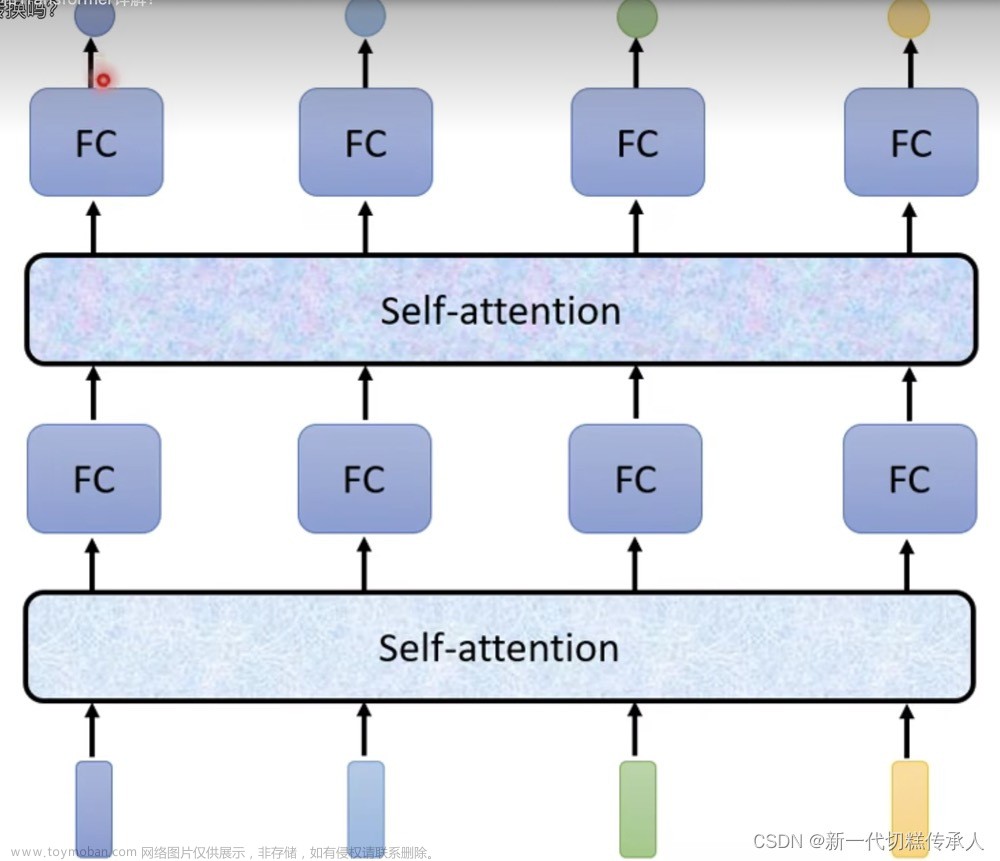
Deformable Attention(可变形注意力)首先在2020年10月初商汤研究院的《Deformable DETR: Deformable Transformers for End-to-End Object Detection》论文中提出,在2022CVPR中《Vision Transformer with Deformable Attention》提出应用了Deformable Attention(可变形自注意力)机制的通用视觉Transformer骨干网络DAT(Deformable Attention Transformer),并且在多个数据集上效果优于swin transformer。文章来源:https://www.toymoban.com/news/detail-778412.html
在BEV感知算法中,比如DETR3d,BEVFormer等,均采用的是前者中提出的Deformable Attention。具体的维度及细节分析参考博客《Deformable DETR 原理分析》及微信公众号文《搞懂 Vision Transformer 原理和代码,看这篇技术综述就够了(二)》。文章来源地址https://www.toymoban.com/news/detail-778412.html

到了这里,关于详解可变形注意力模块(Deformable Attention Module)的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!