转载至我的博客 ,公众号:架构成长指南
在金融系统中,我们会跟钱打交道,而保证在高并发下场景下,对账户余额操作的一致性,是非常重要的,如果代码写的时候没考虑并发一致性,就会导致资损,本人在金融行业干了 8 年多,对这块稍微有点经验,所以这篇聊一下,如何在并发场景下,保证账户余额的一致性
1. 扣款流程是什么样的?
public void payout(long uid,var payAmount){
# 查询账户总额
var amount= "SELECT amount FROM account WHERE uid=$uid";
# 计算账户余额
var balanceAmount = amount-payAmount;
if(balanceAmount<0) throw 异常
#更新余额
update account set amount=balanceAmount where uid=$uid;
}
以上流程如果并发量非常低的情况下是没问题的,但是如果在高并发下是很容易出现问题。
2. 在高并发下会出现什么问题?
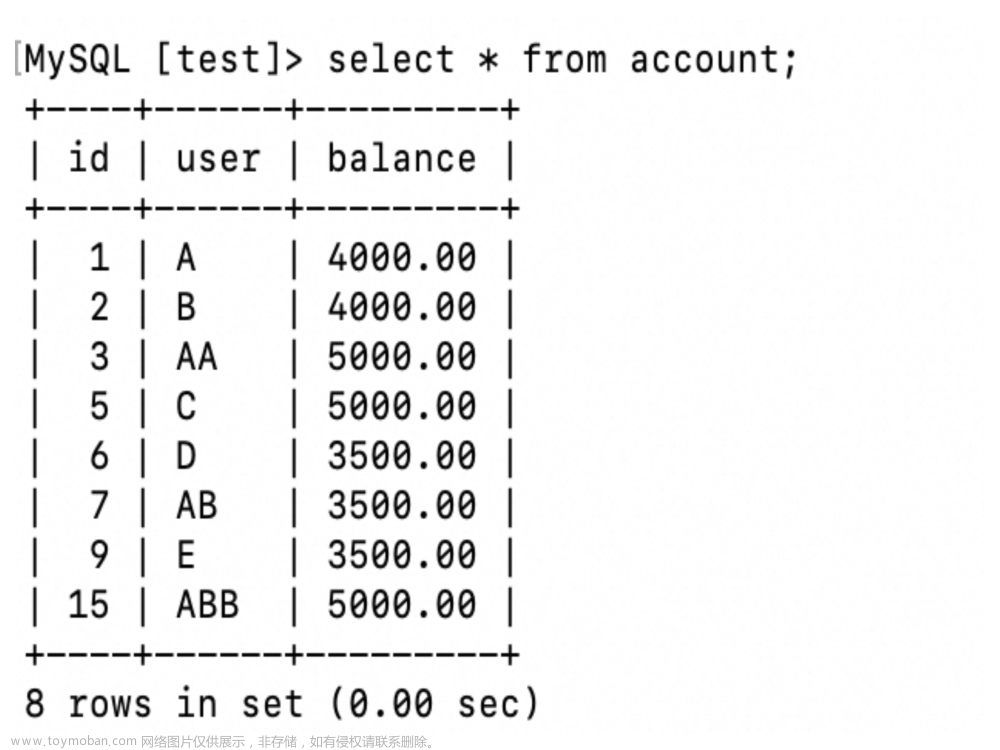
- 订单a和订单 b同一时间都查询到了,账户余额为1000
-
订单a扣款200,订单b扣款 100,都满足1000-减去扣款金额大于0
-
执行扣款,订单 a修改账户余额为800,订单 b 修改为账户余额为900
此时就出现问题了,如果订单 a 先执行更新,订单 b后执行,那么账户余额最终为900,反之为 800,都不正确,正确余额应该是700,那怎么处理呢?
3. 并发扣款怎么处理?
a. 使用悲观锁
在执行扣款时使用redis、zk或者数据库的for update对账户数据进行行级锁,使执行并发操作串型化操作,这里推荐使用for update操作,因为引用redis、zk还要考虑他们的异常情况,数据库最简单,也是目前的常规做法,本人曾经参与几大银行项目也是这种方式。
-
查询余额,在查询语句上加上
for update,但是一定要注意where 条件是唯一索引,否则会导致多行数据被锁,同时必须要开始事务,否则for update没效果,使用分布式数据库中间件还要注意,for update可能会路由到读节点上。
伪代码:public void payout(long uid,var payAmount){ try{ begin 事务 # 查询账户总额 var amount= "SELECT amount FROM account WHERE uid=$uid for update"; # 计算账户余额 var balanceAmount = amount - payAmount; if(balanceAmount<0) throw 异常 #更新余额 update account set amount=balanceAmount where uid=$uid; }catch(Exception e){ rollback 事务; 抛出异常; } commit 事务 }
b. 使用乐观锁(CAS)
乐观锁的方式也就是是CAS的方式,适合并发量不高情况,如果并发量高大概率都失败在重试,开销也不比悲观锁小,
注意这也是面试题:CAS 适合在使用场景下使用?
1. 增加版本号方式
- 在账户表增加乐观锁版本号
account(uid,amout,version)
-
查询余额时,同时查询版本号。
SELECT amount,version FROM account WHERE uid=$uid -
每次更新余额时,必须版本号相等,并且版本号每次要修改。
update account set amount=余额,version=newVersion where uid=$uid and version=$oldVersion
2. 使用原有金额值比对更新
在执行账户余额更新时,where 条件中增加第一次查出来的账户余额,即初始余额,如果在执行更新时,初始余额没变则更新成功,否则肯定是更新了,同时数据库也会返回受影响的行数,来判断是否更新成功,如果没成功就再次重试。
update account set amount=余额 where uid=$uid and amount=$oldAmount
以下是伪代码,遇到失败回滚事务并抛出异常,上层调用方法要考虑捕获异常在进行重试
public void payout(long uid,var payAmount){
try{
begin 事务
# 查询账户总额
var amount= "SELECT amount FROM account WHERE uid=$uid for update";
# 计算账户余额
var balanceAmount = amount- payAmount;
if(balanceAmount<0) throw 异常
#更新余额
int count=update account set amount=$balanceAmount where uid=$uid and amount=$amount;
###注意如果更新成功返回count为1
if(count<1){
抛出异常重试;
}
}catch(Exception e){
rollback 事务;
抛出异常;
}
commit 事务
}
具体到以上示例
订单a 执行
update account set amount=800 where uid=$uid and amount=1000;
订单b 执行
update account set amount=900 where uid=$uid and amount=1000;
以上两笔执行只有一笔能成功,因为amount 变了。
4. 使用乐观锁会不会存在aba 的问题
什么是 aba?
线程 1:获取出数据的初始值是a,如果数据仍是a的时候,修改才能成功
线程 2:将数据修改成b
线程 3:将数据修改成 a
线程 1:执行cas,发现数据还是 a,进行数据修改
上述场景,线程1在修改数据时,虽然还是a,但已经不是初始条件的a了,中间发生了a变b,b又变a,此 a 非彼 a,但是成功修改了,在有些场景下会有问题,这就是 aba
但是以上场景,对账户扣款不会出现问题,因为余额 1000 就是 1000,是相同的,举个例子,
订单a:获取出账户余额为 1000,期望余额是 1000的时候,才能修改成功。
订单b:取了 100,将余额修改成了900。
订单c:存进去了100,将余额修改成了 1000。
订单 a:检查账户余额为1000,进行扣款200,账户余额变成了800。
以上场景账户资金损失吗没有吧,不过为了避免产生误解,推荐还是使用版本号的方式!
5. 总结
以上我们讲了在高并发场景在如何保证结果一致性方式,在并发量高情况下推荐使用悲观锁的方式,如果并发量不高可以考虑使用乐观锁,推荐使用版本号方式,同时要注意幂等性与aba的问题。文章来源:https://www.toymoban.com/news/detail-778441.html
扫描下面的二维码关注我们的微信公众帐号,在微信公众帐号中回复◉加群◉即可加入到我们的技术讨论群里面共同学习。文章来源地址https://www.toymoban.com/news/detail-778441.html
到了这里,关于高并发扣款,如何保证结果一致性的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!