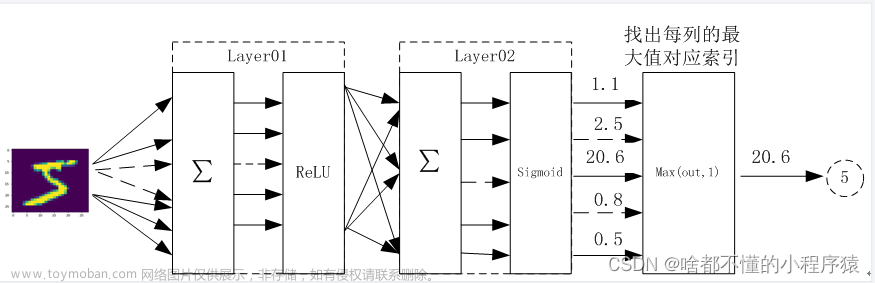
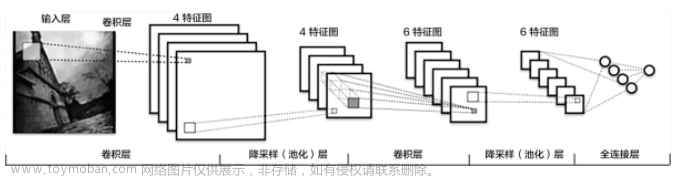
CNN卷积神经网络
一个卷积神经网络主要由以下5层组成:
- 数据输入层/ Input layer
- 卷积计算层/ CONV layer
- ReLU激励层 / ReLU layer
- 池化层 / Pooling layer
- 全连接层 / FC layer
1. 数据输入层
该层要做的处理主要是对原始图像数据进行预处理,其中包括:
- 去均值:把输入数据各个维度都中心化为0,如下图所示,其目的就是把样本的中心拉回到坐标系原点上。
- 归一化:幅度归一化到同样的范围,如下所示,即减少各维度数据取值范围的差异而带来的干扰,比如,我们有两个维度的特征A和B,A范围是0到10,而B范围是0到10000,如果直接使用这两个特征是有问题的,好的做法就是归一化,即A和B的数据都变为0到1的范围。
- PCA/白化:用PCA降维;白化是对数据各个特征轴上的幅度归一化
2. 卷积计算层
这一层就是卷积神经网络最重要的一个层次,也是“卷积神经网络”的名字来源。
在这个卷积层,有两个关键操作:
- 局部关联。每个神经元看做一个滤波器(filter)
- 窗口(receptive field)滑动, filter对局部数据计算
先介绍卷积层遇到的几个名词:
- 深度/depth(解释见下图)
- 步幅/stride (窗口一次滑动的长度)
- 填充值/zero-padding
激励层的实践经验:
①不要用sigmoid!不要用sigmoid!不要用sigmoid!
② 首先试RELU,因为快,但要小心点
③ 如果2失效,请用Leaky ReLU或者Maxout
④ 某些情况下tanh倒是有不错的结果,但是很少
参见 Geoffrey Hinton(即深度学习之父)的论文:Rectified Linear Units Improve Restricted Boltzmann Machines 墙裂推荐此论文! 现在上篇文章写的免费下载论文的方法就可以用上了。
4.池化层
池化层夹在连续的卷积层中间, 用于压缩数据和参数的量,减小过拟合。
简而言之,如果输入是图像的话,那么池化层的最主要作用就是压缩图像。
这里再展开叙述池化层的具体作用:
- 特征不变性,也就是我们在图像处理中经常提到的特征的尺度不变性,池化操作就是图像的resize,平时一张狗的图像被缩小了一倍我们还能认出这是一张狗的照片,这说明这张图像中仍保留着狗最重要的特征,我们一看就能判断图像中画的是一只狗,图像压缩时去掉的信息只是一些无关紧要的信息,而留下的信息则是具有尺度不变性的特征,是最能表达图像的特征。
- 特征降维,我们知道一幅图像含有的信息是很大的,特征也很多,但是有些信息对于我们做图像任务时没有太多用途或者有重复,我们可以把这类冗余信息去除,把最重要的特征抽取出来,这也是池化操作的一大作用。
- 在一定程度上防止过拟合,更方便优化。
-
5.全连接层
两层之间所有神经元都有权重连接,通常全连接层在卷积神经网络尾部
-
总结:卷积通过卷积核进行特征提取,池化层进行压缩,最终转为全连接层进行汇总
RNN 循环神经网络
循环神经网络(RNN)知识入门 - 知乎
比较特殊的LSTM循环神经网络
RNN背后的想法是利用顺序信息。在传统的神经网络中,我们假设所有输入(和输出)彼此独立。但对于许多任务而言,这是一个非常糟糕的想法。如果你想预测句子中的下一个单词,那你最好知道它前面有哪些单词。RNN被称为"循环",因为它们对序列的每个元素执行相同的任务,输出取决于先前的计算。考虑RNN的另一种方式是它们有一个“记忆”,它可以捕获到目前为止计算的信息。理论上,RNN可以利用任意长序列中的信息,但实际上它们仅限于回顾几个步骤(稍后将详细介绍)。
长短期记忆(LSTM)模型可用来解决稳定性和梯度消失的问题。在这个模型中,常规的神经元被存储单元代替。存储单元中管理向单元移除或添加的结构叫门限,有三种:遗忘门、输入门、输出门,门限由Sigmoid激活函数和逐点乘法运算组成。前一个时间步长的隐藏状态被送到遗忘门、输入门和输出门。在前向计算过程中,输入门学习何时激活让当前输入传入存储单元,而输出门学习何时激活让当前隐藏层状态传出存储单元。
RNN在NLP的许多任务上取得巨大成功。主要的应用领域有:
- 语言建模与生成文本(本文示例重点介绍)
- 给定一系列单词,我们想要预测给定下一单词的概率
- 能够预测下一个单词的副作用是我们得到一个生成模型,它允许我们通过从输出概率中抽样来生成新文本
- 应用模式many to one
- 机器翻译
- 机器翻译类似于语言建模,因为我们的输入是源语言中的一系列单词(例如德语),我们希望以目标语言输出一系列单词(例如英语)
- 应用模式many to many
- 语音识别
- 给定来自声波的声学信号的输入序列,我们可以预测一系列语音片段及其概率
- 应用模式many to many
- 生成图像描述
- 与卷积神经网络一起,RNN已被用作模型的一部分,以生成未标记图像的描述
- 应用模式one to many
RAN对抗神经网络
生成对抗网络(GAN) - 知乎
(GAN):GAN包含有两个模型,一个是生成模型(generative model),一个是判别模型(discriminative model)。生成模型的任务是生成看起来自然真实的、和原始数据相似的实例。判别模型的任务是判断给定的实例看起来是自然真实的还是人为伪造的(真实实例来源于数据集,伪造实例来源于生成模型)。
这可以看做一种零和游戏。论文采用类比的手法通俗理解:生成模型像“一个造假团伙,试图生产和使用假币”,而判别模型像“检测假币的警察”。生成器(generator)试图欺骗判别器(discriminator),判别器则努力不被生成器欺骗。模型经过交替优化训练,两种模型都能得到提升,但最终我们要得到的是效果提升到很高很好的生成模型(造假团伙),这个生成模型(造假团伙)所生成的产品能达到真假难分的地步。
在这个过程中,我们想象有两类人:警察和罪犯。我们看看他们的之间互相冲突的目标:
- 罪犯的目标:他的主要目标就是想出伪造货币的复杂方法,从而让警察无法区分假币和真币。
- 警察的目标:他的主要目标就是想出辨别货币的复杂方法,这样就能够区分假币和真币。
随着这个过程不断继续,警察会想出越来越复杂的技术来鉴别假币,罪犯也会想出越来越复杂的技术来伪造货币。这就是 GAN 中“对抗过程”的基本理念。
GAN 充分利用“对抗过程”训练两个神经网络,这两个网络会互相博弈直至达到一种理想的平衡状态,我们这个例子中的警察和罪犯就相当于这两个神经网络。其中一个神经网络叫做生成器网络 G(Z),它会使用输入随机噪声数据,生成和已有数据集非常接近的数据;另一个神经网络叫鉴别器网络 D(X),它会以生成的数据作为输入,尝试鉴别出哪些是生成的数据,哪些是真实数据。鉴别器的核心是实现二元分类,输出的结果是输入数据来自真实数据集(和合成数据或虚假数据相对)的概率。
本文我们用 TensorFlow 实现了一种概念验证 GAN 模型,能从非常简单的数据分布中生成数据。在你自己练习时,建议将文中代码进行如下调整:
- 对鉴别器更新之前和之后的情况进行可视化
- 改变各个层级的激活函数,看看训练和生成样本的区别
- 添加更多层以及不同类型的层,看看对训练时间和训练稳定性的影响
- 调整代码以生成数据,包含来自两个不同曲线的数据
- 调整以上代码,能够处理更复杂的数据,比如 MNIST,CIFAR-10,等等。
手把手教你理解和实现生成式对抗神经网络(GAN) - 知乎文章来源:https://www.toymoban.com/news/detail-778428.html
对抗神经网络可用用在很多领域:图片生成,老照片上色,图片内容修改等等文章来源地址https://www.toymoban.com/news/detail-778428.html
到了这里,关于python 神经网络归纳的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!