目录
讲解selenium获取href - find_element_by_xpath
什么是XPath?
使用find_element_by_xpath获取href
Selenium的特点和优势
Selenium的应用场景
Selenium的核心组件
总结
讲解selenium获取href - find_element_by_xpath
Selenium是一个常用的自动化测试工具,可用于模拟用户操作浏览器。在Web开发和爬虫中,经常需要从网页中获取链接地址(href),而Selenium提供了各种方式来实现这个目标。 在本篇文章中,我将主要讲解使用Selenium的find_element_by_xpath方法来获取网页中的href属性值。
什么是XPath?
XPath(XML Path Language)是一种用于在XML和HTML文档中定位元素的语言。在Selenium中,我们可以使用XPath来定位网页中的元素,包括链接。 XPath表达式通过路径和表达式来选择元素,常用的表达式包括//(选取节点)、@(选取属性)等。
使用find_element_by_xpath获取href
以下是使用Selenium的find_element_by_xpath方法获取链接地址的示例代码:
pythonCopy code
from selenium import webdriver
# 创建浏览器驱动
driver = webdriver.Chrome()
# 打开网页
driver.get("https://example.com")
# 使用XPath定位链接
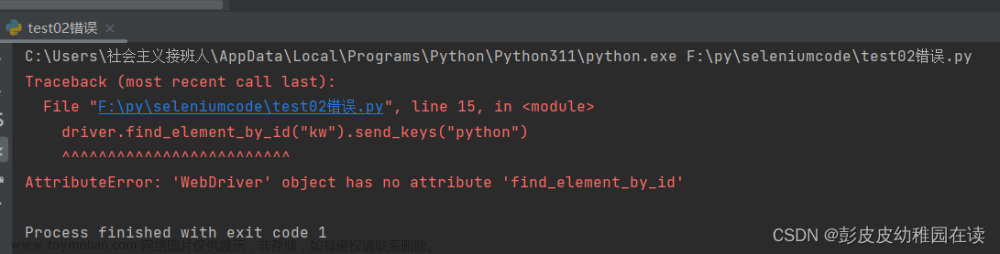
element = driver.find_element_by_xpath("//a[@href]")
href = element.get_attribute("href")
print(href)
# 关闭浏览器
driver.quit()代码解释:
- 首先,我们导入webdriver模块并创建一个浏览器驱动。
- 然后,使用driver.get方法打开目标网页。
- 接下来,使用XPath表达式//a[@href]定位所有包含href属性的链接元素。这个表达式指定了选择所有a标签(链接),并且这些标签包含href属性。
- 接着,通过element.get_attribute("href")方法获取链接的地址,并将其保存在href变量中。
- 最后,我们可以打印出得到的链接地址,并可以根据需求进行后续处理。
- 最后,调用driver.quit()方法关闭浏览器。
当使用Selenium进行网页爬取或者测试时,常常需要获取网页中的链接地址。以下是一个示例代码,展示了如何使用Selenium的find_element_by_xpath方法获取网页中特定元素的链接地址。
pythonCopy code
from selenium import webdriver
# 创建浏览器驱动
driver = webdriver.Chrome()
# 打开目标网页
driver.get("https://www.example.com")
# 使用XPath定位链接
link_element = driver.find_element_by_xpath("//a[@class='link']")
link_href = link_element.get_attribute("href")
# 输出链接地址
print("链接地址为:", link_href)
# 关闭浏览器
driver.quit()在上述示例中,我们打开了一个网页(https://www.example.com),然后使用XPath表达式//a[@class='link']定位到具有class属性为"link"的链接元素。然后通过get_attribute方法获取链接元素的href属性值,最后将链接地址打印出来。 实际应用场景中,可以根据需要修改XPath表达式来定位到不同的元素。例如,如果要获取所有链接的地址,可以使用find_elements_by_xpath方法,并在循环中逐个获取每个链接的地址。
pythonCopy code
link_elements = driver.find_elements_by_xpath("//a[@href]")
for link_element in link_elements:
link_href = link_element.get_attribute("href")
print("链接地址为:", link_href)这样,就可以获取到网页中所有链接的地址,并进行后续处理。请根据具体的需求和网页结构来调整代码,以获取你所需要的链接地址。
Selenium是一个广泛使用的自动化测试工具,主要用于模拟用户在网页上的交互操作。它支持多种编程语言,并且可以在多种浏览器上运行,包括Chrome、Firefox、Safari等。Selenium的目标是提供一个简单而又直观的方式来执行浏览器行为自动化,从而加快Web应用程序的测试和开发过程。
Selenium的特点和优势
- 真实性: Selenium模拟用户通过真实浏览器与网页进行交互,能够准确地模拟用户的行为操作,包括点击、输入文本、提交表单等。
- 跨浏览器: Selenium支持多款主流浏览器,方便运行测试用例或进行爬虫开发。
- 灵活性: Selenium提供了多种定位元素的方法,包括XPath、CSS selector、ID等,可以根据网页的具体结构和需求进行灵活定位。
- 可扩展性: Selenium支持使用不同的编程语言进行测试编写,如Python、Java、C#等,方便根据项目要求进行扩展和集成。
- 可视化界面: Selenium还提供了可视化界面工具Selenium IDE,通过录制和回放的方式帮助用户快速生成测试脚本。
Selenium的应用场景
- 自动化测试: Selenium可以模拟用户在网页上的各种操作,如点击、输入文本、选择下拉框等,可以用于编写自动化测试用例,加速测试过程,提高测试覆盖率。
- 网页爬虫: Selenium可以模拟浏览器的行为操作,对于一些需要JavaScript渲染的网页,可以使用Selenium来获取完整的页面数据,对于一些需要登录或者频繁交互的网站,也可以用Selenium来模拟用户操作。
- 数据挖掘和捕捉: 使用Selenium,可以方便地获取网页中的特定数据或截取网页的截图,用于数据挖掘和数据分析。
- UI自动化: Selenium可以用于自动化验证Web应用程序的用户界面,对于一些重复、频繁的操作,可以编写脚本来自动执行,节省时间和人力成本。
Selenium的核心组件
Selenium由三个核心组件组成:
- Selenium WebDriver: WebDriver是Selenium的主要组件,它以编程语言API的形式提供了一系列方法和功能,用于控制浏览器并模拟用户操作。
- Selenium Grid: Selenium Grid是一个分布式测试工具,可以同时在多台机器上运行测试脚本,并可跨浏览器和操作系统进行并行测试。
- Selenium IDE: Selenium IDE是一款用于录制和回放测试脚本的可视化工具,它提供了简单的界面,方便用户快速生成和执行测试脚本。
Selenium是一个功能强大的自动化测试工具,通过模拟用户行为操作网页,可以加快测试和开发过程,提高测试覆盖率和效率。它具有跨浏览器、灵活性、可扩展性和可视化界面等特点和优势。除了自动化测试之外,Selenium还可以应用于网页爬虫、数据挖掘、UI自动化等各种场景。通过Selenium的不同组件,我们可以灵活地控制和操作浏览器,实现各种自动化需求。文章来源:https://www.toymoban.com/news/detail-777855.html
总结
使用Selenium的find_element_by_xpath方法可以轻松地获取网页中的链接地址。通过提供XPath表达式,我们可以定位到具有特定属性的元素,并获取对应的链接地址。文章来源地址https://www.toymoban.com/news/detail-777855.html
到了这里,关于讲解selenium 获取href find_element_by_xpath的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!