已经根据元组的第二个元素排序了
sortByKey算子
功能: 针对KV型RDD, 按照Key进行排序
class SortByKey {
public static void main(String[] args) {
@Cleanup
JavaSparkContext context = new JavaSparkContext(new SparkConf()
.setAppName("SortByKey")
.setMaster("local[*]"));
List<Tuple2<String, Integer>> rdd = context.parallelizePairs(new Random().ints(1, 100)
.boxed()
.map(integer -> Tuple2.apply(String.format("值(%d)", integer), integer))
.limit(10)
.collect(Collectors.toList()), 3)
.sortByKey(true, 1)
.collect();
System.out.printf("计算结果:%n %s%n", rdd);
}
}
输出结果为:
计算结果:
[(值(11),11), (值(25),25), (值(45),45), (值(63),63), (值(64),64), (值(65),65), (值(71),71), (值(77),77), (值(79),79), (值(98),98)]
可以看到结果已经根据key排序了
Action算子
countByKey算子
功能: 统计key出现的次数, 这个算子是
class CountByKey {
public static void main(String[] args) {
@Cleanup
JavaSparkContext context = new JavaSparkContext(new SparkConf()
.setAppName("CountByKey")
.setMaster("local[*]"));
java.util.Map<String, Long> rdd = context.parallelizePairs(Stream.of(1, 1, 1, 2, 2, 2, 3, 4, 4, 3, 10)
.map(i -> new Tuple2<>(String.format("值: %d", i), i))
.collect(Collectors.toList()))
.countByKey();
System.out.printf("计算结果:%n %s%n", rdd);
}
}
输出结果为:
计算结果:
{值: 2=3, 值: 4=2, 值: 3=2, 值: 10=1, 值: 1=3}
可以看到已经根据Key进行计数了
collect算子
功能: 将RDD各个分区内的数据, 统一手机到一个Driver中, 形成一个List对象
class Collect {
public static void main(String[] args) {
@Cleanup JavaSparkContext context = new JavaSparkContext(new SparkConf()
.setAppName("Collect")
.setMaster("local[*]"));
List<Integer> rdd = context.parallelize(IntStream.range(0, 10)
.boxed()
.collect(Collectors.toList()), 3)
.collect(); // 注意使用这个算子, 要确认结果集不会太大, 否则可能会导致Driver OOM
System.out.printf("计算结果:%n %s%n", rdd);
}
}
输出结果为:
计算结果:
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
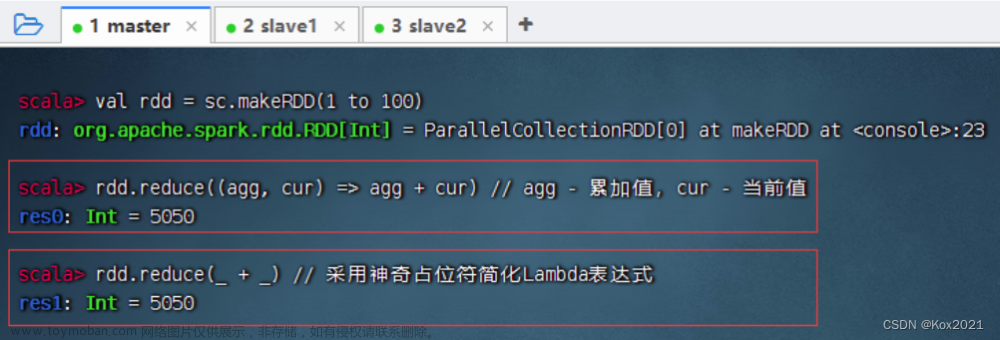
reduce算子:
功能: 根据传入的逻辑进行聚合
class Reduce {
public static void main(String[] args) {
@Cleanup JavaSparkContext context = new JavaSparkContext(new SparkConf()
.setAppName("Reduce")
.setMaster("local[*]"));
Integer result = context.parallelize(IntStream.range(0, 10)
.boxed()
.collect(Collectors.toList()), 3)
.reduce(Integer::sum);
System.out.printf("计算结果:%n %s%n", result);
}
}
输出结果值为:
计算结果:
45
可以看到成功实现求和
flod算子
功能: 相当于有初始值的聚合, 每个分区内都会有一个初始值, 且分区间聚合也有该初始值
class Fold {
public static void main(String[] args) {
@Cleanup JavaSparkContext context = new JavaSparkContext(new SparkConf()
.setAppName("Collect")
.setMaster("local[*]"));
Integer result = context.parallelize(IntStream.range(0, 10)
.boxed()
.collect(Collectors.toList()), 3)
.reduce(Integer::sum);
System.out.printf("计算结果:%n %s%n", result);
}
}
输出结果为:
计算结果:
85
三个分区聚合引入三个初始值, 因此三个分区聚合后的结果为[16, 25, 34], 它们再聚合, 并添加10作为初始值, 最后的结果为
10
+
16
+
25
+
34
=
85
10 + 16 + 25 + 34 = 85
10+16+25+34=85
first算子
功能: 取出rd的第一个元素
class First {
public static void main(String[] args) {
@Cleanup JavaSparkContext context = new JavaSparkContext(new SparkConf()
.setAppName("First")
.setMaster("local[*]"));
Integer result = context.parallelize(IntStream.range(0, 10)
.boxed()
.collect(Collectors.toList()), 3)
.first();
System.out.printf("计算结果:%n %s%n", result);
}
}
输出结果为:
计算结果:
0
可以看到去除第一个元素
top算子
功能: 对RDD结果集降序排序, 取前N个
class Top {
public static void main(String[] args) {
@Cleanup JavaSparkContext context = new JavaSparkContext(new SparkConf()
.setAppName("Top")
.setMaster("local[*]"));
List<Integer> top3 = context.parallelize(IntStream.range(0, 10)
.boxed()
.collect(Collectors.collectingAndThen(Collectors.toList(), (list) -> {
Collections.shuffle(list);
return list;
})), 3)
.top(3);
System.out.printf("计算结果:%n %s%n", top3);
}
}
输出结果为:
计算结果:
[9, 8, 7]
count算子
功能: 返回RDD的数据数
class Count {
public static void main(String[] args) {
@Cleanup JavaSparkContext context = new JavaSparkContext(new SparkConf()
.setAppName("Count")
.setMaster("local[*]"));
long count = context.parallelize(IntStream.range(0, 10)
.boxed()
.collect(Collectors.toList()), 3)
.count();
System.out.printf("计算结果:%n %s%n", count);
}
}
输出结果为:
计算结果:
10
takeSample算子
功能: 随机抽样RDD的数据
class TakeSample {
public static void main(String[] args) {
@Cleanup JavaSparkContext context = new JavaSparkContext(new SparkConf()
.setAppName("TakeSample")
.setMaster("local[*]"));
List<Integer> sample = context.parallelize(IntStream.range(0, 10)
.boxed()
.collect(Collectors.toList()), 3)
.takeSample(true, 3);
System.out.printf("计算结果:%n %s%n", sample);
}
}
输出结果为:
计算结果:
[5, 4, 9]
可以看到随机取了三个rd中的元素
takeOrderd算子
功能: 对RDD进行排序后取前N个 相比于top, 可以制定排序方法
class TakeOrdered {
public static void main(String[] args) {
@Cleanup JavaSparkContext context = new JavaSparkContext(new SparkConf()
.setAppName("TakeOrdered")
.setMaster("local[*]"));
List<Integer> sample = context.parallelize(IntStream.range(0, 10)
.boxed()
.collect(Collectors.collectingAndThen(Collectors.toList(), list -> {
Collections.shuffle(list);
return list;
})), 3)
.takeOrdered(3);
System.out.printf("计算结果:%n %s%n", sample);
}
}
输出结果为:
计算结果:
[0, 1, 2]
forEach算子
功能: 对rdd的每个元素执行所提供的操作, 但相比于map, 没有返回值 注意forEach是直接由executor执行的, 其他的算子是由Driver输出的
class ForEach {
public static void main(String[] args) {
@Cleanup JavaSparkContext context = new JavaSparkContext(new SparkConf()
.setAppName("ForEach")
.setMaster("local[*]"));
context.parallelize(IntStream.range(0, 10).boxed().collect(Collectors.toList()), 3)
.foreach(System.out::println);
}
}
输出结果为:
值: 0|值: 3|值: 6|值: 7|值: 4|值: 5|值: 1|值: 2|值: 8|值: 9|
saveAsTextFile算子
功能: 将数据结果写入到文件当中, 这个任务是由Executor执行的 支持本地文件系统, 也支持hdfs; 因为是由Executor执行的, 所以每个分区都会写一部分
class SaveAsTextFile implements Serializable {
public static void main(String[] args) {
@Cleanup JavaSparkContext context = new JavaSparkContext(new SparkConf()
.setAppName("SaveAsTextFile")
.setMaster("local[*]"));
context.parallelize(IntStream.range(0, 10)
.boxed()
.collect(Collectors.toList()), 3)
.saveAsTextFile("result");
}
}
可以看到结果成功写入到文件当中了 , 且结果的文件数量和分区数量相同
passnight@passnight-s600:~/project/note/spring/result$ ll
total 36
drwxr-xr-x 2 passnight passnight 4096 11月 4 14:34 ./
drwxrwxr-x 15 passnight passnight 4096 11月 4 14:34 ../
-rw-r--r-- 1 passnight passnight 6 11月 4 14:34 part-00000
-rw-r--r-- 1 passnight passnight 12 11月 4 14:34 .part-00000.crc
-rw-r--r-- 1 passnight passnight 6 11月 4 14:34 part-00001
-rw-r--r-- 1 passnight passnight 12 11月 4 14:34 .part-00001.crc
-rw-r--r-- 1 passnight passnight 8 11月 4 14:34 part-00002
-rw-r--r-- 1 passnight passnight 12 11月 4 14:34 .part-00002.crc
-rw-r--r-- 1 passnight passnight 0 11月 4 14:34 _SUCCESS
-rw-r--r-- 1 passnight passnight 8 11月 4 14:34 ._SUCCESS.crc
分区操作算子
mapPartitions算子
功能: 同map一样, 但一次操作一整个分区的数据 这样可以极大减少网络io次数
class MapPartitions {
public static void main(String[] args) {
@Cleanup JavaSparkContext context = new JavaSparkContext(new SparkConf()
.setAppName("MapPartitions")
.setMaster("local[*]"));
List<Integer> rdd = context.parallelize(IntStream.range(0, 10).boxed().collect(Collectors.toList()), 3)
.mapPartitions(integerIterator -> StreamSupport.stream(Spliterators.spliteratorUnknownSize(integerIterator, 0), false)
.map(integer -> integer * 10)
.iterator())
.collect();
System.out.printf("计算结果:%n %s%n", rdd);
}
}
输出结果为:
计算结果:
[0, 10, 20, 30, 40, 50, 60, 70, 80, 90]
可以看到所有元素的值都变为了原来的10倍
foreachPartitions算子
功能: 同forEach一样, 但一次操作整个分区的数据
class ForeachPartitions {
public static void main(String[] args) {
@Cleanup JavaSparkContext context = new JavaSparkContext(new SparkConf()
.setAppName("ForeachPartitions")
.setMaster("local[*]"));
context.parallelize(IntStream.range(0, 10).boxed().collect(Collectors.toList()), 3)
.mapPartitions(integerIterator -> Stream.generate(integerIterator::next)
.map(integer -> integer * 10)
.iterator())
.foreachPartition(it -> System.out.printf("值: %s|", it));
}
}
输出结果为:
值: java.util.Spliterators$1Adapter@8c66b7c|值: java.util.Spliterators$1Adapter@6e74b18e|值: java.util.Spliterators$1Adapter@6cb5e424|
partitionBy算子
功能: 对RDD进行自定义分区操作
class PartitionBy {
public static void main(String[] args) {
@Cleanup
JavaSparkContext context = new JavaSparkContext(new SparkConf()
.setAppName("PartitionBy")
.setMaster("local[*]"));
List<List<Tuple2<Integer, String>>> rdd = context.parallelizePairs(Stream.of(1, 1, 1, 2, 2, 2, 3, 4, 4, 3, 10)
.map(i -> new Tuple2<>(i, String.format("值: %d", i)))
.collect(Collectors.toList()))
.partitionBy(new Partitioner() {
@Override
public int numPartitions() {
return 2;
}
@Override
public int getPartition(Object key) {
assert key instanceof Integer;
Integer k = (Integer) key;
return k > 3 ? 1 : 0;
}
}).glom()
.collect();
System.out.printf("计算结果:%n %s%n", rdd);
}
}
输出结果为:
计算结果:
[[(1,值: 1), (1,值: 1), (1,值: 1), (2,值: 2), (2,值: 2), (2,值: 2), (3,值: 3), (3,值: 3)], [(4,值: 4), (4,值: 4), (10,值: 10)]]
可以看到大于3和小于3的分为了两组
repartition算子
功能: 改变分区的数量 注意添加分区可能会导致shuffle, 进而影响到性能, 因此尽量不要改变分区大小, 更不要增大分区
class Repartition {
public static void main(String[] args) {
@Cleanup JavaSparkContext context = new JavaSparkContext(new SparkConf()
.setAppName("Repartition")
.setMaster("local[*]"));
List<List<Integer>> rdd1 = context.parallelize(IntStream.range(0, 10)
.boxed()
.collect(Collectors.toList()), 3)
.glom()
.collect();
System.out.printf("计算结果:%n %s%n", rdd1);
List<List<Integer>> rdd2 = context.parallelize(IntStream.range(0, 10)
.boxed()
.collect(Collectors.toList()), 2)
.repartition(5)
.glom()
.collect();
System.out.printf("计算结果:%n %s%n", rdd2);
List<List<Integer>> rdd3 = context.parallelize(IntStream.range(0, 10)
.boxed()
.collect(Collectors.toList()), 2)
.repartition(1)
.glom()
.collect();
System.out.printf("计算结果:%n %s%n", rdd3);
}
}
输出结果为:
计算结果:
[[0, 1, 2], [3, 4, 5], [6, 7, 8, 9]]
计算结果:
[[1, 6], [2, 7], [3, 8], [4, 9], [0, 5]]
计算结果:
[[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]]
colalesce算子
功能: 修改分区大小 同repartition相比, 它有一个安全机制, 需要打开shuffle才能增加分区
class Coalesce {
public static void main(String[] args) {
@Cleanup JavaSparkContext context = new JavaSparkContext(new SparkConf()
.setAppName("Coalesce")
.setMaster("local[*]"));
List<List<Integer>> rdd1 = context.parallelize(IntStream.range(0, 10)
.boxed()
.collect(Collectors.toList()), 3)
.glom()
.collect();
System.out.printf("计算结果:%n %s%n", rdd1);
List<List<Integer>> rdd2 = context.parallelize(IntStream.range(0, 10)
.boxed()
.collect(Collectors.toList()), 2)
.coalesce(5)
.glom()
.collect();
System.out.printf("计算结果:%n %s%n", rdd2);
List<List<Integer>> rdd3 = context.parallelize(IntStream.range(0, 10)
.boxed()
.collect(Collectors.toList()), 2)
.coalesce(1)
.glom()
.collect();
System.out.printf("计算结果:%n %s%n", rdd3);
}
}
输出结果为:
计算结果:
[[0, 1, 2], [3, 4, 5], [6, 7, 8, 9]]
计算结果:
[[0, 1, 2, 3, 4], [5, 6, 7, 8, 9]]
计算结果:
[[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]]
RDD持久化
缓存
- rdd之间的血缘关系
- rdd之间相互迭代计算, 通过老的rdd计算生成rdd, 新的rdd生成之后老的rdd会被释放以节约内存空间
- rdd持久化技术
- 新的rdd生成后老的rdd会被释放, 而倘若一个rdd会被使用多次, 这样就要重新计算, 此时可以通过将其持久化到磁盘上来节约计算资源
- Spark中可以通过
cache方法将其缓存到内存中, 和persist将其持久化到磁盘上 persist也可以只持久化到内存或多个内存副本中 - 可以通过
unpresisit来主动清理缓存
下面是一个例子, rdd1和rdd2会被使用两次
public class RddCache {
@SneakyThrows
public static void main(String[] args) {
@Cleanup JavaSparkContext context = new JavaSparkContext(new SparkConf()
.setAppName("Distinct")
.setMaster("local[*]"));
JavaRDD<Integer> rdd1 = context.parallelize(IntStream.range(0, 10).boxed().collect(Collectors.toList()));
JavaRDD<Integer> rdd2 = rdd1.map(x -> x * 10);
rdd2.cache(); // 将rdd保存下来
JavaRDD<String> rdd3 = rdd2.map(String::valueOf);
Integer sum = rdd2.reduce(Integer::sum);
String expression = rdd3.reduce(String::concat);
System.out.printf("计算结果:%n %s%n", sum);
System.out.printf("计算结果:%n %s%n", expression);
TimeUnit.DAYS.sleep(1);
}
}
在管理界面, 可以看到DAG图:


由图可知rdd1和rdd2被计算了2次; 在将rdd缓存下来之后, rdd1和rdd2就只被计算了1次


CheckPoint
- CheckPoint技术类似cache一样, 也是将RDD的数据保存起来, 但只支持硬盘存储.
- CheckPoint 在设计上被认为是安全的, 因此不会保留血缘关系 保留血缘关系在丢失后可以重新计算
- CheckPoint存储RDD是集中存储的, 不像Cache是分散存储的 例如将CheckPoint存储到HDFS, 并由HDFS保证其完整性
class CheckPoint {
@SneakyThrows
public static void main(String[] args) {
@Cleanup JavaSparkContext context = new JavaSparkContext(new SparkConf()
.setAppName("CheckPoint")
.setMaster("local[*]"));
context.setCheckpointDir("checkpoint");
JavaRDD<Integer> rdd1 = context.parallelize(IntStream.range(0, 10).boxed().collect(Collectors.toList()));
JavaRDD<Integer> rdd2 = rdd1.map(x -> x * 10);
rdd2.checkpoint();
JavaRDD<String> rdd3 = rdd2.map(String::valueOf);
Integer sum = rdd2.reduce(Integer::sum);
String expression = rdd3.reduce(String::concat);
System.out.printf("计算结果:%n %s%n", sum);
System.out.printf("计算结果:%n %s%n", expression);
TimeUnit.DAYS.sleep(1);
}
}
可以看到rdd2被缓存下来了

并且任务2直接从CheckPoint开始执行

共享变量
广播变量

- 假设一个变量需要被多个分区使用, 可以将该变量标记为广播变量
- 若两个分区处于同一个进程, 分区二在请求共享变量的时候, 会被通知可以从同进程的其他线程中获取
广播变量的使用
class Broadcast {
public static void main(String[] args) {
@Cleanup JavaSparkContext context = new JavaSparkContext(new SparkConf()
.setAppName("Distinct")
.setMaster("local[*]"));
Map<Integer, String> nameMap = Map.of(3, "张三", 4, "李四", 5, "王五", 6, "赵六");
List<Tuple3<Integer, String, Integer>> scoreMap = Arrays.asList(
Tuple3.apply(3, "语文", 100),
Tuple3.apply(3, "数学", 100),
Tuple3.apply(4, "语文", 100),
Tuple3.apply(4, "数学", 100),
Tuple3.apply(5, "语文", 100),
Tuple3.apply(5, "数学", 100),
Tuple3.apply(5, "英语", 100),
Tuple3.apply(4, "英语", 100),
Tuple3.apply(3, "英语", 100)
);
org.apache.spark.broadcast.Broadcast<Map<Integer, String>> broadcastNameMap = context.broadcast(nameMap);
System.out.printf("计算结果:%n %s%n", context.parallelize(scoreMap)
.map(tuple -> Tuple3.apply(nameMap.get(tuple._1()), tuple._2(), tuple._3()))
.collect());
System.out.printf("计算结果:%n %s%n", context.parallelize(scoreMap)
.map(tuple -> Tuple3.apply(broadcastNameMap.getValue().get(tuple._1()), tuple._2(), tuple._3()))
.collect());
}
}
- 以上面的例子为例,
broadcast可以将变量封装为广播变量; 这样就可以节约部分情况下变量的传播 - 使用广播变量而不使用RDD的原因在于: 使用RDD可能会导致shuffle, 进而使得性能降低 上例中, 假设不是Map而是遍历list找到到对应的key的话, 遍历过程rdd的每个元素都要一次网络io; 广播变量可以一次性传输全量io
累加器
假设要累加分布式对象的数量, 若没有变量共享, 每个分区都会有一个累加器, 进而导致累加的数量少于实际的数量, 下面是一个累加器的例子
class Accumulator {
public static void main(String[] args) {
@Cleanup JavaSparkContext context = new JavaSparkContext(new SparkConf()
.setAppName("Accumulator")
.setMaster("local[*]"));
AtomicLong count = new AtomicLong(0); // 不适用累加器
context.parallelize(IntStream.range(0, 10).boxed()
.collect(Collectors.toList()), 3)
.map(x -> {
count.incrementAndGet();
System.out.println("计算过程: " + count.get());
return x;
}).collect();
System.out.printf("计算结果:%n %s%n", count.get());
LongAccumulator countAccumulator = context.sc().longAccumulator();// 累加器
context.parallelize(IntStream.range(0, 10).boxed()
.collect(Collectors.toList()), 3)
.map(x -> {
countAccumulator.add(1);
System.out.println("累加器计算过程: " + countAccumulator.value());
return x;
}).collect();
System.out.printf("累加器计算结果:%n %s%n", countAccumulator.value());
}
}
输出结果为:
计算过程: 1
计算过程: 1
计算过程: 1
计算过程: 2
计算过程: 2
计算过程: 3
计算过程: 2
计算过程: 3
计算过程: 3
计算过程: 4
计算结果:
0
累加器计算过程: 1
累加器计算过程: 2
累加器计算过程: 3
累加器计算过程: 1
累加器计算过程: 2
累加器计算过程: 3
累加器计算过程: 4
累加器计算过程: 1
累加器计算过程: 2
累加器计算过程: 3
累加器计算结果:
10
可以看到每个分区都有一份累加器的拷贝(Executor的拷贝), 并且结算结果是单独的一份拷贝(Driver的拷贝) 传递是值传递, 而非引用传递, 分布式环境下也无法实现引用传递; 但是如果使用Accumulator的话, 尽管各个分区都是值传递, 但是最后累加的结果会作用在Drive的父拷贝上 注意, 多一个rdd被创创建多次, 会导致accumulator被执行多次, 可以使用cache解决这个问题
Spark Scheduler
- Spark的计算调度是Spark Scheduler完成的, 而任务的调度又先后关系, 基于这些关系形成的DAG划分Stage, 调度中Spark Scheduler将每个任务发到指定的节点运行
- 基本概念
-
Action: 流水线的开关, 只有执行了Action算子, 前面的Transformation算子才会开始执行
-
Job: 任务, 一个Action会产生一个job
-
DAG: 有向无环图, 这里特指RDD间血缘关系形成的有向无环图 在运行时, 会生成带有分区关系的DAG
-
宽依赖: 父RDD的一个分区, 将数据发给子RDD的多个分区 此过程也被成为shuffle
-
窄依赖: 父RDD的一份分区, 全部将数据发送给子RDD的一个分区
-
如下图所示,所有都是窄依赖 子节点接受多个父节点也属于窄依赖

-
该图所有的情况都是宽依赖 可以看到所有的RDD都存在分叉

-
Stage: stage是通过宽依赖划分的, 一个宽依赖会划分出一个新的Stage, 因此Stage内部一定是窄依赖
-
内存迭代计算

- Spark调度器会根据DAG, 按照宽窄以来划分DAG阶段
- Spark调度器会尽量将窄依赖划分为一个任务, 这样可以减少网络交互IO
- 如下图, Task1-Task3都可以在一个分区上完成计算, 因此Spark可以将这些算子调度在同一个内存计算管道
- 倘若Task3-Task6都在Executor上, 他们之间的数据交互也是通过内存 底层是本地回环网络
Spark并行度
- 定义: 同一时间内, 同时运行的Task数量
- 全局并行度可以通过
spark.default.parallelism配置 可以在启动参数/配置文件/SparkConf对象中配置
Spark任务调度
- DAG Scheduler: 处理逻辑的DAG图, 最后得到逻辑上的Task划分
- Task Scheduler: 基于DAG Scheduler调度处的逻辑划分, 决定任务实际在那些物理Executor上执行, 以及监控管理他们的运行
Spark SQL
基本使用
- SparkSQL是Spark的一个模块, 用于处理海量的结构化数据
- SparkSQL特点
- 融合性: SQL可以无缝集成在代码中, 随时用SQL处理数据
- 统一数据访问: 一套标准API课读写不同数据源
- Hive兼容: 可以使用SparkSQL直接计算并生成Hive数据表
- 标准化连接: 支持标准化JDBC/ODBC连接, 方便和各种数据库进行交互
- SparkSQL和Hive的异同点
- 相同点:
- Spark和Hive都是分布式SQL计算引擎
- 都可以运行在YARN之上
- SparkSQL特点
- 内存计算; 底层基于SparkRDD
- 无元数据管理
- Hive特点
- 磁盘计算, 底层基于MapReduce
- 元数据管理基于MetaStore
- 相同点:
- SparkSQL中的数据抽象:
- DataFrame, 是以二维表数据结构存储 类似于Pandas, 但是是分布式存储
- SchemaRDD对象: 类似于RDD, 对RDD修改使其支持SQL
- DataSet对象: 用于Java/Scala语言, 带有泛型特性
- SparkSession: 类似于SparkContext, 是Spark的入口对象
- 可以用作SparkSQL入口对象
- 也可以用于SparkCore编程, 因为可以通过SparkSession获取SparkContext对象
读取csv
对于订单数据
id,user_id,commodity_code,count,money
2,user1,00001,2,200
3,user1,00001,2,200
4,user1,00001,2,200
9,user1,00001,2,200
10,user1,00001,2,200
11,user1,00001,2,200
12,user1,00001,2,200
13,user1,00001,2,200
15,user1,00001,2,200
18,user1,00001,20,200
可以通过spark读取
public class SparkSQLBase {
public static void main(String[] args) throws AnalysisException {
// 创建SparkSession对象
SparkSession spark = SparkSession.builder()
.appName("test")
.master("local[*]")
.getOrCreate();
// 通过SparkSession获取SparkContext
SparkContext context = spark.sparkContext();
Dataset<Row> df = spark.read().csv("bigdata/src/main/resources/order.csv")
.toDF("id", "user_id", "commodity_code", "count", "money");
df.printSchema();
df.show();
// 创建表
df.createTempView("order");
// 写sql
spark.sql("SELECT * FROM order limit 3;").show();
// 使用dsl风格写sql
df.where("count=20").show();
}
}
输出为
root
|-- id: string (nullable = true)
|-- user_id: string (nullable = true)
|-- commodity_code: string (nullable = true)
|-- count: string (nullable = true)
|-- money: string (nullable = true)
+---+-------+--------------+-----+-----+
| id|user_id|commodity_code|count|money|
+---+-------+--------------+-----+-----+
| id|user_id|commodity_code|count|money|
| 2| user1| 00001| 2| 200|
| 3| user1| 00001| 2| 200|
| 4| user1| 00001| 2| 200|
| 9| user1| 00001| 2| 200|
| 10| user1| 00001| 2| 200|
| 11| user1| 00001| 2| 200|
| 12| user1| 00001| 2| 200|
| 13| user1| 00001| 2| 200|
| 15| user1| 00001| 2| 200|
| 18| user1| 00001| 20| 200|
+---+-------+--------------+-----+-----+
+---+-------+--------------+-----+-----+
| id|user_id|commodity_code|count|money|
+---+-------+--------------+-----+-----+
| id|user_id|commodity_code|count|money|
| 2| user1| 00001| 2| 200|
| 3| user1| 00001| 2| 200|
+---+-------+--------------+-----+-----+
+---+-------+--------------+-----+-----+
| id|user_id|commodity_code|count|money|
+---+-------+--------------+-----+-----+
| 18| user1| 00001| 20| 200|
+---+-------+--------------+-----+-----+
DataFrame
- DataFrame是一个二维表结构, 因此由以下三点构成:
- 行: 数据行
- 列: 记录一个列的数据, 并且描述一个列的信息
- 表结构: 描述表的结构
- DataFrame具体组成
- StructType: 描述整个DataFrame的表结构
- StructField: 描述一个列的信息
- 数据层面组成:
- Row: 记录一整行的数据
- Column: 记录一个列的数据, 并且包含列的信息
通过StructType构建DataSet
@Test
public void buildFromRdd() throws AnalysisException {
@Cleanup JavaSparkContext context = JavaSparkContext.fromSparkContext(spark.sparkContext());
JavaRDD<Row> rdd = context.textFile("src/main/resources/traffic.txt", 10)
.map(line -> line.split("\t"))
.map(words -> RowFactory.create(Long.parseLong(words[0]), words[1]));
Dataset<Row> df = spark.createDataFrame(rdd, DataTypes.createStructType(Arrays.asList(
DataTypes.createStructField("phone_number", DataTypes.LongType, true),
DataTypes.createStructField("ip", DataTypes.StringType, true)
)));
df.printSchema();
// 展示数据
// 展示前20条数据, 并且不截断数据
df.show(20, false);
// 将DataSet注册为临时表; 这样就可以查询了
df.createTempView("traffic");
spark.sql("SELECT * FROM traffic where phone_number < 14589530085").show();
}
从不同数据源读取数据(以CSV为例)
@Test
public void buildFromSparkSql() throws AnalysisException {
Dataset<Row> df = spark.read()
.format("csv")
.option("header", false)
.option("sep", "\t")
.option("encoding", StandardCharsets.UTF_8.name())
.schema(DataTypes.createStructType(Arrays.asList(
DataTypes.createStructField("phone_number", DataTypes.LongType, true),
DataTypes.createStructField("ip", DataTypes.StringType, true)
)))
.load("src/main/resources/traffic.txt");
df.printSchema();
df.createTempView("traffic");
spark.sql("SELECT * FROM traffic where phone_number < 14589530085").show();
}
DataFrame操作
数据准备
private final static SparkSession spark = SparkSession.builder()
.appName("test")
.master("local[*]")
.getOrCreate();
private final static Dataset<Row> df = spark.read()
.format("csv")
.option("header", false)
.option("sep", "\t")
.option("encoding", StandardCharsets.UTF_8.name())
.schema(DataTypes.createStructType(Arrays.asList(
DataTypes.createStructField("phone_number", DataTypes.LongType, true),
DataTypes.createStructField("ip", DataTypes.StringType, true),
DataTypes.createStructField("host", DataTypes.StringType, true),
DataTypes.createStructField("up", DataTypes.LongType, false),
DataTypes.createStructField("down", DataTypes.LongType, false),
DataTypes.createStructField("code", DataTypes.IntegerType, false)
)))
.load("src/main/resources/traffic.txt");
通过DSL语法操作
@Test
public void dslStyleQuery() {
df.select("ip", "code")
.filter(df.col("phone_number").lt(14589530085L))
.limit(10)
.show();
}
输出为
+--------------+----+
| ip|code|
+--------------+----+
| 110.11.174.29| 200|
| 21.234.130.14| 200|
| 90.242.200.96| 404|
| 68.99.109.14| 200|
|148.227.226.79| 404|
|153.178.25.132| 200|
| 191.49.192.31| 500|
| 10.60.145.193| 500|
| 52.122.13.63| 500|
| 203.82.225.65| 500|
+--------------+----+
通过SQL操作
@Test
public void sqlStyleQuery() throws AnalysisException {
// // 创建全局临时试图, 可以跨session共享
// df.createGlobalTempView()
// // 同createTempView, 但是视图存在则替换;
// df.createOrReplaceGlobalTempView();
df.createTempView("traffic");
spark.sql("SELECT code, count(*) FROM traffic group by code").show();
}
输出为
+----+--------+
|code|count(1)|
+----+--------+
| 500| 38|
| 404| 25|
| 200| 37|
+----+--------+
SparkSQL实现WordCount
通过rdd分词
@Test
public void wordCount_buildFromRDD() throws AnalysisException {
@Cleanup JavaSparkContext context = JavaSparkContext.fromSparkContext(spark.sparkContext());
JavaRDD<Row> rdd = context.textFile("hdfs://server.passnight.local/test/word list.txt", 10)
.flatMap(line -> Arrays.stream(line.split(" ")).iterator())
.map(RowFactory::create);
Dataset<Row> df = spark.createDataFrame(rdd, DataTypes.createStructType(List.of(
DataTypes.createStructField("word", DataTypes.StringType, false)
)));
df.createTempView("words");
spark.sql("SELECT word, count(*) AS cnt FROM words GROUP BY word ORDER BY cnt DESC")
.show();
}
输出为
+---------+---+
| word|cnt|
+---------+---+
| I| 4|
| love| 2|
|passnight| 2|
| like| 2|
| hadoop| 2|
+---------+---+
通过functions分词
@Test
public void wordCount_buildFromSparkSql() throws AnalysisException {
Dataset<Row> words = spark.read()
.text("hdfs://server.passnight.local/test/word list.txt");
words.printSchema();
Dataset<Row> df2 = words.withColumn("value", functions.explode(functions.split(words.col("value"), " ")));
df2.createTempView("words");
df2.groupBy("value")
.count()
.orderBy("count")
.show();
}
输出为
+---------+-----+
| value|count|
+---------+-----+
| love| 2|
|passnight| 2|
| like| 2|
| hadoop| 2|
| I| 4|
+---------+-----+
写api
@Test
public void writeText() {
// text只能写出一列数据, 因此要将df转化为一列
df.select(functions.concat_ws("---",
functions.col("ip"),
functions.col("up"),
functions.col("down")))
.write()
.mode("overwrite")
.format("text")
.save("data.txt");
}
@Test
public void writeCsv() {
df.select(functions.col("ip"),
functions.col("up"),
functions.col("down"))
.write()
.mode("overwrite")
.option("sep", ",")
.option("header", true)
.format("csv")
.save("data.csv");
}
@Test
public void writeJson() {
df.select(functions.col("ip"),
functions.col("up"),
functions.col("down"))
.write()
.mode("overwrite")
.format("json")
.save("data.json");
}
@Test
public void writeParquet() {
df.select(functions.col("ip"),
functions.col("up"),
functions.col("down"))
.write()
.mode("overwrite")
.format("parquet")
.save("data.parquet");
}
UDF
- 在SparkSQL分析处理数据时, 往往需要使用到函数; 而SparkSQL自带的函数可能无法覆盖全部的需求, 因此SparkSQL可以通过自定义UDF来实现自定义函数
- 在Hive中, UDF分为以下三类
- UDF(User Defined Function)函数:
- 1对1关系, 输入一个值, 经过函数输出后输出一个值
- 在Hive中集成
UDF类, 方法名称为evaluate, 返回值不能为void; 本质上是一个方法
- UDAF(User Defined Aggregation Function)聚合函数
- 多对1关系, 输入多个值输出一个值, 通常与
groupBy一起使用
- 多对1关系, 输入多个值输出一个值, 通常与
- UDTF(User Defined Table-Generating Function)函数
- 1对多的关系, 输入一个值, 输出多个值 类似
flatMap
- 1对多的关系, 输入一个值, 输出多个值 类似
- UDF(User Defined Function)函数:
基本UDF
- UDF的使用有以下三种方式
- 调用
spark.udf().register()后, 通过funcions.callUDF调用 - 通过
funcitons.udf的返回值调用 - 调用
spark.udf().register()后, 直接在SQL中调用
- 调用
@Test
public void basicUdf() throws AnalysisException {
Dataset<Row> df = spark.createDataFrame(IntStream.range(0, 10)
.boxed()
.map(RowFactory::create)
.collect(Collectors.toList()),
DataTypes.createStructType(List.of(DataTypes.createStructField("value", DataTypes.IntegerType, false))));
// 注册一个udf, 名称为`timeTen`
// `timeTen`名称可以可以用于SQL风格调用
// dsl风格通过`functions.callUDF()`调用
// 也可以通过functions.udf注册, 这样可以直接通过返回的方法调用
spark.udf().register("timeTen", (UDF1<Integer, Integer>) x -> 10 * x, DataTypes.IntegerType);
// dsl风格, 使用`functions.callUDF()`调用
UserDefinedFunction timeTen = functions.udf((UDF1<Integer, Integer>) x -> x * 10, DataTypes.IntegerType);
df.withColumn("value", functions.callUDF("timeTen", functions.col("value")))
.show();
// dsl风格, 使用`functions.udf()`返回值
df.withColumn("value", timeTen.apply(functions.col("value")))
.show();
// SQL风格, 直接在SQL中调用
df.createTempView("values");
spark.sql("select timeTen(value) from values").show();
}
输出为
+-----+
|value|
+-----+
| 0|
| 10|
| 20|
| 30|
| 40|
| 50|
| 60|
| 70|
| 80|
| 90|
+-----+
+-----+
|value|
+-----+
| 0|
| 10|
| 20|
| 30|
| 40|
| 50|
| 60|
| 70|
| 80|
| 90|
+-----+
+--------------+
|timeTen(value)|
+--------------+
| 0|
| 10|
| 20|
| 30|
| 40|
| 50|
| 60|
| 70|
| 80|
| 90|
+--------------+
返回数组的UDF
@Test
public void arrayUdf() {
Dataset<Row> df = spark.createDataFrame(IntStream.range(0, 10)
.boxed()
.map(RowFactory::create)
.collect(Collectors.toList()),
DataTypes.createStructType(List.of(DataTypes.createStructField("value", DataTypes.IntegerType, false))));
UserDefinedFunction toArray = functions.udf((UDF1<Integer, List<Integer>>) x -> Arrays.asList(x, x, x, x, x), DataTypes.createArrayType(DataTypes.IntegerType));
df.withColumn("value", toArray.apply(functions.col("value"))).show();
}
输出为
+---------------+
| value|
+---------------+
|[0, 0, 0, 0, 0]|
|[1, 1, 1, 1, 1]|
|[2, 2, 2, 2, 2]|
|[3, 3, 3, 3, 3]|
|[4, 4, 4, 4, 4]|
|[5, 5, 5, 5, 5]|
|[6, 6, 6, 6, 6]|
|[7, 7, 7, 7, 7]|
|[8, 8, 8, 8, 8]|
|[9, 9, 9, 9, 9]|
+---------------+
返回Map类型的UDF
@Test
public void mapUdf() {
Dataset<Row> df = spark.createDataFrame(IntStream.range(0, 10)
.boxed()
.map(RowFactory::create)
.collect(Collectors.toList()),
DataTypes.createStructType(List.of(DataTypes.createStructField("value", DataTypes.IntegerType, false))));
UserDefinedFunction toArray = functions.udf((UDF1<Integer, Map<Integer, String>>) x -> Map.of(x, String.valueOf(x)), DataTypes.createMapType(DataTypes.IntegerType, DataTypes.StringType));
df.withColumn("value", toArray.apply(functions.col("value"))).show();
}
输出为
+--------+
| value|
+--------+
|{0 -> 0}|
|{1 -> 1}|
|{2 -> 2}|
|{3 -> 3}|
|{4 -> 4}|
|{5 -> 5}|
|{6 -> 6}|
|{7 -> 7}|
|{8 -> 8}|
|{9 -> 9}|
+--------+
窗口函数
- 窗口函数: 窗口函数既显示聚合前的数据又显示聚合后的数据 即显示每一行都显示聚合结果
public class WindowTest {
private final static SparkSession spark = SparkSession.builder()
.appName("test")
.master("local[*]")
.getOrCreate();
private final static Dataset<Row> df = spark.read()
.format("csv")
.option("header", false)
.option("sep", "\t")
.option("encoding", StandardCharsets.UTF_8.name())
.schema(DataTypes.createStructType(Arrays.asList(
DataTypes.createStructField("phone_number", DataTypes.LongType, true),
DataTypes.createStructField("ip", DataTypes.StringType, true),
DataTypes.createStructField("host", DataTypes.StringType, true),
DataTypes.createStructField("up", DataTypes.LongType, false),
DataTypes.createStructField("down", DataTypes.LongType, false),
DataTypes.createStructField("code", DataTypes.IntegerType, false)
))).load("src/main/resources/traffic.txt");
@BeforeClass
public static void setUpClass() throws AnalysisException {
df.createTempView("traffic");
}
@Test
public void aggregationWindow() {
spark.sql("SELECT *, AVG(down) OVER() AS avg_down FROM traffic").show();
}
@Test
public void orderWindow() {
spark.sql("SELECT *, RANK() OVER(ORDER BY down DESC) AS rank_down," +
"DENSE_RANK() OVER(PARTITION BY code ORDER BY down DESC) AS dense_rank_down," +
"ROW_NUMBER() OVER(ORDER BY down) AS row_number_down FROM traffic").show();
}
}
输出结果为
+------------+---------------+--------------------+----+----+----+--------+
|phone_number| ip| host| up|down|code|avg_down|
+------------+---------------+--------------------+----+----+----+--------+
| 14591430480| 206.175.250.82| web-49.28.cn|6652|4853| 200| 4597.34|
| 14576404331| 110.11.174.29| lt-91.duxu.cn|3691|9180| 200| 4597.34|
| 14582487728| 21.234.130.14| desktop-19.13.cn|2797|1428| 200| 4597.34|
| 14596521336| 149.125.91.187| db-46.guiying.cn|4742|3870| 500| 4597.34|
| 15964887988|201.254.165.183|desktop-12.guiyin...|8266|8951| 500| 4597.34|
| 14582499209| 90.242.200.96| db-36.05.cn|3686|1143| 404| 4597.34|
| 14505200322| 68.99.109.14| web-94.40.org|6978|4684| 200| 4597.34|
| 15057102608| 73.31.103.153|desktop-77.zhongw...|1180| 785| 404| 4597.34|
| 15961211597| 159.244.71.102| web-89.dh.net|8526|4965| 500| 4597.34|
| 15311413947| 60.85.30.231| db-34.shenhuang.cn|1942|9698| 500| 4597.34|
| 13755692548| 148.227.226.79| srv-89.fanggao.cn|3049|2243| 404| 4597.34|
| 15512665231| 172.147.244.20| lt-73.taoguiying.cn|9494| 151| 200| 4597.34|
| 13671972925| 153.178.25.132| srv-73.31.cn|3311|1452| 200| 4597.34|
| 18142899590| 31.150.73.196| web-49.nl.cn|2909| 277| 500| 4597.34|
| 15013760479| 94.26.117.22| email-47.63.cn|5645|4756| 200| 4597.34|
| 15696235979| 80.73.193.75| lt-91.lei.cn|9845|1267| 404| 4597.34|
| 15678423363| 171.44.202.193| db-37.99.cn|7496|7354| 200| 4597.34|
| 13313631905| 191.49.192.31| laptop-78.nd.cn|3037|3070| 500| 4597.34|
| 15911783755| 208.18.32.83| db-48.yao.net|4846|4935| 404| 4597.34|
| 14589530086| 57.193.203.100| srv-25.mingcao.cn|1861|3034| 200| 4597.34|
+------------+---------------+--------------------+----+----+----+--------+
+------------+---------------+--------------------+----+----+----+---------+---------------+---------------+
|phone_number| ip| host| up|down|code|rank_down|dense_rank_down|row_number_down|
+------------+---------------+--------------------+----+----+----+---------+---------------+---------------+
| 14576404331| 110.11.174.29| lt-91.duxu.cn|3691|9180| 200| 5| 1| 96|
| 15848614274|221.193.203.253| web-81.duanxiao.cn|8474|8973| 200| 6| 2| 95|
| 15133313425| 3.41.203.203| laptop-65.fan.cn|1979|8496| 200| 12| 3| 89|
| 14722781518| 41.33.230.230|laptop-66.zhangze...|3840|8161| 200| 15| 4| 86|
| 13985614323| 105.154.67.146| laptop-67.jie.cn|5629|7876| 200| 18| 5| 83|
| 15025055835| 57.67.224.58| web-46.weiliao.cn|1093|7830| 200| 19| 6| 82|
| 15708423956| 52.173.24.63| web-36.yangchao.cn| 201|7774| 200| 20| 7| 81|
| 15550368967| 181.80.90.147| laptop-44.yanli.cn|4669|7770| 200| 21| 8| 80|
| 15281538689| 173.204.178.87| web-83.weimin.cn|7082|7718| 200| 23| 9| 78|
| 13618975336| 178.12.49.98| srv-13.min.net|9290|7560| 200| 24| 10| 77|
| 14765852831| 121.98.240.15| laptop-81.fang.cn|3595|7556| 200| 25| 11| 76|
| 15678423363| 171.44.202.193| db-37.99.cn|7496|7354| 200| 27| 12| 74|
| 13434369051| 220.82.35.57| srv-03.longqian.org|2160|6650| 200| 30| 13| 71|
| 14554599007| 52.35.92.91| web-91.xiulanlai.cn|6098|5124| 200| 38| 14| 63|
| 14591430480| 206.175.250.82| web-49.28.cn|6652|4853| 200| 42| 15| 59|
| 15013760479| 94.26.117.22| email-47.63.cn|5645|4756| 200| 43| 16| 58|
| 14505200322| 68.99.109.14| web-94.40.org|6978|4684| 200| 46| 17| 55|
| 13913021809| 190.111.163.19| srv-83.jn.cn|8296|4349| 200| 48| 18| 53|
| 15108282222| 56.175.78.40| laptop-17.mao.net|8846|3830| 200| 55| 19| 46|
| 18788825153| 61.76.43.152| lt-48.81.net|8101|3812| 200| 56| 20| 45|
+------------+---------------+--------------------+----+----+----+---------+---------------+---------------+
SparkSQL执行流程
-
RDD的执行流程
RDD->DAGScheduler->TaskSceduler->Worker -
与RDD不同的是, SparkSQL会对写完的代码执行自动优化; 以提高代码执行效率
-
SparkSQL可以自动优化而RD不行的原因
- RDD仅包含数据而不包含格式; DataFrame是有结构的二维表结构
- SparkSQL的优化器为Catalyst优化器
-
Catalyst执行流程:
2. API层接受SQL语句, Catalyst解析SQL并生对应的RDD执行计划, 并由集群执行 -
Catalyst优化器
具体流程
-
解析SQL, 生成AST:

-
在AST中加入元数据信息, 便于后续优化 如score.id -> id#1#L; 表score.id的id为1, 类型为Long
-
进行优化, 主要的友发方式有谓词下推即列值裁剪
- 谓词下推: 尽量下推谓词操作, 这样可以减少操作时候的数据量
- 列值裁剪: 在断言下推后执行裁剪, 裁剪掉不需要的列, 进而减少需要处理的数据量
-
生成执行计划: 根据上述过程生成的优化后的AST, 生成物理计划, 从而生成RDD来执行
引用
^:文章来源:https://www.toymoban.com/news/detail-777788.html
-
Downloads | Apache Spark ↩︎文章来源地址https://www.toymoban.com/news/detail-777788.html
到了这里,关于【大数据】Spark学习笔记的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!