前面的文章:
1、 1 一个测试驱动的Spring Boot应用程序开发
2、 2 使用React构造前端应用
3、 3 试驱动的Spring Boot应用程序开发数据层示例
4、 4 向微服务架构转变
5、 5 转向事件驱动的架构
6、 6 网关和配置服务器
代码:下载
前面的系统中已经涉及几个组件生成的日志(Multiplication、Gamification、Gateway、Consul、RabbitMQ),其中某些组件可能有多个实例,很多日志输出是独立运行的,很难获得系统活动的整体视图。如果用户报告错误,很难找出哪个组件或实例出现故障。在一个屏幕上安排多个日志窗口会有用,但当微服务实例数量增加时,这就不是那么容易解决的了。
要很好地维护像微服务架构这样的分布式系统,需要一个中心位置,在那里可以访问所有聚合日志并进行搜索。
日志聚合模式
通常是将所有的日志输出从应用程序发送到另一个组件,该组件将它们聚合在一起,另外,希望日志能保留一段时间,因此,需要数据存储功能。理想情况下,应该能够浏览这些日志,搜索并过滤每个微服务、实例、类等信息,为此,许多工具提供了一个用户界面,用于连接到聚合日志存储。如图所示:
实现集中式日志记录时,最好的做法是应用程序逻辑不逻辑此模式,服务应该只使用公共接口来输出消息,将这些日志传送到中央聚合器的日志记录代理独立工作,捕获应用程序产生的输出。
现在有这种模式的多种实现,包括免费和付费的解决方案,其中最受欢迎的是ELK堆栈:Elasticsearch、Logstash和Kibana。
随着时间的推移,建立ELK堆栈已经越来越容易,但仍然不是一项容易的任务,这里不使用ELK实现,就不做介绍了。
日志集中化的简单解决方案
要实现集中式日志处理,需要建立一个新的微服务,来汇总来自Spring Boot应用程序的日志,为了简单起见,不用数据层来保存日志,只接收来自其他服务的日志,并输出到标准输出中。这种方案有助于实现分布式跟踪。
要实现日志输出,需要使用已有的工具RabbitMQ,要捕获应用程序中的每个日志记录行并以RabbitMQ消息的形式发送,因为Spring Boot一直使用Logback,不需要修改应用程序中的代码,就可以由外部配置文件驱动。
在Logback中,将日志行写入特定目标的逻辑部分称为附加程序,此日志记录库包含一些内置的附加程序,用于将消息输出到控制台(ConsoleAppender)或文件(FileAppender和RollingFileAppender)。不需要配置,因为Spring Boot在其依赖项中包含了一些默认的Logback配置,还设置了输出的消息格式。
Spring AMQP提供了一个Logback AMQP日志记录附加程序,可以满足其需要,该附加程序接收每一行日志并为RabbitMQ中的给定交换生成一条消息,其中包含格式和其他一些自定义的选项。
首先准备要添加的Logback配置。Spring Boot可以在应用程序资源文件夹(src/main/resources)中创建一个logback-spring.xml文件来扩展默认值,该文件将在应用程序初始化时自动获取。AMQP附加程序文档列出了所有参数及其含义:
- applicationId:Application ID — 应用ID - 如果 pattern 包括 %X{applicationId},则添加到 routing key 中。将其设置为应用程序名称,便于在汇总日志时区分源。
- host:连接到的RabbitMQ主机。由于环境的不同,将该值连接到spring.rabbitmq.host,Spring可以使用springProperty标签来设置。应该给Logback的host属性起一个名字RabbitMQHost,并使用语法${rabbitMQHost:-localhost}来使用该属性值(如果以设置)或使用默认的localhost(默认使用:-分隔设置)。
- routingKeyPattern:Logging 子系统的 pattern format,用于生成 routing key。如果要在消费者端进行过滤,需要将其设置为applicationId和level(用%p表示)的串联,以提供更大的灵活性。
- exchangeName:要发布日志事件的 exchange 的名称。默认情况下,会是一个主题交换,可定义为logs.topic。
- declareExchange:是否在这个 appender 启动时声明配置的 exchange。如果尚未创建交换,则设为true。
- durable:当 declareExchange 为 true 时,durable 标志被设置为这个值。以便交换在服务器重新启动后继续存在。
- deliveryMode:设为 PERSISTENT,以便存储日志消息,直到聚合器使用为止。PERSISTENT 或 NON_PERSISTENT,以确定 RabbitMQ 是否应该持久化消息。
- generateId:用于确定 messageId 属性是否被设置为唯一值。设为true,每条消息有唯一标识。
- charset:将 String 转换为 byte[] 时使用的字符集。默认:null(使用系统默认字符集)。如果当前平台不支持该字符集,将退回到使用系统字符集。最好设为UTF-8,以确保使用相同的编码。
Gamification项目的logback-spring.xml内容如下:
<configuration>
<include resource="org/springframework/boot/logging/logback/defaults.xml" />
<include resource="org/springframework/boot/logging/logback/console-appender.xml" />
<springProperty scope="context" name="rabbitMQHost" source="spring.rabbitmq.host"/>
<appender name="AMQP"
class="org.springframework.amqp.rabbit.logback.AmqpAppender">
<layout>
<pattern>%d{HH:mm:ss.SSS} [%t] %logger{36} - %msg</pattern>
</layout>
<applicationId>gamification</applicationId>
<host>${rabbitMQHost:-localhost}</host>
<routingKeyPattern>%property{applicationId}.%p</routingKeyPattern>
<exchangeName>logs.topic</exchangeName>
<generateId>true</generateId>
<charset>UTF-8</charset>
<durable>true</durable>
<declareExchange>true</declareExchange>
<deliveryMode>PERSISTENT</deliveryMode>
</appender>
<root level="INFO">
<appender-ref ref="CONSOLE" />
<appender-ref ref="AMQP" />
</root>
</configuration>
从中可以看到如何将自定义模式添加到附加程序中的,这就可以对消息进行编码,不仅包括消息(%msg),还包括一些额外的信息,如时间(%d{hh:mm:ss.SSS})、线程名([%t])和记录器类(%logger{36})等。文件最后配置根记录器(默认记录器),使用某个包含的文件中定义的CONSOLE附加程序和新定义的AMQP附加程序。
现在需要在其他项目中添加类似的文件,并修改相应的applicationId值。
除了设置日志生成器外,还可以将附加程序用于连接到RabbitMQ的类的日志级别调整为WARN,可避免当RabbitMQ服务器不可用时生成数百条日志,可添加到application配置中:
logging.level.org.springframework.amqp.rabbit.connection.CachingConnectionFactory=WARN
启动应用程序时,日志不仅输出到控制台,还在RabbitMQ服务器的logs.topic交换中生成消息,可在RabbitMQ的Web界面进行验证,如图所示:
使用日志并输出
已经将所有日志发布到交换了,现在就来构建一个新的微服务,来使用这些消息并将之输出。
创建一个新的项目:logs,使用Maven和Jdk21,支持依赖:RabbitMQ、Spring Web、Validation、Spring Boot Actuator、Lombok、Consul Configuration等,不需要服务发现,因此不添加Consul Discovery,如图所示:
打开pom.xml,结果如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>3.2.1</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>cn.zhangjuli</groupId>
<artifactId>logs</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>logs</name>
<description>logs</description>
<properties>
<java.version>21</java.version>
<spring-cloud.version>2023.0.0</spring-cloud.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-validation</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-consul-config</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.springframework.amqp</groupId>
<artifactId>spring-rabbit-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${spring-cloud.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
<configuration>
<excludes>
<exclude>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>
在src/main/resources/application.properties文件中配置如下:
spring.application.name=logs
server.port=8580
spring.config.import=consul:
spring.cloud.consul.config.prefix=config
spring.cloud.consul.config.format=yaml
spring.cloud.consul.config.default-context=defaults
spring.cloud.consul.config.data-key=application.yml
现在需要一个Spring Boot配置类来声明交换、要使用的消息队列,以及将队列附加到主题交换的绑定对象,并使用绑定键模式来使用所有这些对象(#),AMQPConfiguration类如下:
package cn.zhangjuli.logs.configuration;
import org.springframework.amqp.core.*;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* @author Juli Zhang, <a href="mailto:zhjl@lut.edu.cn">Contact me</a> <br>
*/
@Configuration
public class AMQPConfiguration {
@Bean
public TopicExchange logsExchange() {
return ExchangeBuilder.topicExchange("logs.topic")
.durable(true)
.build();
}
@Bean
public Queue logsQueue() {
return QueueBuilder.durable("logs.queue").build();
}
@Bean
public Binding logsBinding(final Queue logsQueue,
final TopicExchange logsExchange) {
return BindingBuilder.bind(logsQueue)
.to(logsExchange).with("#");
}
}
下面使用@RabbitListener注解创建一个简单服务,使用相应的log.info()、log.error()或log.warn()将作为RabbitMQ消息头传递的接收消息的日志记录级别映射到Logs微服务中的日志记录级别。注意,这里使用@Header注解将AMQP消息头提取为方法参数,还使用日志记录Marker将应用程序名称(appId)添加到日志行,而不必将其作为消息的一部分进行串联,这是SLF4J标准的灵活用法,可将上下文值添加到日志中。接收RabbitMQ日志消息的消费者类如下:
package cn.zhangjuli.logs.consumer;
import lombok.extern.slf4j.Slf4j;
import org.slf4j.Marker;
import org.slf4j.MarkerFactory;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.stereotype.Service;
/**
* @author Juli Zhang, <a href="mailto:zhjl@lut.edu.cn">Contact me</a> <br>
*/
@Slf4j
@Service
public class LogsConsumer {
@RabbitListener(queues = "logs.queue")
public void log(final String msg,
@Header("level") String level,
@Header("amqp_appId") String appId) {
Marker marker = MarkerFactory.getMarker(appId);
switch (level) {
case "INFO" -> log.info(marker, msg);
case "ERROR" -> log.error(marker, msg);
case "WARN" -> log.warn(marker, msg);
}
}
}
最后,定义日志输出,因为要聚合来自不同服务的多个日志,相关属性是应用程序名称,logback-spring.xml如下:
<configuration>
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<layout class="ch.qos.logback.classic.PatternLayout">
<Pattern>
[%-15marker] %highlight(%-5level) %msg%n
</Pattern>
</layout>
</appender>
<root level="INFO">
<appender-ref ref="CONSOLE" />
</root>
</configuration>
重新启动整个系统,就可以在Logs控制台看到所有日志信息,例如:
[multiplication ] INFO 17:30:57.018 [http-nio-10080-exec-8] c.z.m.challenge.ChallengeServiceImpl - attempt: ChallengeAttempt(id=352, user=User(id=202, alias=noise7), factorA=50, factorB=60, resultAttempt=3000, correct=true)
[gamification ] INFO 17:30:57.046 [org.springframework.amqp.rabbit.RabbitListenerEndpointContainer#0-1] c.z.g.game.GameEventHandler - 已接收到成功挑战事件:352
[gamification ] INFO 17:30:57.101 [org.springframework.amqp.rabbit.RabbitListenerEndpointContainer#0-1] c.z.g.game.GameServiceImpl - 用户 noise7 的尝试 352 得分 10
[gamification ] INFO 17:31:01.856 [http-nio-8081-exec-10] c.z.g.game.LeaderBoardController - 查询排行榜
[gamification ] INFO 17:31:01.856 [http-nio-8081-exec-6] c.z.g.game.LeaderBoardController - 查询排行榜
这个简单的日志聚合器没有花费多少时间,现在可以在同一源中搜索日志,并看到所有服务中近乎实时的输出流。其过程如图所示:
分布式跟踪
将所有日志放在一个位置能提高可观察性,但不具备可追溯性,在微服务之间了解并发用户和事件链的情况就是一个难题,尤其是当事件链具有触发了相同操作的多个事件类型分支时,更是困难。
为解决此问题,需要关联同一进程链中的所有操作和事件。一种简单的方法是在用于处理不同操作的所有HTTP调用、RabbitMQ消息和Java线程中注入相同的标识符,然后,可在所有相关日志中输出此标识符。
在系统中使用用户标识符,如果将来所有功能都将围绕用户操作而构建,就可以在每个事件和调用中传播一个userId字段,然后,将其记录在不同的服务中,以便将日志与特定用户相关联,这会改善可追溯性。但是,也可能在短时间内收到来自同一用户的多个操作,例如,两次尝试在一秒内解决乘法问题,这些操作分散在实例中。这种情况下,很难区分微服务的各个流。理想情况下,每种操作都应该有一个唯一的标识符,该标识符是在链的起点生成的。此外,最好是透明地传播,而不必在所有服务中显式地对其可追溯性问题进行建模。
在Spring中,实现分布式跟踪的工具是Sleuth。
Spring Cloud Sleuth
Sleuth是Spring Cloud系列的一部分,使用Brave库来实现分布式跟踪,通过关联span的工作单元在不同组件之间构建跟踪。例如,一个span正在检查Multiplication微服务中的尝试,而另一个span正在基于RabbitMQ事件添加分数和徽章。每个span都有一个不同的唯一标识符,但都属于同一个跟踪,因此具有相同的跟踪标识符。此外,每个span都链接到父级,而根级除外,根级是原始操作。如图所示:
在更高级的系统中,可能会有复杂的跟踪结构,其中多个span具有相同的父级,如图所示:
为了透明地注入这些值,Sleuth使用SLF4J的映射诊断上下文(MDC)对象,该对象是一个日志记录上下文,其生命周期仅限于当前线程,还可以在上下文中注入自定义字段,可传播并在日志中使用这些值。
Spring Boot在Sleuth中自动配置了一些内置的拦截器,用于自动检查和修改HTTP调用和RabbitMQ消息,还集成了Kafka、gRPC和其他通信接口。拦截器的工作方式类似:对于传入的通信,检查是否在调用或消息中添加了跟踪标头,并将其放入MDC中;当作为客户端进行调用或发布数据时,拦截器会从MDC中获取这些字段并将标头添加到请求或消息中。
Sleuth有时与Zipkin结合使用,可以跟踪采样来测量每个span中以及整个链中所花费的时间。这些数据可以发送到Zipkin服务器,该服务器提供一个UI,可查看跟踪层次结构以及每个服务完成其工作所需的时间。这里不会使用Zipkin,因为其不适用具有trace和span标识符的集中式日志记录系统。
实现分布式跟踪
Spring Cloud Sleuth为REST API和RabbitMQ消息提供了拦截器,Spring Boot进行自动配置,因此,实现分布式跟踪并不困难。这里使用Zipkin来进行跟踪。
首先,在Multiplication、Gamification、Gateway、Logs中添加Spring Cloud Sleuth启动器,如下所示:
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-tracing-bridge-brave</artifactId>
</dependency>
<dependency>
<groupId>io.zipkin.reporter2</groupId>
<artifactId>zipkin-reporter-brave</artifactId>
</dependency>
只有添加了对应的依赖项,才会将trace和span标识符注入每个受支持的通信通道和MDC对象中,默认的Spring Boot日志记录模式也会自动调整,用于在日志中输出trace和span值。
为了使日志更详细并查看trace标识符,在ChallengeAttemptController中添加一条日志信息,以便每次用户发送尝试时输出一条消息,如下所示:
package cn.zhangjuli.multiplication.challenge;
import jakarta.validation.Valid;
import lombok.RequiredArgsConstructor;
import lombok.extern.slf4j.Slf4j;
import org.springframework.http.ResponseEntity;
import org.springframework.web.bind.annotation.*;
import java.util.List;
/**
* @author Juli Zhang, <a href="mailto:zhjl@lut.edu.cn">Contact me</a> <br>
*/
@Slf4j
@RequiredArgsConstructor
@RestController
@RequestMapping("/attempts")
public class ChallengeAttemptController {
private final ChallengeService challengeService;
@PostMapping
ResponseEntity<ChallengeAttempt> postResult(@RequestBody @Valid ChallengeAttemptDTO challengeAttemptDTO) {
log.info("从{}收到新的尝试。", challengeAttemptDTO.getUserAlias());
return ResponseEntity.ok(challengeService.verifyAttempt(challengeAttemptDTO));
}
@GetMapping
ResponseEntity<List<ChallengeAttempt>> getStatistics(@RequestParam String alias) {
return ResponseEntity.ok(challengeService.getStatisticsForUser(alias));
}
}
另外,还想在集中式日志中包含trace和parent标识符,要将来自MDC上下文(由Sleuth使用Brave注入)中的属性X-B3-TraceId和X-B3-SpanId手动添加到Logs项目的logback-spring.xml中。这些标头是OpenZipkin的B3 Propagation规范的一部分,由Sleuth的拦截器包含在MDC中,代码如下:
<configuration>
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
<layout class="ch.qos.logback.classic.PatternLayout">
<Pattern>
[%70marker] %highlight(%-5level) %msg%n
</Pattern>
</layout>
</appender>
<root level="INFO">
<appender-ref ref="CONSOLE" />
</root>
</configuration>
另外,修改LogsConsumer 类,让日志信息能够显示traceId和spanId,以便追踪,如下所示:
package cn.zhangjuli.logs.consumer;
import lombok.extern.slf4j.Slf4j;
import org.slf4j.Marker;
import org.slf4j.MarkerFactory;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.stereotype.Service;
/**
* @author Juli Zhang, <a href="mailto:zhjl@lut.edu.cn">Contact me</a> <br>
*/
@Slf4j
@Service
public class LogsConsumer {
@RabbitListener(queues = "logs.queue")
public void log(final String msg,
@Header("level") String level,
@Header("amqp_appId") String appId) {
Marker marker = MarkerFactory.getMarker(appId);
switch (level) {
case "INFO" -> log.info(marker, msg);
case "ERROR" -> log.error(marker, msg);
case "WARN" -> log.warn(marker, msg);
}
}
}
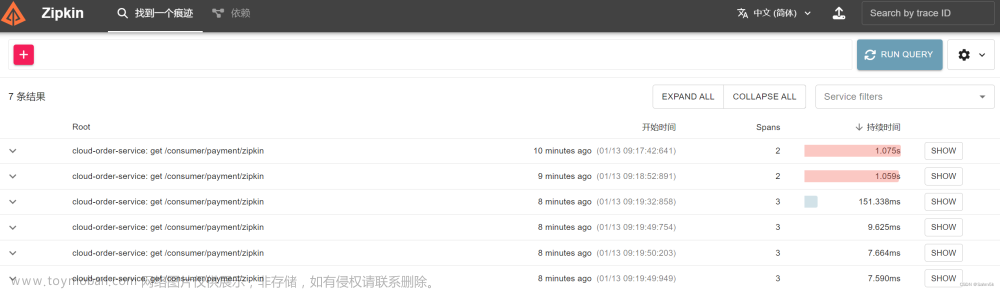
重启服务后,就会发挥作用,当然,还需要安装Zipkin服务器,可使用docker容器,命令很简单:docker run -d -p 9411:9411 openzipkin/zipkin,可以看到Multiplication和Gamification的日志,带有trace标识符,如下所示:
2023-12-26T11:37:37.693+08:00 INFO 44448 --- [multiplication] [io-10080-exec-9] [658a4a8152b5ca6ff46e57bc2c704440-deb6e42026ec20e9] c.z.m.c.ChallengeAttemptController : 从noise7收到新的尝试。
2023-12-26T11:37:37.700+08:00 INFO 44448 --- [multiplication] [io-10080-exec-9] [658a4a8152b5ca6ff46e57bc2c704440-deb6e42026ec20e9] c.z.m.challenge.ChallengeServiceImpl : attempt: ChallengeAttempt(id=457, user=User(id=202, alias=noise7), factorA=50, factorB=60, resultAttempt=3000, correct=true)
2023-12-26T11:37:38.390+08:00 INFO 44448 --- [multiplication] [io-10080-exec-8] [658a4a823f424e031efe5eb3dec5988c-81180d75a911d673] c.z.multiplication.user.UserController : 解析用户别名:[154, 202, 3, 1, 102, 153, 152]
2023-12-26T11:37:43.448+08:00 INFO 44448 --- [multiplication] [io-10080-exec-4] [658a4a87a383b6ed58ed38f84f4d56f3-d05b566e3550cfdb] c.z.multiplication.user.UserController : 解析用户别名:[154, 202, 3, 1, 102, 153, 152]
将所有日志连同traceId和spanId输出到更复杂的集中式日志工具(如ELK)时,效果更好,可以使用这些标识符来执行过滤后的文本搜索。
小结
文章介绍了日志聚合模式,以解决微服务实施过程中面临的问题,每个微服务都有日志输出,不便于了解整个系统的状态,通过日志集中化解决方案,将所有日志引导到一个中央位置,还可以在其中看到单个进程运行的完整轨迹,可使用Sleuth、Zipkin实现分布式跟踪,以便发现存在的问题。文章来源:https://www.toymoban.com/news/detail-778694.html
后续文章:
容器化微服务文章来源地址https://www.toymoban.com/news/detail-778694.html
到了这里,关于7 集中式日志和分布式跟踪的文章就介绍完了。如果您还想了解更多内容,请在右上角搜索TOY模板网以前的文章或继续浏览下面的相关文章,希望大家以后多多支持TOY模板网!
![[设计模式Java实现附plantuml源码~创建型] 集中式工厂的实现~简单工厂模式](https://imgs.yssmx.com/Uploads/2024/01/803959-1.png)