一、相关需求分析
1.目的
身为一个求职者,或者说是对于未来的职业规划还没明确目标的大学生来说,获取各大招聘网上的数据对我们自身的发展具有的帮助作用,本文章就简答零基础的来介绍一下如何爬取招聘数据。
二、直聘网页结构分析
我们先来分析一下网页的结构便于后续数据和采集
1.网页相关值的查找
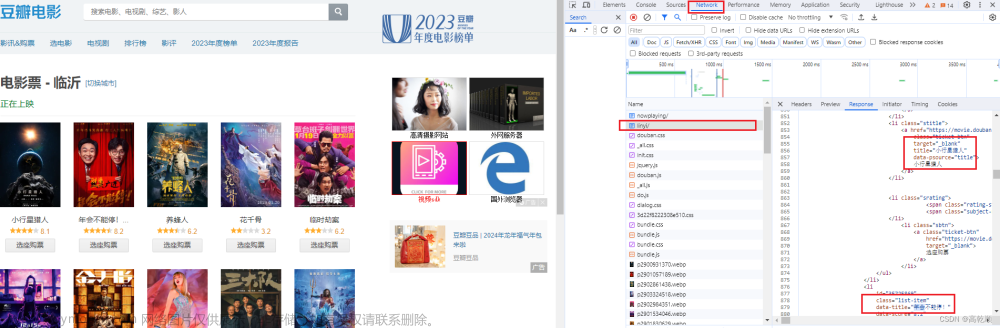
我们以东莞的Python数据分析师这个职位来做一个简单的分析,页面如下图所示:
按键盘上的F12或者点击鼠标的右键打开检查如下图:

点击进去我们可以看到如下界面:
进入之后刷新页面,打开网络,找到如下图所示的位置,打开查看页面数据:
找到之后回到标头,复制如下的url:
2.网页的下一页规律查找
查看图片不难发现,页面的换页规律依赖于page,当page等于1的时候表示当前在第一页
所以说这个规律还是比较容易发现的
三、Python相关的第三库介绍
1.Urllib的介绍
(1)urllib的简单介绍
urllib库是Python内置的HTTP请求库,只需要在代码中Import 即可使用,主要有一下四大模块
urllib.request 请求模块
urllib.error 异常处理模块
urllib.parse url解析模块
urllib.robotparser robots.txt解析模块
这个模块可以帮助我们获取到网页中的内容并保存到自己的电脑当中,使用简单方便,简单易学。
详细的使用方法参考csdn博主:urllib库万字详解
(2)在本例中的作用
本例子当中的urllib主要用到了urllib中的request方法,请求到网页中内容保存下来进行分析使用
2.Json的介绍
(1)json的简单介绍
JSON,全称是 JavaScript Object Notation,即 JavaScript对象标记法。
JSON用来存储和交换文本信息,比xml更小/更快/更易解析,易于读写,占用带宽小,网络传输速度快的特性,适用于数据量大,不要求保留原有类型的情况。。前端和后端进行数据交互,其实就是JS和Python进行数据交互!
详细请查看csdn博主:【强烈推荐】Python中JSON的基本使用(超详细)
(2)本例中的作用
在本例子中,我们使用json来下载文件,便于后续的操作
3.Jsonpath的介绍
(1)jsonpath的简单介绍
JSONPath是一种信息抽取类库,是从JSON文档中抽取指定信息的工具,提供多种语言实现版本,包括Javascript、Python、PHP和Java。
详细请阅读:JsonPath用法详解
(2)jsonpath在本例的作用
在本例子中我们使用jsonpath来查找到相关职位数据,便于后期的提取
4.Pandas的介绍
(1)pandas的简单介绍
Pandas是一个使用频率很高的第三方库,在人工智能,机器学习中也经常涉及到pandas的使用,pandas可以生成Series或者DateFram类型的数据,支持很多种方法对数据进行操作。
详细查看其它博主的文章:pandas用法-全网最详细教程
(2)pandas在本例子中的作用
pandas 在本例子中主要用来生成表格,导出相应的数据
三、代码说明
(1)第三方库导入
import urllib.request
import json
import jsonpath
import pandas as pd
#没有安装jsonpath的可以加入如下代码:!pip install jsonpath
或者在Pycharm中点击Python Packages之后进行搜索安装:
(2)设置url和headers模拟浏览器发出请求:
url = 'https://www.zhipin.com/wapi/zpgeek/search/joblist.json?scene=1&query=%E6%95%B0%E6%8D%AE%E5%88%86%E6%9E%90%E5%B8%88&city=101281600&experience=&payType=&partTime=°ree=&industry=&scale=&stage=&position=&jobType=&salary=&multiBusinessDistrict=&multiSubway=&page=page&pageSize=30'
headers = {
# :method: GET
# :path: /f.gif?__a=62982351.1679801734.1679846194.1679879251.40.6.5.25&__l=r%3Dhttps%253A%252F%252Fcn.bing.com%252F%26l%3D%252Fwww.zhipin.com%252Fweb%252Fgeek%252Fjob%253Fquery%253D%2525E6%252595%2525B0%2525E6%25258D%2525AE%2525E5%252588%252586%2525E6%25259E%252590%2525E5%2525B8%252588%2526city%253D101281600%26s%3D3%26g%3D%26friend_source%3D0%26s%3D3%26friend_source%3D0&__g=-&e=3384&r=&_=1679879382&pk=cpc_user_job&ca=geek_chat_page_entry_uid_548732951_version_275&url=https%3A%2F%2Fwww.zhipin.com%2Fweb%2Fgeek%2Fjob%3Fquery%3D%25E6%2595%25B0%25E6%258D%25AE%25E5%2588%2586%25E6%259E%2590%25E5%25B8%2588%26city%3D101281600&s=3&friend_source=0
# :scheme: https
'accept': 'image/webp,image/apng,image/svg+xml,image/*,*/*;q=0.8',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
'cookie': 'lastCity=101281600; wt2=DnRZSYfeITPomuHOIdciVLhkSe-G9fXAvrgUujmFx4Qyu9hNnbJPen11SjpFUMGJy0jMm2nS04hwdg2BoZK4Gtw~~; wbg=0; Hm_lvt_194df3105ad7148dcf2b98a91b5e727a=1679803390,1679837440,1679846192,1679879252; __zp_seo_uuid__=0bd6206f-8557-4f3d-bd30-535604382b1d; __g=-; Hm_lpvt_194df3105ad7148dcf2b98a91b5e727a=1679879389; __c=1679879251; __l=r=https%3A%2F%2Fcn.bing.com%2F&l=%2Fwww.zhipin.com%2Fweb%2Fgeek%2Fjob%3Fquery%3D%25E6%2595%25B0%25E6%258D%25AE%25E5%2588%2586%25E6%259E%2590%25E5%25B8%2588%26city%3D101281600&s=3&g=&friend_source=0&s=3&friend_source=0; __a=62982351.1679801734.1679846194.1679879251.40.6.5.25; __zp_stoken__=dc22eECNMeGR%2FQDlyNw4nAlZYbBk7fjJvGk4Naw1wKz0HFWRWXVYLa2cOeTlHBjYFJkduFjwGYTtfCCYNT28DAlxZYnx%2FO141FxNnQnMNOEoSICpTU24GQ2cJDz54H3tOZH5cdzh9C0dBTXQ%3D',
'referer': 'https://www.zhipin.com/',
'sec-ch-ua': '"Chromium";v="110", "Not A(Brand";v="24", "Microsoft Edge";v="110"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'image',
'sec-fetch-mode': 'no-cors',
'sec-fetch-site': 'same-site',
'user-agent':' Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/110.0.0.0 Safari/537.36 Edg/110.0.1587.69' }
headers的内容可以在网页的标头找到
(3)自定义请求头,打开url:
request = urllib.request.Request(url=url,headers=headers)#自定义请求头
response = urllib.request.urlopen(request)#打开url
(4)保存网页的所有数据,这里的网页使用UTF-8解码,不同的网页有不同的解码格式
content = response.read().decode('utf-8')#接收数据
with open('boss_job_list.json','w',encoding='utf-8')as f: #保存为json文件
f.write(content)
保存到的json文件如下图所示:
(5) 对数据进行解析:
obj = json.load(open('boss_job_list.json','r',encoding='utf-8'))
job_name_list = jsonpath.jsonpath(obj,'$..jobName')
job_name_boss_list = jsonpath.jsonpath(obj,'$..bossName')
job_bossTitle_list = jsonpath.jsonpath(obj,'$..bossTitle')
job_salaryDesc_list = jsonpath.jsonpath(obj,'$..salaryDesc')
job_jobLabels_list = jsonpath.jsonpath(obj,'$..jobLabels')
job_skills_list = jsonpath.jsonpath(obj,'$..skills')
job_areaDistrict_list = jsonpath.jsonpath(obj,'$..areaDistrict')
job_brandName_list = jsonpath.jsonpath(obj,'$..brandName')
job_welfareList_list = jsonpath.jsonpath(obj,'$..welfareList')
job_brandScaleName_list = jsonpath.jsonpath(obj,'$..brandScaleName')
利用pandas创建数据表格
job_data = pd.DataFrame(data=[job_name_list,job_name_boss_list,job_bossTitle_list,job_salaryDesc_list,job_jobLabels_list,job_skills_list,job_areaDistrict_list,job_brandName_list,job_welfareList_list,job_brandScaleName_list])
规范化数据格式
#对原始数据进行转置
job_data = job_data.T
#设置列名
job_data.columns = ['职位名称','HR名称','HR职位','薪资','职位要求','职位所需技能','工作地点','工司名称','职位福利','公司规模']
#设置索引
job_data.set_index('职位名称',inplace=True)
四、结束语
1.效果展示

2.代码的可移植性
由于网页的结构变化频率比较快,上述代码直接复杂到程序上可能会报错,所以每一次使用都需要根据网页的结构来编写代码
3.扩展简化代码
上述代码可可以使用第三方库来写入相应的文件格式,减少代码的数量。同时,可以修改更新代码使得代码可以爬取多页,相应的方法请读者自行查阅相关资料文章来源:https://www.toymoban.com/news/detail-778376.html
3.总结
上述代码为自己课余时间自学而来,非专业爬虫,上述代码可以提供给初学者一个简单基础的范例,这也是我写这篇文章的初衷,代码的不足或者错误之处请各位大佬斧正。文章来源地址https://www.toymoban.com/news/detail-778376.html
到了这里,关于Python网络爬虫爬取招聘数据(利用python简单零基础)可做可视化的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!