引言
随着移动设备性能的不断提升和多媒体内容的广泛传播,从视频中提取音频已成为众多开发者与用户日常操作的一部分。在安卓平台上,这项技术经历了从早期的复杂专业工具到现今便捷易用的应用程序的演变过程。本文旨在探讨安卓系统中视频转音频(Video to Audio Extraction, VAE)技术的发展历史、主要应用场景,并对不同实现方法的技术特点和优劣进行深入剖析。
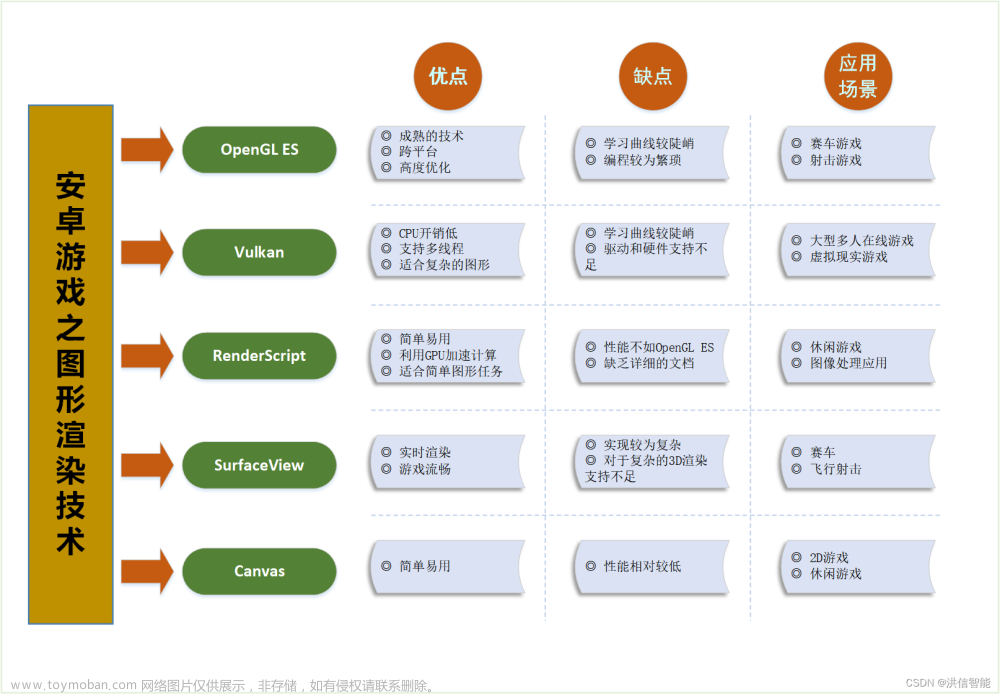
一、发展历史
1.1、早期探索(2008年-2012年)
安卓系统初期,对于多媒体处理尤其是音视频编解码支持有限。开发者主要依赖于FFmpeg等开源工具包来实现音视频转换功能。这一时期的开发过程相对复杂,需要通过Android NDK结合JNI技术调用C/C++编写的底层代码,对视频文件进行解封装和音频流的提取。
1.2、原生API引入与优化(2012年-2016年)
从Android 4.x版本开始,Google逐渐增强了系统的多媒体处理能力,引入了如MediaExtractor、MediaCodec以及后来的MediaMuxer等原生API。这些API允许开发者在Java层面上直接操作媒体文件,从而简化了从视频中提取音频的过程。例如,MediaExtractor可以从视频容器格式中分离出音频轨道,MediaCodec则用于解码音频数据。
1.3、SDK与第三方库集成(2016年至今)
随着移动设备硬件性能的提升和市场需求的增长,出现了许多专为安卓平台设计的多媒体处理SDK和第三方库,如ExoPlayer、Vitamio等,它们提供了更为高效且易用的接口,方便开发者快速集成并实现视频转音频的功能。同时,各种轻量级的应用程序也在各大应用商店上线,使得普通用户无需专业技术也能轻松将视频中的音频提取出来。
1.4、深度学习与AI驱动
近年来,随着深度学习和人工智能技术的发展,音频处理领域也引入了更先进的算法和技术。虽然从视频中提取音频并不直接涉及深度学习,但AI技术的普及推动了整个多媒体处理生态链的创新,包括更好的音频编码、压缩、噪声消除等方面,间接提升了从视频中提取高质量音频的能力。
二、应用场景
2.1、多媒体创作
在音乐制作、播客剪辑等领域,用户可能需要从原始视频素材中提取纯净的音频用于后期编辑和混音。
2.2、教育资源整合
教育类应用可以提供视频转音频服务,便于用户在听书、学习外语时只关注音频内容,从而提高学习效率。
2.3、版权管理与合规需求
版权审查或存档过程中,可能需要将视频中的音频部分单独剥离出来以便于进一步分析或存储。
2.4、视频字幕生成
对于听力障碍者或需要重复观看视频的人来说,从视频中提取音频并转换为文字可以为他们提供更好的理解。
2.5、会议记录
在会议或讲座中,实时将发言人的讲话转换为文字可以帮助快速记录和整理信息。
2.6、语音助手集成
将音频提取技术应用于智能家居或车载语音助手,可以更准确地识别用户的语音指令。
三、技术优劣分析
3.1、基于FFmpeg的解决方案
3.1.1、优点
功能强大,几乎支持所有常见的音视频格式转换;
3.1.2、缺点
移植到安卓环境时需额外工作,占用资源较多,且对非专业开发者友好度较低。
3.1.3、代码示例
public void extractAudioFromVideo(String videoFilePath, String audioFilePath) { String command = "ffmpeg -i " + videoFilePath + " -vn -acodec copy " + audioFilePath; try { Process process = Runtime.getRuntime().exec(command); process.waitFor(); } catch (IOException | InterruptedException e) { e.printStackTrace(); } }
videoFilePath参数表示视频文件的路径,audioFilePath参数表示要保存音频文件的路径。通过执行ffmpeg命令,将视频文件中的音频提取出来并保存到指定的音频文件中。其中,-i选项指定输入文件,-vn选项表示不输出视频流,-acodec copy选项表示直接复制音频流。最后,通过process.waitFor()方法等待进程执行完成。
确保你的应用有足够的权限来访问存储空间以保存提取的音频文件。此外,由于FFmpeg操作可能需要一些时间,因此你可能需要考虑在后台线程中执行此操作,以避免阻塞UI线程。
3.2、Android原生API
3.2.1、优点
原生支持,性能较好,无需额外依赖。
3.2.2、缺点
对新格式的支持可能会滞后,且API使用较为复杂,需要深入理解媒体编解码原理。
3.2.3、代码示例
import android.media.MediaExtractor; import android.media.MediaFormat; import java.io.IOException; import java.nio.ByteBuffer; public class AudioExtractor { private MediaExtractor extractor; private ByteBuffer buffer; public AudioExtractor(String videoFilePath) throws IOException { extractor = new MediaExtractor(); extractor.setDataSource(videoFilePath); int trackCount = extractor.getTrackCount(); for (int i = 0; i < trackCount; i++) { MediaFormat mediaFormat = extractor.getTrackFormat(i); if (mediaFormat.getString(MediaFormat.KEY_MIME).startsWith("audio")) { extractor.selectTrack(i); break; } } buffer = ByteBuffer.allocate(1024); extractor.readSampleData(buffer, 0); } public ByteBuffer getAudioData() { return buffer; } }
首先创建了一个MediaExtractor对象,并设置了数据源为指定的视频文件。然后,遍历所有的轨道,找到第一个音频轨道,并将其设置为当前轨道。最后,从当前轨道中读取音频数据。
3.3、深度学习
3.3.1、优点
3.3.1.1、实时处理
深度学习模型可以在移动设备上实时处理视频,提取音频信息。这对于需要实时响应的应用程序(如语音识别、视频监控等)非常有用。
3.3.1.2、高精度
训练良好的深度学习模型能够提供高精度的音频提取,减少噪声和其他干扰的影响。
3.3.1.3、灵活性
深度学习模型可以针对不同的视频格式和音频编码进行训练,使得提取过程更加灵活,适应多种场景。
3.3.1.4、可扩展性
随着深度学习技术的发展,可以不断改进和优化模型,提高音频提取的性能和准确性。
3.3.2、缺点
3.3.2.1、计算资源限制
在移动设备上运行深度学习模型需要大量的计算资源,可能会导致电池消耗增加和性能下降。优化模型和代码以减少计算需求是一个持续的挑战。
3.3.2.2、数据隐私
处理视频和音频数据可能会涉及到用户隐私。确保在收集和处理数据时遵守相关法规和隐私政策是非常重要的。
3.3.2.3、模型大小
深度学习模型通常较大,这会增加应用程序的大小和下载时间。为了减小模型大小,可能需要采用模型压缩或量化等技术。
3.3.2.4、依赖外部库
实现深度学习功能可能需要依赖外部库(如TensorFlow Lite),这可能会增加开发复杂性和维护成本。
3.3.3、代码示例
import org.tensorflow.lite.Interpreter; import java.io.File; import java.io.FileInputStream; import java.io.IOException; import java.nio.MappedByteBuffer; import java.nio.channels.FileChannel; public class AudioExtractor { private Interpreter interpreter; private float[] inputMean; private float[] inputStd; public AudioExtractor(String modelPath) { try { interpreter = new Interpreter(loadModelFile(modelPath)); initInputOutput(); } catch (Exception e) { e.printStackTrace(); } } private MappedByteBuffer loadModelFile(String modelPath) throws IOException { File file = new File(modelPath); FileInputStream inputStream = new FileInputStream(file); FileChannel fileChannel = inputStream.getChannel(); long startOffset = file.length() - fileChannel.size(); long declaredLength = fileChannel.size(); return fileChannel.map(FileChannel.MapMode.READ_ONLY, startOffset, declaredLength); } private void initInputOutput() { // Initialize input and output tensors for the model } public byte[] extractAudioFromVideo(byte[] videoData) { float[][] inputData = preprocessVideoData(videoData); float[][] outputData = new float[1][1]; try { interpreter.run(inputData, outputData); } catch (Exception e) { e.printStackTrace(); } return postprocessAudioData(outputData); } private float[][] preprocessVideoData(byte[] videoData) { // Preprocess the video data into a suitable format for the model // This step may involve resizing, normalization, etc. } private byte[] postprocessAudioData(float[][] outputData) { // Postprocess the output data from the model to obtain audio data in a suitable format } }
3.4、第三方SDK或库
如JAVE、Xuggler等,它们提供了封装良好的接口,简化了开发流程;但可能受到授权许可、更新维护及时性以及兼容性问题的影响。文章来源:https://www.toymoban.com/news/detail-777973.html
四、总结
从视频中提取音频是一项具有挑战性的任务,但随着技术的不断进步,其应用场景越来越广泛。了解技术的发展历史、应用场景和技术优劣有助于更好地选择合适的方法和技术栈来满足特定需求。在实际应用中,需要根据具体场景和限制条件进行综合考虑,如实时性、准确性、资源成本等。文章来源地址https://www.toymoban.com/news/detail-777973.html
到了这里,关于安卓之从视频中提取音频的应用场景及技术优劣分析的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!