这个问题是Flink TM内存中我们常见的,看到这个问题我们就要想到下面这句话:
程序在垃圾回收上花了很多时间,却收集一点点内存,伴随着会出现CPU的升高。
是不是大家出现这个问题都会出现上面这种情况呢。那我的问题出现如下:

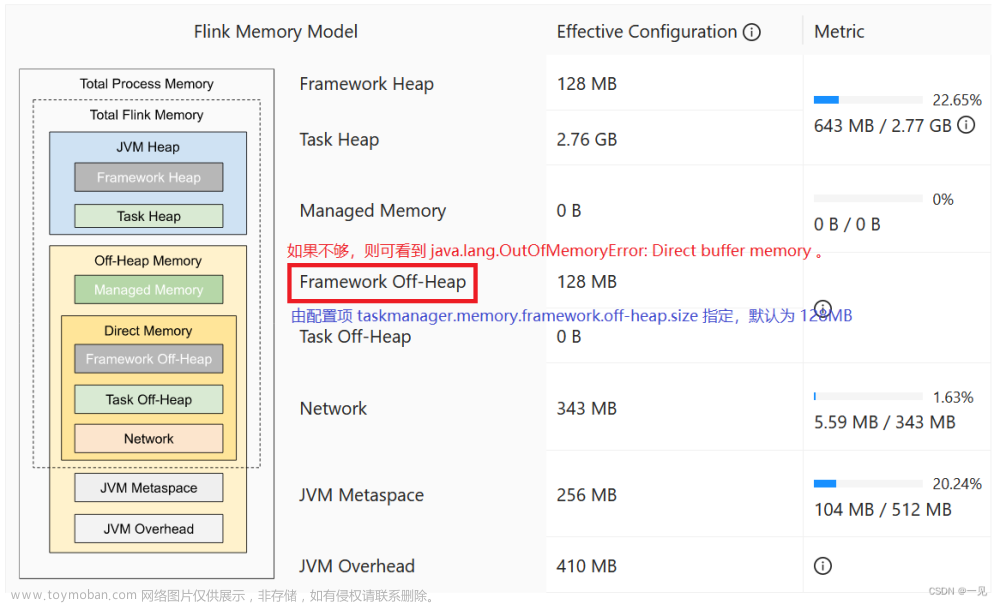
发现JVM Heap堆内存过高。那么堆内存包含2块:
framwork heap 一般设置是128MB,基本上不会出问题
task heap 是我们用户写代码所使用的的堆内存,那我们就要考虑是不是自己业务代码有问题吗?
所以我使用以下判断方法发现问题的。
1 查看某个TM的堆内存占用是否过高,如果过高,通过页面的端口号找到该TM的PID。操作如下:
例:akka.tcp://flink@IP:23567/user/taskmanager_0
找到这个IP的端口,使用 netstat 找到PID ---> netstat -atunpl | grep 23567
tcp6 0 0 :::23567 :::* LISTEN 3081/java
得到该TM的进程为3081
2 利用命令:jmap -histo:live pid 对该PID进行操作
命令:jmap -histo:live 3081 | head -20 得到
num #instances #bytes class name
----------------------------------------------
1: 24781126 792996032 java.util.HashMap$Node
2: 21094139 737237032 [C
3: 21094065 506257560 java.lang.String
4: 1560788 225984352 [Ljava.util.HashMap$Node;
5: 1557686 74768928 java.util.HashMap
6: 195141 59546144 [B
7: 1198174 38341568 java.util.concurrent.ConcurrentHashMap$Node
8: 1548207 24771312 com.alibaba.fastjson.JSONObject
9: 39805 9853696 [Ljava.lang.Object;
10: 1225 9522400 [Ljava.util.concurrent.ConcurrentHashMap$Node;
11: 157686 5045952 org.apache.hadoop.hbase.Key
发现使用HashMap占用太多,寻找自己使用HashMap的方法进行排查,发现没有释放HashMap内数据导致堆内存一直增加。
最后希望我这种判断方式对大家都有帮助!
欢迎大家关注公众号文章来源:https://www.toymoban.com/news/detail-778072.html
 文章来源地址https://www.toymoban.com/news/detail-778072.html
文章来源地址https://www.toymoban.com/news/detail-778072.html
到了这里,关于记录Flink 线上碰到java.lang.OutOfMemoryError: GC overhead limit exceeded如何处理?的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!






![idea maven 打包 内存溢出 报 GC overhead limit exceeded -> [Help 1]](https://imgs.yssmx.com/Uploads/2024/04/846987-1.png)



