- 👏作者简介:大家好,我是爱敲代码的小黄,阿里巴巴淘天Java开发工程师,CSDN博客专家
- 📕系列专栏:Spring源码、Netty源码、Kafka源码、JUC源码、dubbo源码系列
- 🔥如果感觉博主的文章还不错的话,请👍三连支持👍一下博主哦
- 🍂博主正在努力完成2023计划中:以梦为马,扬帆起航,2023追梦人
- 📝联系方式:hls1793929520,加我进群,大家一起学习,一起进步,一起对抗互联网寒冬👀
Flink-算子
Transformations 算子可以将一个或者多个算子转换成一个新的数据流
使用 Transformations 算子组合可以进行复杂的业务处理
一、Map
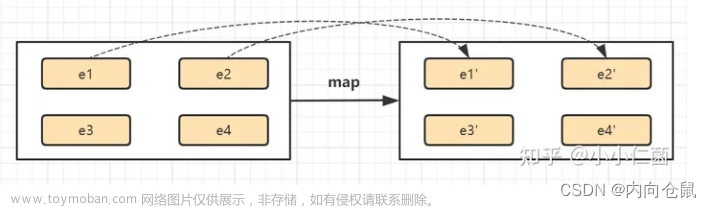
DataStream → DataStream
Map 比较简单,遍历我们数据流的每一个元素,产生一个新的元素
作用:字符串的转换、去除空格等操作
注意:只能一对一
示例如下:
/**
* 去除当前字符串的前后空格
*/
public class MyMapFunction implements MapFunction<String, String> {
@Override
public String map(String value) throws Exception {
return value.trim();
}
}
二、FlatMap
DataStream → DataStream
遍历当前数据流中的每一个元素,产生 N (N = 0,1,2,3)个元素
**作用:**与 Map 有点像,主要可以输出多个
**注意:**一对一、一对多
示例如下:
/**
* 将当前字符串按照逗号进行分割
*/
public class MyFlatMapFunction implements FlatMapFunction<String, String> {
@Override
public void flatMap(String value, Collector<String> collector) throws Exception {
if (value == null || value.isEmpty()) {
return;
}
for (String word : value.split(",")) {
collector.collect(word);
}
}
}
三、Filter
DataStream → DataStream
过滤算子,根据数据流的元素的业务逻辑,返回 true 或者 false
true:保留当前元素
false:丢弃当前元素
**作用:**过滤某些不符合预期的数据流数据
示例如下:
/**
* 过滤掉处于黑名单的数据流数据
*/
public class MyFilterFunction implements FilterFunction<String> {
private final static Set<String> blackSet = new HashSet<>();
static {
blackSet.add("num1");
blackSet.add("num2");
blackSet.add("num3");
}
@Override
public boolean filter(String value) throws Exception {
return !blackSet.contains(value);
}
}
四、Union(真合并)
DataStream → DataStream
合并两个或者更多的数据流产生一个新的数据流
新的数据流包括所合并的数据流的元素
注意:需要保证数据流中元素类型一致
/**
* 聚合多条流数据
*/
public class UnionFunction {
private final static String hostName = "";
private final static int port = 8088;
public static void main(String[] args) throws Exception {
// 1. 创建流环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 创建多条输入源
DataStreamSource<String> dataStream1 = env.socketTextStream(hostName, port);
DataStreamSource<String> dataStream2 = env.socketTextStream(hostName, port);
// 3. 合并数据源
DataStream<String> unionDataStream = dataStream1.union(dataStream2);
// 4. 输出
unionDataStream.print();
// 5. 执行
env.execute();
}
}
五、Connect(假合并)
DataStream,DataStream → ConnectedStreams
合并两个数据流并且保留两个数据流的数据类型,能够共享两个流的状态
代码示例:
public class ConnectFunction {
private final static String hostName = "";
private final static int port = 8088;
public static void main(String[] args) throws Exception {
// 1. 创建流环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 创建多条输入源
DataStreamSource<String> dataStream1 = env.socketTextStream(hostName, port);
DataStreamSource<String> dataStream2 = env.socketTextStream(hostName, port);
ConnectedStreams<String, String> connect = dataStream1.connect(dataStream2);
}
}
六、CoMap, CoFlatMap
ConnectedStreams → DataStream
CoMap 和 CoFlatMap 并不是具体算子名称,而是一类操作名称
CoMap:基于 ConnectedStreams数据流做 map 遍历
SingleOutputStreamOperator<Object> map = connect.map(new CoMapFunction<String, String, Object>() {
@Override
// 第一个数据流转换
public String map1(String value) throws Exception {
return value;
}
@Override
// 第二个数据流转换
public String map2(String value) throws Exception {
return value;
}
});
CoFlatMap:基于 ConnectedStreams 数据流做 flatMap 遍历
connect.flatMap(new CoFlatMapFunction<String, String, String>() {
@Override
public void flatMap1(String value, Collector<String> collector) throws Exception {
if (value == null || value.isEmpty()) {
return;
}
for (String word : value.split(",")) {
collector.collect(word);
}
}
@Override
public void flatMap2(String value, Collector<String> collector) throws Exception {
if (value == null || value.isEmpty()) {
return;
}
for (String word : value.split(",")) {
collector.collect(word);
}
}
});
七、Split & select(已废弃)
DataStream → SplitStream
根据条件将一个流分成两个或者更多的流
注意:
-
Split...Select...中Split只是对流中的数据打上标记,并没有将流真正拆分。 - 通过
Select算子将流真正拆分出来。 -
Split...Select...已经过时
public static void main(String[] args) throws Exception {
// 1. 创建流环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 2. 创建多条输入源
DataStreamSource<String> dataStream = env.socketTextStream(hostName, port);
// 3. 定义拆分逻辑
SplitStream<String> splitStream = dataStream.split(new OutputSelector<String>() {
@Override
public Iterable<String> select(String value) {
List<String> output = new ArrayList<>();
if (value.equals("AAA")) {
output.add("A");
} else {
output.add("B");
}
return output;
}
});
// 4. 将数据流真正拆分
splitStream.select("A").print("输出A:");
splitStream.select("B").print("输出B:");
}
八、side output
流计算过程,可能遇到根据不同的条件来分隔数据流
filter 分割造成不必要的数据复制
OutputTag<String> rtTag = new OutputTag("rt");
OutputTag<String> qpsTag = new OutputTag("qps");
SingleOutputStreamOperator<Object> process = dataStream.process(new ProcessFunction<String, Object>() {
@Override
public void processElement(String value, Context ctx, Collector<Object> out) throws Exception {
if (value.equals("RT")) {
ctx.output(rtTag, value);
} else if (value.equals("qps")) {
ctx.output(qpsTag, value);
} else {
out.collect(value);
}
}
});
// 主流
process.print();
// rt
DataStream<String> rtOutput = process.getSideOutput(rtTag);
// qps
DataStream<String> qpsOutput = process.getSideOutput(qpsTag);
九、Iterate
DataStream → IterativeStream → DataStream
Iterate 算子提供了对数据流迭代的支持
迭代有两部分组成:迭代体、终止迭代条件
不满足终止迭代条件的数据流会返回到stream流中,进行下一次迭代
满足终止迭代条件的数据流继续往下游发送
// 获取迭代数据源
IterativeStream<String> iterate = dataStreamSource.iterate();
// 迭代体
// 每次数据累加
DataStream<String> minusOne = iterate.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
return value + value;
}
}).setParallelism(1);; // 设置 map 操作的并行度为1
// 终止迭代条件(当数值小于等于10时,均再次进行迭代)
DataStream<String> stillGreaterThanZero = minusOne.filter(new FilterFunction<String>() {
@Override
public boolean filter(String value) throws Exception {
return value.length() <= 10;
}
}).setParallelism(1); // 设置 filter 操作的并行度为1
iterate.closeWith(stillGreaterThanZero);
十、keyBy
DataStream → KeyedStream
根据数据流中指定的字段来分区,相同指定字段值的数据一定是在同一个分区中
按照某 key 进行分组
dataStream.keyBy("word")
public class WordCount {
public String word;
public int count;
public WordCount(String word, int count) {
this.word = word;
this.count = count;
}
public WordCount() {}
}
// 或者使用KeySelector
KeyedStream<WordCount, String> wordCountObjectKeyedStream = dataStreamSource.keyBy(new KeySelector<WordCount, String>() {
@Override
public String getKey(WordCount wordCount) throws Exception {
return wordCount.word;
}
});
这里一定要注意:如果你采用的是 POJO 类,那么一定要加 Public 修饰符,因为 Flink 通过反射机制访问和操作这些字段,实现分组和聚合等操作
十一、Reduce
KeyedStream(根据key分组) → DataStream
对于分组完的数据流进行聚合处理
如果只是简单的累加操作,和 sum 区别不大
SingleOutputStreamOperator<WordCount> dataStream = wordCountObjectKeyedStream.reduce(new ReduceFunction<WordCount>() {
@Override
public WordCount reduce(WordCount wordCount1, WordCount wordCount2) throws Exception {
return new WordCount(wordCount1.word, wordCount1.count + wordCount2.count);
}
});
十二、Aggregations
KeyedStream → DataStream
Aggregations代表的是一类聚合算子,具体算子如下:
// 根据键对流数据中的指定位置(索引为0)的值进行求和。
keyedStream.sum(0)
// 根据键对流数据中的名为"key"的字段的值进行求和。
keyedStream.sum("key")
// 根据键对流数据中的指定位置(索引为0)的值进行取最小值。
keyedStream.min(0)
// 根据键对流数据中的名为"key"的字段的值进行取最小值。
keyedStream.min("key")
// 根据键对流数据中的指定位置(索引为0)的值进行取最大值。
keyedStream.max(0)
// 根据键对流数据中的名为"key"的字段的值进行取最大值。
keyedStream.max("key")
//根据键对流数据中的指定位置(索引为0)的值进行最小值比较,并返回具有最小值的元素。
keyedStream.minBy(0)
//根据键对流数据中的名为"key"的字段的值进行最小值比较,并返回具有最小值的元素。
keyedStream.minBy("key")
// 根据键对流数据中的指定位置(索引为0)的值进行最大值比较,并返回具有最大值的元素
keyedStream.maxBy(0)
// 根据键对流数据中的名为"key"的字段的值进行最大值比较,并返回具有最大值的元素。
keyedStream.maxBy("key")
十三、总结
鲁迅先生曾说:独行难,众行易,和志同道合的人一起进步。彼此毫无保留的分享经验,才是对抗互联网寒冬的最佳选择。
其实很多时候,并不是我们不够努力,很可能就是自己努力的方向不对,如果有一个人能稍微指点你一下,你真的可能会少走几年弯路。
如果你也对 后端架构 和 中间件源码 有兴趣,欢迎添加博主微信:hls1793929520,一起学习,一起成长
我是爱敲代码的小黄,阿里巴巴淘天集团Java开发工程师,双非二本,培训班出身
通过两年努力,成功拿下阿里、百度、美团、滴滴等大厂,想通过自己的事迹告诉大家,努力是会有收获的!
双非本两年经验,我是如何拿下阿里、百度、美团、滴滴、快手、拼多多等大厂offer的?
我们下期再见。文章来源:https://www.toymoban.com/news/detail-778105.html
从清晨走过,也拥抱夜晚的星辰,人生没有捷径,你我皆平凡,你好,陌生人,一起共勉。文章来源地址https://www.toymoban.com/news/detail-778105.html
到了这里,关于【Flink 从入门到成神系列 一】算子的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!